
本指南提供操作說明,協助您將 Hugging Face Safetensors 格式 (.safetensors) 的 Gemma 模型轉換為 MediaPipe Task 檔案格式 (.task)。這項轉換作業至關重要,因為您必須使用 MediaPipe LLM Inference API 和 LiteRT 執行階段,才能在 Android 和 iOS 裝置上部署預先訓練或微調的 Gemma 模型,進行裝置端推論。

如要建立必要的工作套件 (.task),請使用 LiteRT Torch。這項工具會將 PyTorch 模型匯出為多重簽章 LiteRT (.tflite) 模型,這類模型與 MediaPipe LLM 推論 API 相容,適合在行動應用程式的 CPU 後端執行。
最終的 .task 檔案是 MediaPipe 要求的獨立套件,其中包含 LiteRT 模型、權杖化模型和必要的中繼資料。由於權杖化工具 (可將文字提示轉換為模型適用的權杖嵌入) 必須與 LiteRT 模型一併封裝,才能進行端對端推論,因此這個套件是必要的。
以下是逐步操作說明:
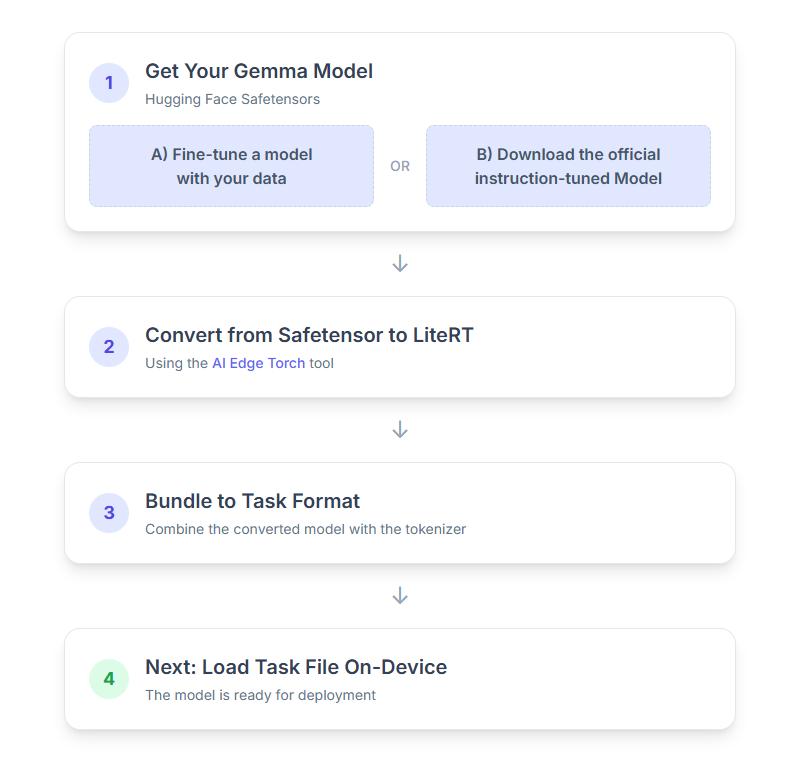
1. 取得 Gemma 模型
你可以透過兩種方式開始使用。
選項 A:使用現有的微調模型
如果您已準備好微調 Gemma 模型,請直接進行下一個步驟。
選項 B:下載官方指令調整模型
如需模型,可以從 Hugging Face Hub 下載經過指令微調的 Gemma。
設定必要工具:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
下載模型:
Hugging Face Hub 中的模型會以模型 ID 識別,通常採用 <organization_or_username>/<model_name> 格式。舉例來說,如要下載官方 Google Gemma 3 270M 指令微調模型,請使用:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. 將模型轉換為 LiteRT 並量化
設定 Python 虛擬環境,並安裝最新穩定版本的 LiteRT Torch 套件:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
使用下列指令碼將 Safetensor 轉換為 LiteRT 模型。
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
請注意,這項程序耗時,且取決於電腦的處理速度。以 2025 年的 8 核心 CPU 為例,2.7 億個參數的模型需要 5 到 10 分鐘,10 億個參數的模型則需要 10 到 30 分鐘。
最終輸出內容 (LiteRT 模型) 會儲存至您指定的 OUTPUT_DIR_PATH。
請根據目標裝置的記憶體和效能限制調整下列值。
kv_cache_max_len:定義模型工作記憶體 (KV 快取) 的總分配大小。這項容量是硬性限制,必須足以儲存提示權杖 (預填) 和所有後續產生的權杖 (解碼) 的總和。prefill_seq_len:指定預填區塊的輸入提示符記數。使用前置填充分塊處理輸入提示時,整個序列 (例如50,000 個權杖),而是分成可管理的區段 (例如 2,048 個權杖的區塊),依序載入快取,避免發生記憶體不足錯誤。quantize:所選量化配置的字串。以下列出 Gemma 3 適用的量化配方。none:無量化fp16:所有作業的 FP16 權重、FP32 啟用和浮點運算dynamic_int8:FP32 啟用、INT8 權重和整數運算weight_only_int8:FP32 啟用、INT8 權重和浮點運算
3. 從 LiteRT 和權杖化工具建立 Task Bundle
設定 Python 虛擬環境並安裝 mediapipe Python 套件:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
使用 genai.bundler 程式庫將模型套裝組合:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
bundler.create_bundle 函式會建立 .task 檔案,其中包含執行模型所需的所有資訊。
4. 在 Android 上使用 Mediapipe 進行推論
使用基本設定選項初始化工作:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
使用 generateResponse() 方法生成文字回覆。
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
如要串流回應,請使用 generateResponseAsync() 方法。
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
詳情請參閱 Android 適用的 LLM 推論指南。
後續步驟
運用 Gemma 模型建構及探索更多內容: