
이 가이드에서는 Hugging Face Safetensors 형식 (.safetensors)의 Gemma 모델을 MediaPipe 작업 파일 형식(.task)으로 변환하는 방법을 설명합니다. 이 변환은 MediaPipe LLM 추론 API 및 LiteRT 런타임을 사용하여 Android 및 iOS에서 온디바이스 추론을 위해 사전 학습된 Gemma 모델 또는 미세 조정된 Gemma 모델을 배포하는 데 필수적입니다.
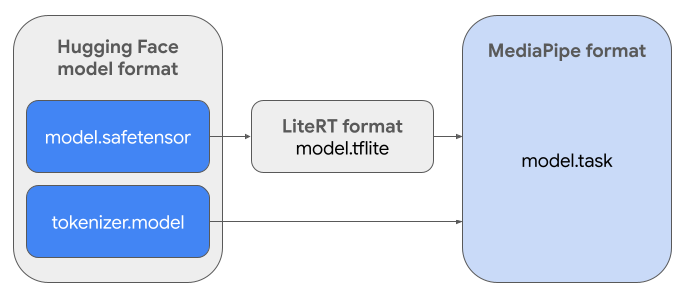
필요한 태스크 번들 (.task)을 만들려면 LiteRT Torch를 사용합니다. 이 도구는 PyTorch 모델을 다중 서명 LiteRT (.tflite) 모델로 내보냅니다. 이 모델은 MediaPipe LLM 추론 API와 호환되며 모바일 애플리케이션의 CPU 백엔드에서 실행하는 데 적합합니다.
최종 .task 파일은 MediaPipe에서 필요한 자체 포함 패키지로, LiteRT 모델, 토큰화 도구 모델, 필수 메타데이터를 번들로 묶습니다. 이 번들은 토큰화 도구 (텍스트 프롬프트를 모델의 토큰 임베딩으로 변환)가 엔드 투 엔드 추론을 지원하기 위해 LiteRT 모델과 함께 패키징되어야 하므로 필요합니다.
다음은 프로세스의 단계별 분석입니다.
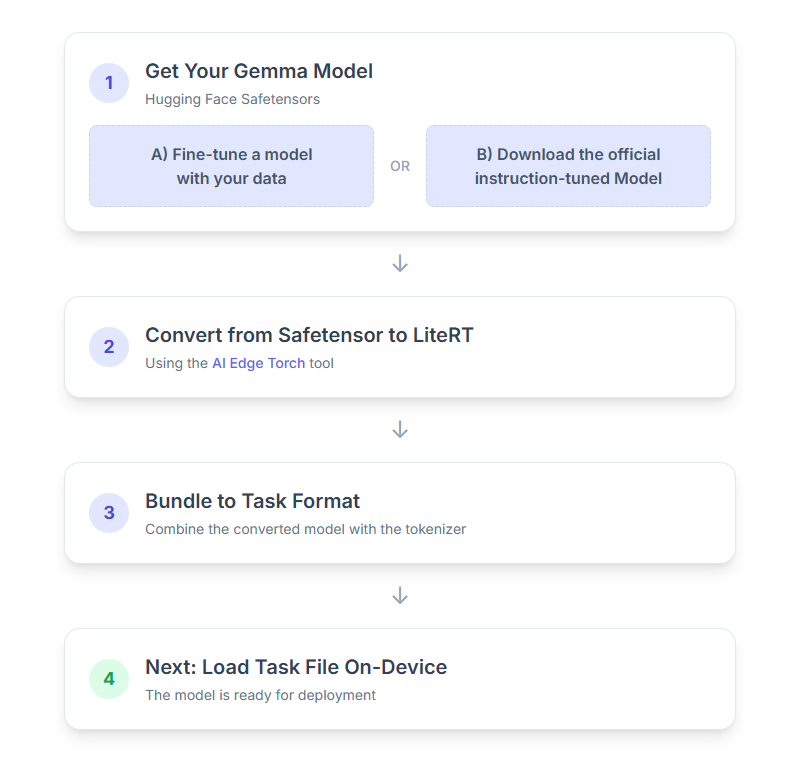
1. Gemma 모델 가져오기
시작하는 방법에는 두 가지 옵션이 있습니다.
옵션 A 기존 미세 조정 모델 사용
미세 조정된 Gemma 모델이 준비되어 있다면 다음 단계로 진행하세요.
옵션 B 공식 명령 조정 모델 다운로드
모델이 필요한 경우 Hugging Face Hub에서 명령 튜닝된 Gemma를 다운로드하면 됩니다.
필요한 도구 설정:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
모델 다운로드:
Hugging Face Hub의 모델은 일반적으로 <organization_or_username>/<model_name> 형식의 모델 ID로 식별됩니다. 예를 들어 공식 Google Gemma 3 270M 명령 조정 모델을 다운로드하려면 다음을 사용하세요.
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. 모델을 LiteRT로 변환하고 양자화
Python 가상 환경을 설정하고 LiteRT Torch 패키지의 최신 안정화 버전을 설치합니다.
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
다음 스크립트를 사용하여 Safetensor를 LiteRT 모델로 변환합니다.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
이 과정은 시간이 오래 걸리며 컴퓨터의 처리 속도에 따라 달라집니다. 참고로 2025년 8코어 CPU에서 2억 7천만 모델은 5~10분 이상 걸리고 10억 모델은 약 10~30분 걸릴 수 있습니다.
최종 출력인 LiteRT 모델은 지정된 OUTPUT_DIR_PATH에 저장됩니다.
타겟 기기의 메모리 및 성능 제약 조건에 따라 다음 값을 조정합니다.
kv_cache_max_len: 모델의 작업 메모리 (KV 캐시)의 총 할당된 크기를 정의합니다. 이 용량은 하드 제한이며 프롬프트의 토큰 (사전 입력)과 이후에 생성된 모든 토큰 (디코딩)의 합계를 저장할 수 있을 만큼 충분해야 합니다.prefill_seq_len: 사전 채우기 청크를 위한 입력 프롬프트의 토큰 수를 지정합니다. 사전 입력 청크를 사용하여 입력 프롬프트를 처리할 때 전체 시퀀스 (예: 50,000개 토큰)이 한 번에 계산되지 않습니다. 대신 메모리 부족 오류를 방지하기 위해 캐시에 순차적으로 로드되는 관리 가능한 세그먼트 (예: 2,048개 토큰 청크)로 나뉩니다.quantize: 선택한 양자화 스키마의 문자열입니다. 다음은 Gemma 3에 사용할 수 있는 양자화 레시피 목록입니다.none: 양자화 없음fp16: FP16 가중치, FP32 활성화, 모든 작업의 부동 소수점 계산dynamic_int8: FP32 활성화, INT8 가중치, 정수 계산weight_only_int8: FP32 활성화, INT8 가중치, 부동 소수점 계산
3. LiteRT 및 토큰화 도구에서 작업 번들 만들기
Python 가상 환경을 설정하고 mediapipe Python 패키지를 설치합니다.
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
genai.bundler 라이브러리를 사용하여 모델을 번들로 묶습니다.
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
bundler.create_bundle 함수는 모델을 실행하는 데 필요한 모든 정보가 포함된 .task 파일을 만듭니다.
4. Android에서 Mediapipe를 사용한 추론
기본 구성 옵션으로 작업을 초기화합니다.
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
generateResponse() 메서드를 사용하여 텍스트 응답을 생성합니다.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
대답을 스트리밍하려면 generateResponseAsync() 메서드를 사용합니다.
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
자세한 내용은 Android용 LLM 추론 가이드를 참고하세요.
다음 단계
Gemma 모델로 더 많은 것을 빌드하고 탐색하세요.