
Gemma 3n یک مدل هوش مصنوعی مولد است که برای استفاده در دستگاه های روزمره مانند تلفن، لپ تاپ و تبلت بهینه شده است. این مدل شامل نوآوریهایی در پردازش پارامترهای کارآمد، از جمله ذخیرهسازی پارامتر در هر لایه (PLE) و معماری مدل MatFormer است که انعطافپذیری را برای کاهش نیازهای محاسباتی و حافظه فراهم میکند. این مدلها دارای مدیریت ورودی صوتی و همچنین دادههای متنی و تصویری هستند.
Gemma 3n دارای ویژگی های کلیدی زیر است:
- ورودی صوتی : پردازش داده های صدا برای تشخیص گفتار، ترجمه و تجزیه و تحلیل داده های صوتی. بیشتر بدانید
- ورودی بصری و متن : قابلیتهای چندوجهی به شما امکان میدهند بینایی، صدا و متن را مدیریت کنید تا به شما در درک و تجزیه و تحلیل دنیای اطرافتان کمک کند. بیشتر بدانید
- رمزگذار بینایی: انکودر MobileNet-V5 با کارایی بالا سرعت و دقت پردازش داده های بصری را به میزان قابل توجهی بهبود می بخشد. بیشتر بدانید
- ذخیره سازی PLE : پارامترهای تعبیه شده در هر لایه (PLE) موجود در این مدل ها را می توان در حافظه داخلی سریع و برای کاهش هزینه های اجرای حافظه مدل کش کرد. بیشتر بدانید
- معماری MatFormer: معماری ترانسفورماتور Matryoshka امکان فعال سازی انتخابی پارامترهای مدل را در هر درخواست برای کاهش هزینه محاسبه و زمان پاسخ می دهد. بیشتر بدانید
- بارگذاری پارامتر مشروط: برای کاهش تعداد کل پارامترهای بارگذاری شده و صرفه جویی در منابع حافظه، از بارگذاری پارامترهای بینایی و صدا در مدل دور بزنید. بیشتر بدانید
- پشتیبانی از زبان گسترده : قابلیت های زبانی گسترده، آموزش دیده در بیش از 140 زبان.
- زمینه توکن 32K : زمینه ورودی قابل توجهی برای تجزیه و تحلیل داده ها و رسیدگی به وظایف پردازشی.
Gemma 3n را امتحان کنید Get it on Kaggle Get it on Hugging Face
مانند سایر مدلهای Gemma، Gemma 3n با وزنههای باز و دارای مجوز برای استفاده تجاری مسئولانه ارائه میشود و به شما امکان میدهد آن را در پروژهها و برنامههای خود تنظیم و اجرا کنید.
پارامترهای مدل و پارامترهای موثر
مدلهای Gemma 3n با تعداد پارامترهایی مانند E2B و E4B فهرست شدهاند که از تعداد کل پارامترهای موجود در مدلها کمتر است. پیشوند E نشان می دهد که این مدل ها می توانند با مجموعه ای از پارامترهای موثر کار کنند. این عملکرد پارامتر کاهش یافته را می توان با استفاده از فناوری پارامتر انعطاف پذیر تعبیه شده در مدل های Gemma 3n برای کمک به اجرای کارآمد در دستگاه های با منابع پایین تر به دست آورد.
پارامترها در مدل های Gemma 3n به 4 گروه اصلی تقسیم می شوند: پارامترهای متن، بصری، صوتی و تعبیه در هر لایه (PLE). با اجرای استاندارد مدل E2B، بیش از 5 میلیارد پارامتر هنگام اجرای مدل بارگذاری می شود. با این حال، با استفاده از تکنیکهای پرش پارامتر و ذخیرهسازی PLE، این مدل میتواند با بار حافظه موثر کمتر از 2 میلیارد (1.91B) پارامتر، همانطور که در شکل 1 نشان داده شده است، کار کند.
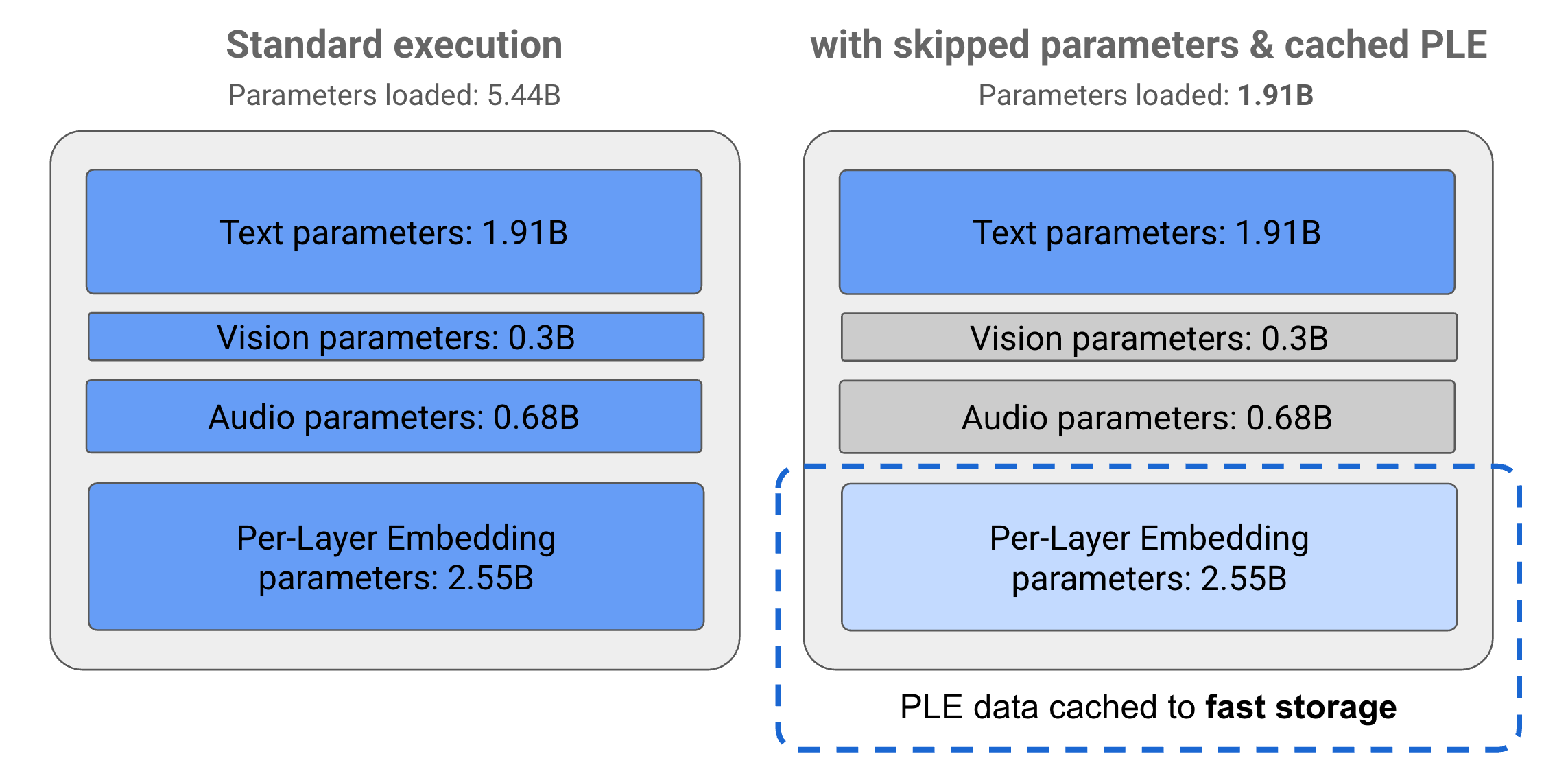
شکل 1. پارامترهای مدل Gemma 3n E2B که در اجرای استاندارد در مقابل بار پارامتر کمتر با استفاده از روشهای ذخیرهسازی PLE و پرش پارامتر اجرا میشوند.
با استفاده از این تکنیکهای تخلیه پارامتر و فعالسازی انتخابی، میتوانید مدل را با مجموعهای از پارامترهای بسیار ناچیز اجرا کنید یا پارامترهای اضافی را برای مدیریت انواع دادههای دیگر مانند دیداری و صوتی فعال کنید. این ویژگیها شما را قادر میسازد تا بر اساس قابلیتهای دستگاه یا الزامات کار، عملکرد مدل را افزایش دهید یا قابلیتهای پایینتر را افزایش دهید. بخشهای زیر بیشتر در مورد تکنیکهای کارآمد پارامتر موجود در مدلهای Gemma 3n توضیح میدهند.
ذخیره سازی PLE
مدلهای Gemma 3n شامل پارامترهای Per-Layer Embedding (PLE) هستند که در طول اجرای مدل برای ایجاد دادههایی استفاده میشوند که عملکرد هر لایه مدل را افزایش میدهد. دادههای PLE را میتوان بهطور جداگانه، خارج از حافظه عملیاتی مدل تولید کرد، در حافظه پنهان ذخیرهسازی سریع ذخیره کرد و سپس با اجرای هر لایه به فرآیند استنتاج مدل اضافه کرد. این رویکرد به پارامترهای PLE اجازه می دهد تا از فضای حافظه مدل خارج شوند و مصرف منابع را کاهش دهد و در عین حال کیفیت پاسخ مدل را بهبود بخشد.
معماری MatFormer
مدلهای Gemma 3n از معماری مدل Matryoshka Transformer یا MatFormer استفاده میکنند که شامل مدلهای تودرتو و کوچکتر در یک مدل بزرگتر است. مدلهای فرعی تو در تو را میتوان برای استنتاج بدون فعال کردن پارامترهای مدلهای محصور در هنگام پاسخ به درخواستها استفاده کرد. این توانایی برای اجرای مدلهای کوچکتر و هستهای در یک مدل MatFormer میتواند هزینه محاسباتی، و زمان پاسخگویی و ردپای انرژی را برای مدل کاهش دهد. در مورد Gemma 3n، مدل E4B شامل پارامترهای مدل E2B است. این معماری همچنین به شما امکان می دهد پارامترها را انتخاب کرده و مدل ها را در اندازه های متوسط بین 2B و 4B مونتاژ کنید. برای جزئیات بیشتر در مورد این رویکرد، مقاله تحقیقاتی MatFormer را ببینید. سعی کنید از تکنیک های MatFormer برای کاهش اندازه یک مدل Gemma 3n با راهنمای MatFormer Lab استفاده کنید.
بارگذاری پارامتر مشروط
مشابه پارامترهای PLE، میتوانید از بارگذاری برخی پارامترها در حافظه مانند پارامترهای صوتی یا بصری در مدل Gemma 3n صرفنظر کنید تا بار حافظه کاهش یابد. اگر دستگاه منابع مورد نیاز را داشته باشد، می توان این پارامترها را به صورت پویا در زمان اجرا بارگذاری کرد. به طور کلی، پرش پارامتر میتواند حافظه عملیاتی مورد نیاز را برای مدل Gemma 3n کاهش دهد، و امکان اجرا در طیف وسیعتری از دستگاهها را فراهم میکند و به توسعهدهندگان اجازه میدهد تا کارایی منابع را برای کارهای کمتر افزایش دهند.
برای شروع ساختن آماده اید؟ با مدل های Gemma شروع کنید !