
Hướng dẫn này cung cấp các chỉ dẫn để chuyển đổi các mô hình Gemma ở định dạng Hugging Face Safetensors (.safetensors) thành định dạng tệp MediaPipe Task (.task). Quá trình chuyển đổi này là cần thiết để triển khai các mô hình Gemma được huấn luyện trước hoặc tinh chỉnh để suy luận trên thiết bị Android và iOS bằng API suy luận LLM của MediaPipe và thời gian chạy LiteRT.
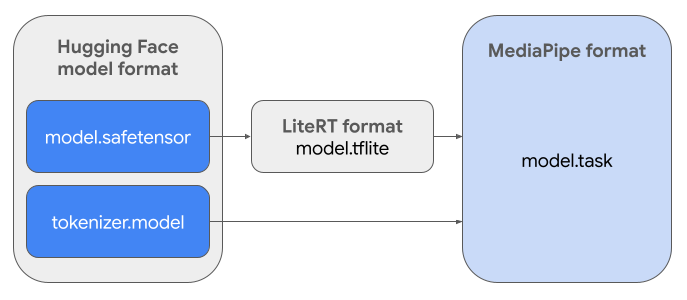
Để tạo Task Bundle (.task) bắt buộc, bạn sẽ dùng LiteRT Torch. Công cụ này xuất các mô hình PyTorch thành các mô hình LiteRT (.tflite) có nhiều chữ ký, tương thích với API Suy luận LLM của MediaPipe và phù hợp để chạy trên các phần phụ trợ CPU trong các ứng dụng di động.
Tệp .task cuối cùng là một gói độc lập mà MediaPipe yêu cầu, kết hợp mô hình LiteRT, mô hình mã hoá từ và siêu dữ liệu thiết yếu. Gói này là cần thiết vì trình mã hoá từ (chuyển đổi câu lệnh văn bản thành các mã nhúng cho mô hình) phải được đóng gói cùng với mô hình LiteRT để bật suy luận từ đầu đến cuối.
Sau đây là quy trình từng bước:
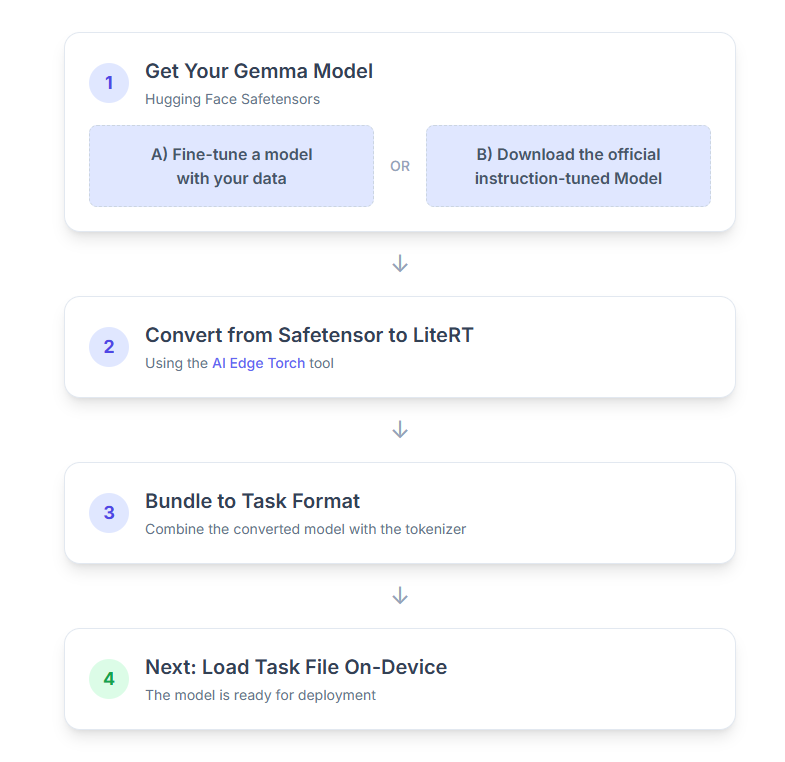
1. Nhận mô hình Gemma
Bạn có hai lựa chọn để bắt đầu.
Lựa chọn A. Sử dụng mô hình đã được tinh chỉnh
Nếu bạn đã chuẩn bị một mô hình Gemma được tinh chỉnh, hãy chuyển sang bước tiếp theo.
Lựa chọn B. Tải Mô hình được tinh chỉnh theo hướng dẫn chính thức xuống
Nếu cần một mô hình, bạn có thể tải Gemma được tinh chỉnh theo hướng dẫn xuống từ Hugging Face Hub.
Thiết lập các công cụ cần thiết:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
Tải mô hình xuống:
Các mô hình trên Hugging Face Hub được xác định bằng một mã nhận dạng mô hình, thường ở định dạng <organization_or_username>/<model_name>. Ví dụ: để tải mô hình chính thức được tinh chỉnh theo hướng dẫn Gemma 3 270M của Google xuống, hãy sử dụng:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. Chuyển đổi và lượng tử hoá mô hình thành LiteRT
Thiết lập môi trường ảo Python và cài đặt bản phát hành ổn định mới nhất của gói LiteRT Torch:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
Sử dụng tập lệnh sau để chuyển đổi Safetensor thành mô hình LiteRT.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
Xin lưu ý rằng quy trình này tốn nhiều thời gian và phụ thuộc vào tốc độ xử lý của máy tính. Để tham khảo, trên CPU 8 lõi năm 2025, một mô hình 270M mất hơn 5 đến 10 phút, trong khi một mô hình 1B có thể mất khoảng 10 đến 30 phút.
Đầu ra cuối cùng (mô hình LiteRT) sẽ được lưu vào OUTPUT_DIR_PATH mà bạn chỉ định.
Điều chỉnh các giá trị sau đây dựa trên các hạn chế về bộ nhớ và hiệu suất của thiết bị mục tiêu.
kv_cache_max_len: Xác định tổng kích thước được phân bổ của bộ nhớ hoạt động của mô hình (bộ nhớ đệm KV). Dung lượng này là một giới hạn cứng và phải đủ để lưu trữ tổng số mã thông báo của câu lệnh (nội dung điền sẵn) và tất cả các mã thông báo được tạo sau đó (nội dung giải mã).prefill_seq_len: Chỉ định số lượng mã thông báo của câu lệnh đầu vào để phân đoạn điền sẵn. Khi xử lý câu lệnh đầu vào bằng cách phân đoạn điền sẵn, toàn bộ chuỗi (ví dụ: 50.000 mã thông báo) không được tính toán cùng một lúc; thay vào đó, nó được chia thành các phân đoạn có thể quản lý (ví dụ: các khối 2.048 mã thông báo) được tải tuần tự vào bộ nhớ đệm để ngăn lỗi hết bộ nhớ.quantize: chuỗi cho các lược đồ định lượng đã chọn. Sau đây là danh sách các công thức lượng tử hoá có sẵn cho Gemma 3.none: Không có lượng tử hoáfp16: Trọng số FP16, lượt kích hoạt FP32 và tính toán dấu phẩy động cho tất cả các hoạt độngdynamic_int8: Hoạt động FP32, trọng số INT8 và phép tính số nguyênweight_only_int8: Hoạt động FP32, trọng số INT8 và phép tính dấu phẩy động
3. Tạo Task Bundle từ LiteRT và trình mã hoá từ
Thiết lập môi trường ảo Python và cài đặt gói Python mediapipe:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
Sử dụng thư viện genai.bundler để kết hợp mô hình:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
Hàm bundler.create_bundle tạo một tệp .task chứa tất cả thông tin cần thiết để chạy mô hình.
4. Suy luận bằng Mediapipe trên Android
Khởi chạy tác vụ bằng các lựa chọn cấu hình cơ bản:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
Sử dụng phương thức generateResponse() để tạo một câu trả lời bằng văn bản.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
Để truyền trực tuyến phản hồi, hãy sử dụng phương thức generateResponseAsync().
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
Hãy xem hướng dẫn về suy luận bằng mô hình ngôn ngữ lớn cho Android để biết thêm thông tin.
Các bước tiếp theo
Tạo và khám phá thêm bằng các mô hình Gemma: