
|
|
|
|
|
 Xem nguồn trên GitHub Xem nguồn trên GitHub
|
Hướng dẫn này sẽ hướng dẫn bạn cách tinh chỉnh Gemma trên một tập dữ liệu NPC của trò chơi di động bằng cách sử dụng Transformers và TRL của Hugging Face. Bạn sẽ tìm hiểu:
- Thiết lập môi trường phát triển
- Chuẩn bị tập dữ liệu tinh chỉnh
- Tinh chỉnh toàn bộ mô hình Gemma bằng TRL và SFTTrainer
- Kiểm thử suy luận mô hình và kiểm tra cảm xúc
Thiết lập môi trường phát triển
Bước đầu tiên là cài đặt Thư viện Hugging Face, bao gồm TRL và các tập dữ liệu để tinh chỉnh mô hình mở, bao gồm nhiều kỹ thuật RLHF và kỹ thuật điều chỉnh.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
Lưu ý: Nếu đang sử dụng GPU có cấu trúc Ampere (chẳng hạn như NVIDIA L4) hoặc mới hơn, bạn có thể sử dụng cơ chế chú ý nhanh. Flash Attention là một phương pháp giúp tăng tốc đáng kể các phép tính và giảm mức sử dụng bộ nhớ từ bậc hai xuống bậc nhất theo độ dài chuỗi, dẫn đến việc tăng tốc quá trình huấn luyện lên đến 3 lần. Tìm hiểu thêm tại FlashAttention.
Trước khi bắt đầu huấn luyện, bạn phải đảm bảo rằng bạn đã chấp nhận điều khoản sử dụng Gemma. Bạn có thể chấp nhận giấy phép trên Hugging Face bằng cách nhấp vào nút Đồng ý và truy cập vào kho lưu trữ trên trang mô hình tại: http://huggingface.co/google/gemma-3-270m-it
Sau khi chấp nhận giấy phép, bạn cần có một mã thông báo Hugging Face hợp lệ để truy cập vào mô hình. Nếu đang chạy trong Google Colab, bạn có thể sử dụng Hugging Face Token một cách an toàn bằng cách sử dụng các bí mật của Colab. Nếu không, bạn có thể đặt mã thông báo trực tiếp trong phương thức login. Đảm bảo mã thông báo của bạn cũng có quyền ghi, vì bạn sẽ đẩy mô hình của mình lên Hub trong quá trình huấn luyện.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
Bạn có thể lưu giữ kết quả trên máy ảo cục bộ của Colab. Tuy nhiên, bạn nên lưu kết quả trung gian vào Google Drive. Điều này đảm bảo kết quả huấn luyện của bạn an toàn và giúp bạn dễ dàng so sánh cũng như chọn mô hình phù hợp nhất.
from google.colab import drive
drive.mount('/content/drive')
Chọn mô hình cơ sở để tinh chỉnh, điều chỉnh thư mục điểm kiểm tra và tốc độ học.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
Tạo và chuẩn bị tập dữ liệu tinh chỉnh
Tập dữ liệu bebechien/MobileGameNPC cung cấp một số ít cuộc trò chuyện mẫu giữa một người chơi và hai NPC người ngoài hành tinh (một người sao Hoả và một người sao Kim), mỗi người có một phong cách nói riêng. Ví dụ: NPC người Sao Hoả nói với giọng thay thế âm "s" bằng âm "z", dùng "da" cho "the", "diz" cho "this" và thỉnh thoảng có tiếng nhấp như *k'tak*.
Tập dữ liệu này minh hoạ một nguyên tắc quan trọng để tinh chỉnh: kích thước tập dữ liệu bắt buộc phụ thuộc vào đầu ra mong muốn.
- Để dạy cho mô hình một biến thể phong cách của ngôn ngữ mà mô hình đã biết, chẳng hạn như giọng của người Sao Hoả, một tập dữ liệu nhỏ chỉ với 10 đến 20 ví dụ là đủ.
- Tuy nhiên, để dạy mô hình một ngôn ngữ hoàn toàn mới hoặc hỗn hợp của người ngoài hành tinh, bạn sẽ cần một tập dữ liệu lớn hơn đáng kể.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
Tinh chỉnh Gemma bằng TRL và SFTTrainer
Giờ đây, bạn đã sẵn sàng tinh chỉnh mô hình của mình. SFTTrainer của Hugging Face TRL giúp bạn dễ dàng giám sát quá trình tinh chỉnh các LLM mở. SFTTrainer là một lớp con của Trainer trong thư viện transformers và hỗ trợ tất cả các tính năng tương tự,
Đoạn mã sau đây tải mô hình Gemma và mã hoá từ Hugging Face.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
Trước khi tinh chỉnh
Đầu ra bên dưới cho thấy các chức năng có sẵn có thể không đủ cho trường hợp sử dụng này.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
Ví dụ trên kiểm tra chức năng chính của mô hình là tạo đoạn hội thoại trong trò chơi, ví dụ tiếp theo được thiết kế để kiểm tra tính nhất quán của nhân vật. Chúng tôi thử thách mô hình bằng một câu lệnh lạc đề. Ví dụ: Sorry, you are a game NPC. nằm ngoài cơ sở kiến thức của nhân vật.
Mục tiêu là xem liệu mô hình có thể giữ nguyên tính cách thay vì trả lời câu hỏi không liên quan hay không. Điều này sẽ đóng vai trò là cơ sở để đánh giá mức độ hiệu quả của quy trình tinh chỉnh trong việc tạo ra nhân vật mong muốn.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
Mặc dù chúng ta có thể sử dụng kỹ thuật tạo câu lệnh để điều chỉnh giọng điệu của AI, nhưng kết quả có thể khó đoán và không phải lúc nào cũng phù hợp với tính cách mà chúng ta muốn.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
Đào tạo
Trước khi bắt đầu quá trình huấn luyện, bạn cần xác định các siêu tham số mà bạn muốn sử dụng trong một phiên bản SFTConfig.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
Giờ đây, bạn đã có mọi thành phần cơ bản cần thiết để tạo SFTTrainer nhằm bắt đầu huấn luyện mô hình của mình.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
Bắt đầu huấn luyện bằng cách gọi phương thức train().
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
Để vẽ biểu đồ tổn thất trong quá trình huấn luyện và xác thực, bạn thường sẽ trích xuất các giá trị này từ đối tượng TrainerState hoặc nhật ký được tạo trong quá trình huấn luyện.
Sau đó, bạn có thể dùng các thư viện như Matplotlib để trực quan hoá những giá trị này qua các bước hoặc giai đoạn huấn luyện. Trục x sẽ biểu thị các bước hoặc số lần huấn luyện, còn trục y sẽ biểu thị các giá trị tổn thất tương ứng.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
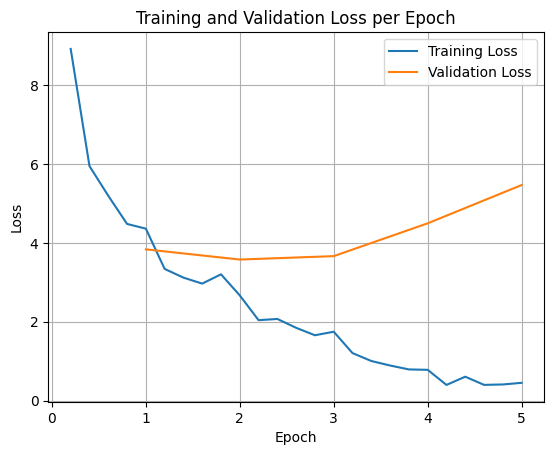
Hình ảnh trực quan này giúp theo dõi quá trình huấn luyện và đưa ra quyết định sáng suốt về việc điều chỉnh siêu tham số hoặc dừng sớm.
Mất mát trong quá trình huấn luyện đo lường lỗi trên dữ liệu mà mô hình được huấn luyện, trong khi mất mát trong quá trình xác thực đo lường lỗi trên một tập dữ liệu riêng biệt mà mô hình chưa từng thấy trước đây. Việc giám sát cả hai giúp phát hiện tình trạng khớp quá mức (khi mô hình hoạt động hiệu quả trên dữ liệu huấn luyện nhưng hoạt động kém hiệu quả trên dữ liệu chưa từng thấy).
- mất mát xác thực >> mất mát đào tạo: quá khớp
- mất xác thực > mất huấn luyện: một số trường hợp khớp quá mức
- mất mát xác thực < mất mát khi huấn luyện: một số trường hợp thiếu khớp
- mất mát xác thực << mất mát huấn luyện: thiếu khớp
Suy luận mô hình kiểm thử
Sau khi quá trình huấn luyện hoàn tất, bạn nên đánh giá và kiểm thử mô hình của mình. Bạn có thể tải các mẫu khác nhau từ tập dữ liệu kiểm thử và đánh giá mô hình trên các mẫu đó.
Đối với trường hợp sử dụng cụ thể này, mô hình tốt nhất là vấn đề về lựa chọn ưu tiên. Điều thú vị là những gì chúng ta thường gọi là "quá khớp" có thể rất hữu ích cho NPC trong trò chơi. Điều này buộc mô hình quên đi thông tin chung và thay vào đó tập trung vào tính cách và đặc điểm cụ thể mà mô hình được huấn luyện, đảm bảo mô hình luôn nhất quán về tính cách.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Hãy tải tất cả các câu hỏi từ tập dữ liệu kiểm thử và tạo đầu ra.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
Nếu thử câu lệnh chung chung ban đầu của chúng tôi, bạn có thể thấy rằng mô hình vẫn cố gắng trả lời theo phong cách đã được huấn luyện. Trong ví dụ này, việc huấn luyện quá mức và quên kiến thức hoàn toàn thực sự có lợi cho NPC trong trò chơi vì NPC sẽ bắt đầu quên kiến thức chung có thể không áp dụng được. Điều này cũng đúng với các loại tinh chỉnh toàn bộ khác, trong đó mục tiêu là hạn chế đầu ra ở các định dạng dữ liệu cụ thể.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
Tóm tắt và các bước tiếp theo
Hướng dẫn này trình bày cách điều chỉnh mô hình đầy đủ bằng TRL. Hãy xem các tài liệu sau đây:
- Tìm hiểu cách điều chỉnh Gemma cho các tác vụ văn bản bằng Hugging Face Transformers.
- Tìm hiểu cách điều chỉnh Gemma cho các tác vụ về thị giác bằng Hugging Face Transformers.
- Tìm hiểu cách triển khai trên Cloud Run