
|
|
|
|
|
 GitHub에서 소스 보기 GitHub에서 소스 보기
|
이 가이드에서는 Hugging Face Transformers 및 TRL을 사용하여 모바일 게임 NPC 데이터 세트에서 Gemma를 파인 튜닝하는 방법을 안내합니다. 학습 내용
- 개발 환경 설정
- 미세 조정 데이터 세트 준비
- TRL 및 SFTTrainer를 사용하여 Gemma 전체 모델 미세 조정
- 모델 추론 및 분위기 확인 테스트
개발 환경 설정
첫 번째 단계는 다양한 RLHF 및 정렬 기법을 비롯한 공개 모델을 미세 조정하기 위해 TRL 및 데이터 세트를 포함한 Hugging Face 라이브러리를 설치하는 것입니다.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
참고: Ampere 아키텍처 (예: NVIDIA L4) 이상의 GPU를 사용하는 경우 플래시 어텐션을 사용할 수 있습니다. Flash Attention은 계산 속도를 크게 높이고 시퀀스 길이에서 메모리 사용량을 2차에서 선형으로 줄여 학습 속도를 최대 3배까지 높이는 방법입니다. FlashAttention에서 자세히 알아보세요.
학습을 시작하기 전에 Gemma 사용 약관에 동의했는지 확인해야 합니다. http://huggingface.co/google/gemma-3-270m-it의 모델 페이지에서 동의 및 저장소 액세스 버튼을 클릭하여 Hugging Face에서 라이선스를 수락할 수 있습니다.
라이선스에 동의한 후 모델에 액세스하려면 유효한 Hugging Face 토큰이 필요합니다. Google Colab 내에서 실행하는 경우 Colab 보안 비밀을 사용하여 Hugging Face 토큰을 안전하게 사용할 수 있습니다. 그렇지 않으면 login 메서드에서 토큰을 직접 설정할 수 있습니다. 학습 중에 모델을 허브에 푸시하므로 토큰에 쓰기 액세스 권한도 있어야 합니다.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
Colab의 로컬 가상 머신에 결과를 보관할 수 있습니다. 하지만 중간 결과를 Google Drive에 저장하는 것이 좋습니다. 이렇게 하면 학습 결과가 안전해지고 최고의 모델을 쉽게 비교하고 선택할 수 있습니다.
from google.colab import drive
drive.mount('/content/drive')
미세 조정할 기본 모델을 선택하고 체크포인트 디렉터리와 학습률을 조정합니다.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
미세 조정 데이터 세트 만들기 및 준비
bebechien/MobileGameNPC 데이터 세트는 플레이어와 두 외계인 NPC (화성인과 금성인) 간의 작은 샘플 대화를 제공하며, 각 NPC는 고유한 말하기 스타일을 가지고 있습니다. 예를 들어 화성인 NPC는 's' 소리를 'z'로 대체하고, 'the'를 'da'로, 'this'를 'diz'로 사용하며, *k'tak*와 같은 클릭 소리를 가끔 포함하는 억양으로 말합니다.
이 데이터 세트는 미세 조정의 핵심 원칙을 보여줍니다. 필요한 데이터 세트 크기는 원하는 출력에 따라 달라집니다.
- 모델에 이미 알고 있는 언어의 스타일 변형(예: 화성인 억양)을 가르치려면 10~20개의 예시가 포함된 작은 데이터 세트면 충분합니다.
- 하지만 모델에 완전히 새로운 외계어 또는 혼합된 외계어를 가르치려면 훨씬 더 큰 데이터 세트가 필요합니다.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
TRL 및 SFTTrainer를 사용하여 Gemma 미세 조정
이제 모델을 미세 조정할 준비가 되었습니다. Hugging Face TRL SFTTrainer를 사용하면 오픈 LLM을 간단하게 감독하여 미세 조정할 수 있습니다. SFTTrainer는 transformers 라이브러리의 Trainer 서브클래스이며 동일한 기능을 모두 지원합니다.
다음 코드는 Hugging Face에서 Gemma 모델과 토큰화 도구를 로드합니다.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
미세 조정 전
아래 출력은 기본 제공 기능이 이 사용 사례에 적합하지 않을 수 있음을 보여줍니다.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
위의 예에서는 게임 내 대화를 생성하는 모델의 기본 기능을 확인하고, 다음 예에서는 캐릭터 일관성을 테스트하도록 설계되었습니다. 주제에서 벗어난 프롬프트로 모델에 질문합니다. 예를 들어 캐릭터의 지식 베이스에 속하지 않는 Sorry, you are a game NPC.가 있습니다.
목표는 모델이 컨텍스트에서 벗어난 질문에 답변하는 대신 캐릭터를 유지할 수 있는지 확인하는 것입니다. 이는 미세 조정 프로세스가 원하는 페르소나를 얼마나 효과적으로 주입했는지 평가하는 기준으로 사용됩니다.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
프롬프트 엔지니어링을 사용하여 어조를 조정할 수 있지만 결과는 예측할 수 없으며 원하는 페르소나와 일치하지 않을 수 있습니다.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
학습
학습을 시작하기 전에 SFTConfig 인스턴스에서 사용할 초매개변수를 정의해야 합니다.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
이제 모델 학습을 시작하기 위해 SFTTrainer를 만드는 데 필요한 모든 구성요소가 준비되었습니다.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
train() 메서드를 호출하여 학습을 시작합니다.
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
학습 및 검증 손실을 그래프로 표시하려면 일반적으로 TrainerState 객체 또는 학습 중에 생성된 로그에서 이러한 값을 추출합니다.
그런 다음 Matplotlib과 같은 라이브러리를 사용하여 학습 단계 또는 에포크에 걸쳐 이러한 값을 시각화할 수 있습니다. x축은 학습 단계 또는 에포크를 나타내고 y축은 해당 손실 값을 나타냅니다.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
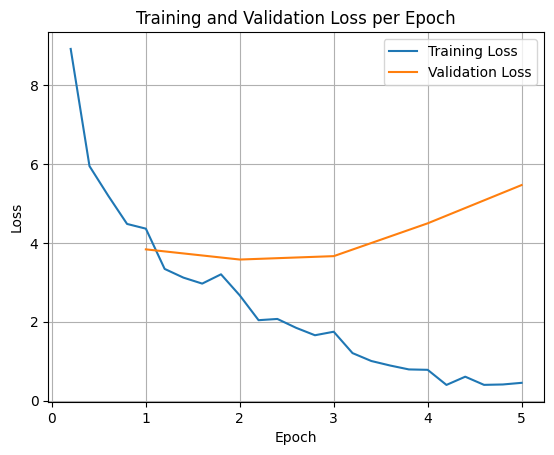
이 시각화는 학습 프로세스를 모니터링하고 하이퍼파라미터 조정 또는 조기 중단에 관한 정보에 기반한 결정을 내리는 데 도움이 됩니다.
학습 손실은 모델이 학습된 데이터의 오류를 측정하고, 검증 손실은 모델이 이전에 본 적이 없는 별도의 데이터 세트의 오류를 측정합니다. 두 가지를 모두 모니터링하면 과적합 (모델이 학습 데이터에서는 잘 작동하지만 확인되지 않은 데이터에서는 성능이 저하되는 경우)을 감지하는 데 도움이 됩니다.
- 검증 손실 >> 학습 손실: 과적합
- 검증 손실 > 학습 손실: 약간의 과적합
- 검증 손실 < 학습 손실: 약간의 과소적합
- 검증 손실 << 학습 손실: 과소적합
테스트 모델 추론
학습이 완료되면 모델을 평가하고 테스트해야 합니다. 테스트 데이터 세트에서 다양한 샘플을 로드하고 해당 샘플에서 모델을 평가할 수 있습니다.
이 특정 사용 사례의 경우 가장 적합한 모델은 선호도에 따라 달라집니다. 흥미롭게도 일반적으로 '과적합'이라고 하는 것이 게임 NPC에는 매우 유용할 수 있습니다. 모델이 일반적인 정보를 잊고 대신 학습된 특정 페르소나와 특징에 집중하도록 강제하여 일관되게 캐릭터를 유지합니다.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
테스트 데이터 세트에서 모든 질문을 로드하고 출력을 생성해 보겠습니다.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
기존의 일반적인 프롬프트를 사용하면 모델이 학습된 스타일로 대답하려고 시도하는 것을 확인할 수 있습니다. 이 예에서는 과적합과 치명적 망각이 게임 NPC에 실제로 유용합니다. 적용되지 않을 수 있는 일반적인 지식을 잊기 시작하기 때문입니다. 출력을 특정 데이터 형식으로 제한하는 것이 목표인 다른 유형의 전체 미세 조정도 마찬가지입니다.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
요약 및 다음 단계
이 튜토리얼에서는 TRL을 사용하여 전체 모델을 미세 조정하는 방법을 다뤘습니다. 다음 문서를 확인하세요.
- Hugging Face Transformers를 사용하여 텍스트 작업을 위해 Gemma를 미세 조정하는 방법을 알아봅니다.
- Hugging Face Transformers를 사용하여 시각 작업에 맞게 Gemma를 미세 조정하는 방법을 알아봅니다.
- Cloud Run에 배포하는 방법 알아보기