
Questa guida fornisce istruzioni per convertire i modelli Gemma nel formato Hugging Face Safetensors (.safetensors) nel formato di file dell'attività MediaPipe (.task). Questa conversione è essenziale per il deployment di modelli Gemma preaddestrati o ottimizzati per l'inferenza on-device su Android e iOS utilizzando l'API MediaPipe LLM Inference e il runtime LiteRT.
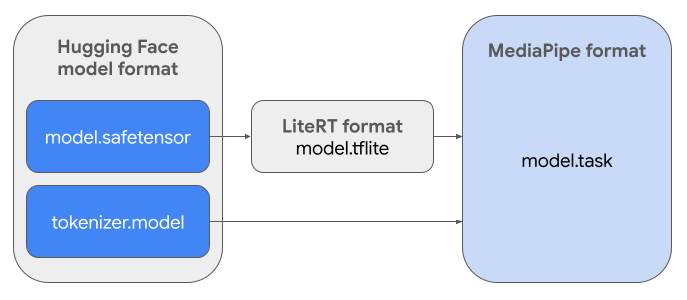
Per creare il pacchetto di attività richiesto (.task), utilizzerai
LiteRT Torch. Questo strumento esporta i modelli PyTorch in modelli LiteRT (.tflite) con più firme, compatibili con l'API MediaPipe LLM Inference e adatti all'esecuzione su backend CPU in applicazioni mobile.
Il file .task finale è un pacchetto autonomo richiesto da MediaPipe,
che raggruppa il modello LiteRT, il modello di tokenizzazione e i metadati essenziali. Questo
bundle è necessario perché il tokenizer (che converte i prompt di testo in
embedding di token per il modello) deve essere incluso nel modello LiteRT per
consentire l'inferenza end-to-end.
Ecco una suddivisione passo passo della procedura:
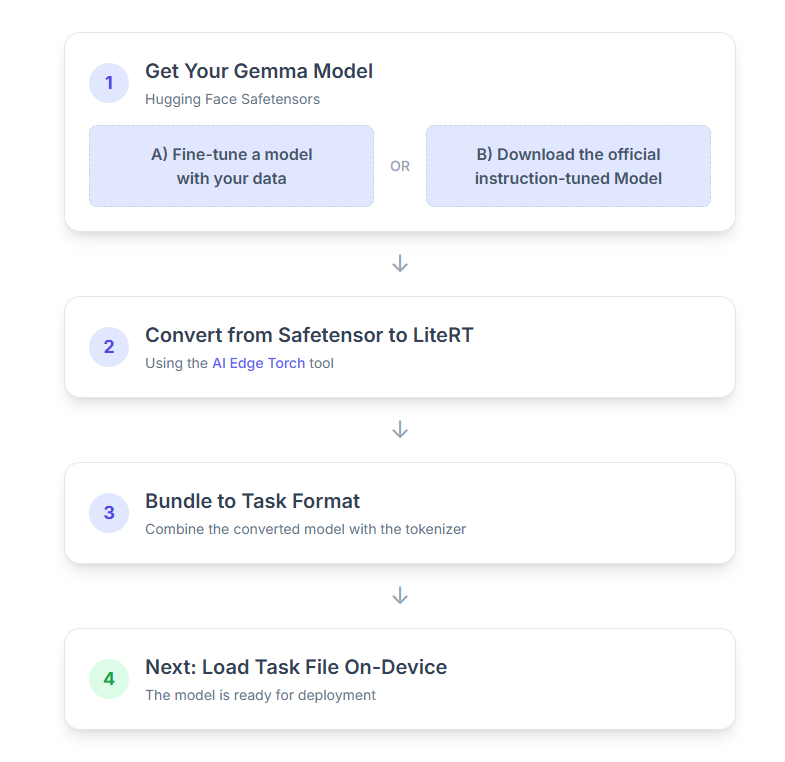
1. Recuperare il modello Gemma
Hai due opzioni per iniziare.
Opzione A. Utilizzare un modello ottimizzato esistente
Se hai preparato un modello Gemma ottimizzato, vai al passaggio successivo.
Opzione B. Scaricare il modello ufficiale ottimizzato per le istruzioni
Se hai bisogno di un modello, puoi scaricare una versione di Gemma ottimizzata per le istruzioni da Hugging Face Hub.
Configura gli strumenti necessari:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
Scarica il modello:
I modelli su Hugging Face Hub sono identificati da un ID modello, in genere nel formato <organization_or_username>/<model_name>. Ad esempio, per scaricare il modello
ufficiale Gemma 3 270M ottimizzato per le istruzioni, utilizza:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. Converti e quantizza il modello in LiteRT
Configura un ambiente virtuale Python e installa l'ultima release stabile del pacchetto LiteRT Torch:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
Utilizza il seguente script per convertire Safetensor nel modello LiteRT.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
Tieni presente che questa procedura richiede tempo e dipende dalla velocità di elaborazione del computer. A titolo di riferimento, su una CPU a 8 core del 2025, un modello da 270 milioni di parametri richiede più di 5-10 minuti, mentre un modello da 1 miliardo di parametri può richiedere circa 10-30 minuti.
L'output finale, un modello LiteRT, verrà salvato nella posizione
OUTPUT_DIR_PATH specificata.
Ottimizza i seguenti valori in base ai vincoli di memoria e prestazioni del dispositivo di destinazione.
kv_cache_max_len: definisce la dimensione totale allocata della memoria di lavoro del modello (la cache KV). Questa capacità è un limite rigido e deve essere sufficiente per memorizzare la somma combinata dei token del prompt (il precompilamento) e di tutti i token generati successivamente (la decodifica).prefill_seq_len: specifica il conteggio dei token del prompt di input per la suddivisione in blocchi del precompilamento. Quando elabora il prompt di input utilizzando la suddivisione in blocchi del riempimento automatico, l'intera sequenza (ad es. 50.000 token) non viene calcolato contemporaneamente, ma suddiviso in segmenti gestibili (ad es. blocchi di 2048 token) che vengono caricati in sequenza nella cache per evitare un errore di memoria insufficiente.quantize: stringa per gli schemi di quantizzazione selezionati. Di seguito è riportato l'elenco delle ricette di quantizzazione disponibili per Gemma 3.none: nessuna quantizzazionefp16: pesi FP16, attivazioni FP32 e calcolo in virgola mobile per tutte le operazionidynamic_int8: attivazioni FP32, pesi INT8 e calcolo di numeri interiweight_only_int8: attivazioni FP32, pesi INT8 e calcolo in virgola mobile
3. Creare un pacchetto di attività da LiteRT e dal tokenizer
Configura un ambiente virtuale Python e installa il pacchetto Python mediapipe:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
Utilizza la libreria genai.bundler per raggruppare il modello:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
La funzione bundler.create_bundle crea un file .task che contiene tutte
le informazioni necessarie per eseguire il modello.
4. Inferenza con MediaPipe su Android
Inizializza l'attività con le opzioni di configurazione di base:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
Utilizza il metodo generateResponse() per generare una risposta di testo.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
Per trasmettere in streaming la risposta, utilizza il metodo generateResponseAsync().
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
Per saperne di più, consulta la guida all'inferenza LLM per Android.
Passaggi successivi
Crea ed esplora di più con i modelli Gemma: