
|
|
|
|
|
 Visualizza il codice sorgente su GitHub Visualizza il codice sorgente su GitHub
|
Questa guida ti illustra come eseguire il fine-tuning di Gemma su un set di dati NPC di un gioco mobile utilizzando Transformers e TRL di Hugging Face. Scoprirai:
- Configura l'ambiente di sviluppo
- Preparare il set di dati di perfezionamento
- Ottimizzazione completa del modello Gemma utilizzando TRL e SFTTrainer
- Test dell'inferenza del modello e dei controlli dell'atmosfera
Configura l'ambiente di sviluppo
Il primo passaggio consiste nell'installare le librerie Hugging Face, tra cui TRL e i set di dati per ottimizzare il modello aperto, incluse diverse tecniche di RLHF e allineamento.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
Nota: se utilizzi una GPU con architettura Ampere (ad esempio NVIDIA L4) o più recente, puoi utilizzare Flash Attention. Flash Attention è un metodo che accelera notevolmente i calcoli e riduce l'utilizzo della memoria da quadratico a lineare in base alla lunghezza della sequenza, con conseguente accelerazione dell'addestramento fino a tre volte. Scopri di più su FlashAttention.
Prima di poter iniziare l'addestramento, devi assicurarti di aver accettato i termini di utilizzo di Gemma. Puoi accettare la licenza su Hugging Face facendo clic sul pulsante Accetta e accedi al repository nella pagina del modello all'indirizzo: http://huggingface.co/google/gemma-3-270m-it
Dopo aver accettato la licenza, è necessario un token Hugging Face valido per accedere al modello. Se esegui l'operazione all'interno di Google Colab, puoi utilizzare in modo sicuro il tuo token Hugging Face utilizzando i segreti di Colab. In alternativa, puoi impostare il token direttamente nel metodo login. Assicurati che il token abbia anche accesso in scrittura, in quanto il modello viene inviato all'hub durante l'addestramento.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
Puoi conservare i risultati nella macchina virtuale locale di Colab. Tuttavia, ti consigliamo vivamente di salvare i risultati intermedi su Google Drive. In questo modo, i risultati dell'addestramento sono sicuri e puoi confrontare e selezionare facilmente il modello migliore.
from google.colab import drive
drive.mount('/content/drive')
Seleziona il modello di base da ottimizzare, regola la directory dei checkpoint e il tasso di apprendimento.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
Crea e prepara il set di dati di perfezionamento
Il set di dati bebechien/MobileGameNPC fornisce un piccolo campione di conversazioni tra un giocatore e due PNG alieni (un marziano e un venusiano), ognuno con uno stile di linguaggio unico. Ad esempio, l'NPC marziano parla con un accento che sostituisce il suono "s" con "z", usa "da" per "the", "diz" per "this" e include occasionali clic come *k'tak*.
Questo set di dati dimostra un principio fondamentale per il perfezionamento: le dimensioni del set di dati richiesto dipendono dall'output desiderato.
- Per insegnare al modello una variazione stilistica di una lingua che già conosce, come l'accento marziano, può essere sufficiente un piccolo set di dati con un numero di esempi compreso tra 10 e 20.
- Tuttavia, per insegnare al modello una lingua aliena completamente nuova o mista, sarebbe necessario un set di dati molto più grande.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
Ottimizzare Gemma utilizzando TRL e SFTTrainer
Ora puoi mettere a punto il modello. Hugging Face TRL SFTTrainer semplifica la supervisione della messa a punto di LLM aperti. SFTTrainer è una sottoclasse di Trainer della libreria transformers e supporta tutte le stesse funzionalità.
Il seguente codice carica il modello Gemma e il tokenizer da Hugging Face.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
Prima dell'ottimizzazione
L'output riportato di seguito mostra che le funzionalità predefinite potrebbero non essere sufficienti per questo caso d'uso.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
L'esempio precedente verifica la funzione principale del modello di generare dialoghi in-game, mentre l'esempio successivo è progettato per testare la coerenza dei personaggi. Mettiamo alla prova il modello con un prompt fuori tema. Ad esempio, Sorry, you are a game NPC., che non rientra nella knowledge base del personaggio.
L'obiettivo è vedere se il modello riesce a rimanere nel personaggio anziché rispondere alla domanda fuori contesto. Questo servirà da base di riferimento per valutare l'efficacia con cui la procedura di perfezionamento ha instillato la persona desiderata.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
Anche se possiamo utilizzare il prompt engineering per indirizzare il tono, i risultati possono essere imprevedibili e non sempre in linea con la persona che vogliamo.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
Formazione
Prima di poter iniziare l'addestramento, devi definire gli iperparametri che vuoi utilizzare in un'istanza SFTConfig.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
Ora hai tutti gli elementi di base necessari per creare il tuo SFTTrainer e iniziare l'addestramento del modello.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
Inizia l'addestramento chiamando il metodo train().
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
Per tracciare le perdite di addestramento e convalida, in genere estrai questi valori dall'oggetto TrainerState o dai log generati durante l'addestramento.
Librerie come Matplotlib possono essere utilizzate per visualizzare questi valori in base ai passaggi o alle epoche di addestramento. L'asse X rappresenta i passaggi o le epoche di addestramento, mentre l'asse Y rappresenta i valori di perdita corrispondenti.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
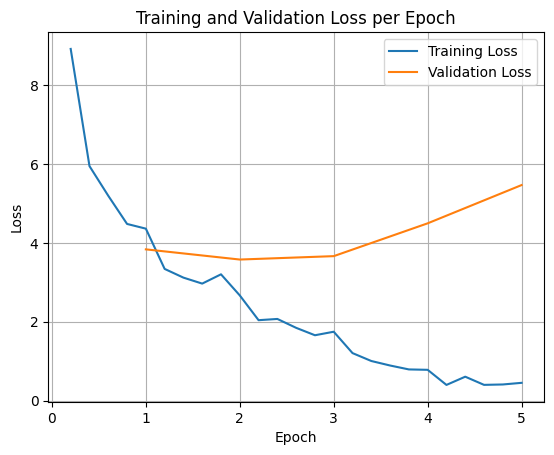
Questa visualizzazione aiuta a monitorare il processo di addestramento e a prendere decisioni informate sull'ottimizzazione degli iperparametri o sull'interruzione anticipata.
La perdita di addestramento misura l'errore sui dati su cui è stato addestrato il modello, mentre la perdita di convalida misura l'errore su un set di dati separato che il modello non ha mai visto prima. Il monitoraggio di entrambi aiuta a rilevare l'overfitting (quando il modello funziona bene sui dati di addestramento, ma male su dati mai visti prima).
- perdita di convalida >> perdita di addestramento: overfitting
- perdita di convalida > perdita di addestramento: un po' di overfitting
- perdita di convalida < perdita di addestramento: sottodimensionamento
- perdita di convalida << perdita di addestramento: sottoadattamento
Test dell'inferenza del modello
Al termine dell'addestramento, dovrai valutare e testare il modello. Puoi caricare campioni diversi dal set di dati di test e valutare il modello in base a questi campioni.
Per questo caso d'uso specifico, la scelta del modello migliore è una questione di preferenze. È interessante notare che quello che normalmente chiameremmo "overfitting" può essere molto utile per un NPC di gioco. Forza il modello a dimenticare le informazioni generali e a concentrarsi invece sulla persona e sulle caratteristiche specifiche su cui è stato addestrato, garantendo che rimanga coerente con il personaggio.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Carichiamo tutte le domande dal set di dati di test e generiamo gli output.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
Se provi il nostro prompt generalista originale, puoi notare che il modello tenta comunque di rispondere nello stile addestrato. In questo esempio, l'overfitting e l'oblio catastrofico sono in realtà utili per il personaggio non giocabile perché inizierà a dimenticare le conoscenze generali che potrebbero non essere applicabili. Questo vale anche per altri tipi di messa a punto completa in cui l'obiettivo è limitare l'output a formati di dati specifici.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
Riepilogo e passaggi successivi
Questo tutorial ha spiegato come eseguire il perfezionamento completo del modello utilizzando TRL. Consulta i seguenti documenti: