
Para comprender DiffusionGemma, es útil examinar las limitaciones principales de los modelos de lenguaje estándar y cómo se diferencia la difusión basada en texto.
El problema con los modelos autorregresivos
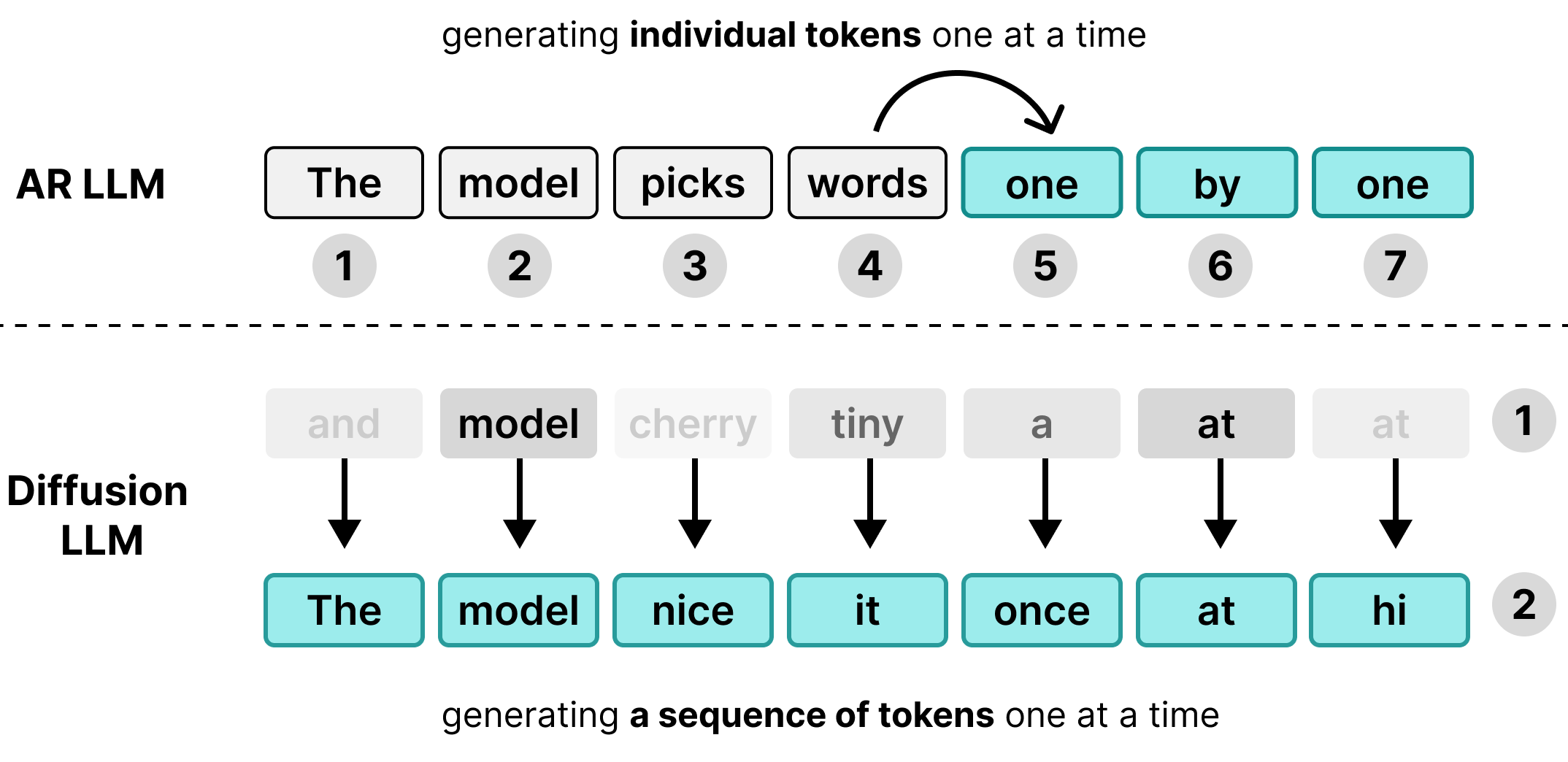
Muchos modelos de lenguaje grandes (LLM) son autorregresivos, lo que significa que generan texto token por token. Si bien este enfoque funciona bien para atender a muchos usuarios de forma simultánea a través de la agrupación por lotes, crea un cuello de botella de latencia para los usuarios individuales.
Durante la fase de decodificación, los modelos Transformer estándar están limitados por la memoria en lugar de por la capacidad de procesamiento. La mayor parte del tiempo de generación se dedica a cargar los pesos del modelo desde la memoria del hardware en las unidades de procesamiento, en lugar de realizar los cálculos matemáticos reales. Dado que los pesos solo deben cargarse una vez por paso, independientemente del tamaño del lote, generar un token lleva casi la misma cantidad de tiempo para 1 usuario que para 256 usuarios agrupados.
Por lo tanto, un usuario individual no ve ninguna ventaja de latencia; la capacidad de procesamiento del hardware permanece inactiva mientras espera las transferencias de memoria.
DiffusionGemma utiliza este tiempo de procesamiento inactivo para el usuario individual. En lugar de generar 1 token para 256 usuarios independientes, genera 256 tokens a la vez para un solo usuario.
El modelo inicializa una secuencia en blanco de 256 tokens aleatorios, llamada lienzo, y evalúa y perfecciona de forma iterativa todo el lienzo de manera simultánea. Esto hace que el modelo pase de estar limitado por la memoria a estar limitado por la capacidad de procesamiento, lo que le permite escalar las velocidades de procesamiento de manera eficiente a medida que aumenta la capacidad de procesamiento.
| Aspecto | Autoregresión de texto | Difusión de texto |
|---|---|---|
| Generación de tokens | Un token a la vez | Un lienzo completo de tokens a la vez |
| Pasos | Un paso para cada token | Un paso para varios tokens |
| Orden de generación | De izquierda a derecha | Todas las posiciones en paralelo |
| Punto de partida | Secuencia vacía | Tokens aleatorios muestreados del vocabulario |
| Corrección de errores | Estático: No se pueden revisar los tokens anteriores | Dinámico: Se puede revisar cualquier posición del lienzo |
| Cuello de botella de hardware | Limitado por la memoria | Vinculado al procesamiento |
| Enfoque en la capacidad de procesamiento | Alta capacidad de procesamiento multiusuario | Latencia ultrabaja para un solo usuario |
Comprensión de la mecánica de la difusión de texto
En la generación de imágenes, los modelos de difusión comienzan con un ruido gaussiano 100% aleatorio y lo quitan progresivamente (reducción de ruido) en varios pasos guiados por una instrucción de texto. Traducir esta lógica a texto es más difícil porque los tokens de texto son entidades discretas, a diferencia de los valores de píxeles continuos.
DiffusionGemma logra la difusión basada en texto a través de una progresión de metodologías especializadas:
1. Masked Diffusion
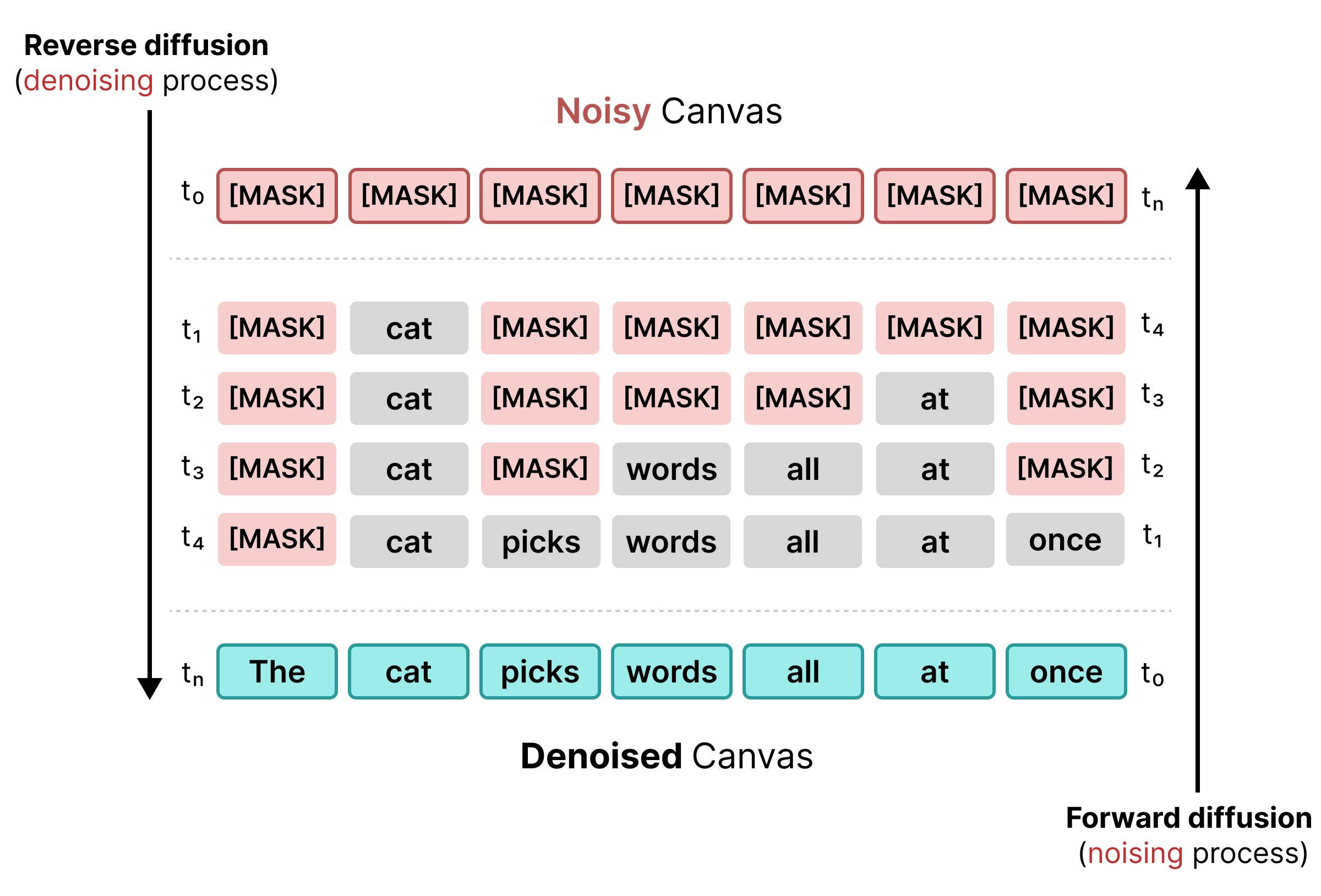
La difusión de texto inicial se basaba en el enmascaramiento, de manera similar al entrenamiento de BERT. Los tokens aleatorios de una secuencia se reemplazan por un token [MASK] (que representa ruido). Durante la difusión inversa, el modelo predice el token correcto detrás de la máscara y sustituye los tokens cuando la confianza alcanza un umbral específico.
Sin embargo, la difusión enmascarada sufre de rigidez: una vez que un token [MASK] se reemplaza por una palabra, se fija. No se puede corregir en pasos posteriores si cambia el contexto circundante.
2. Uniform State Diffusion
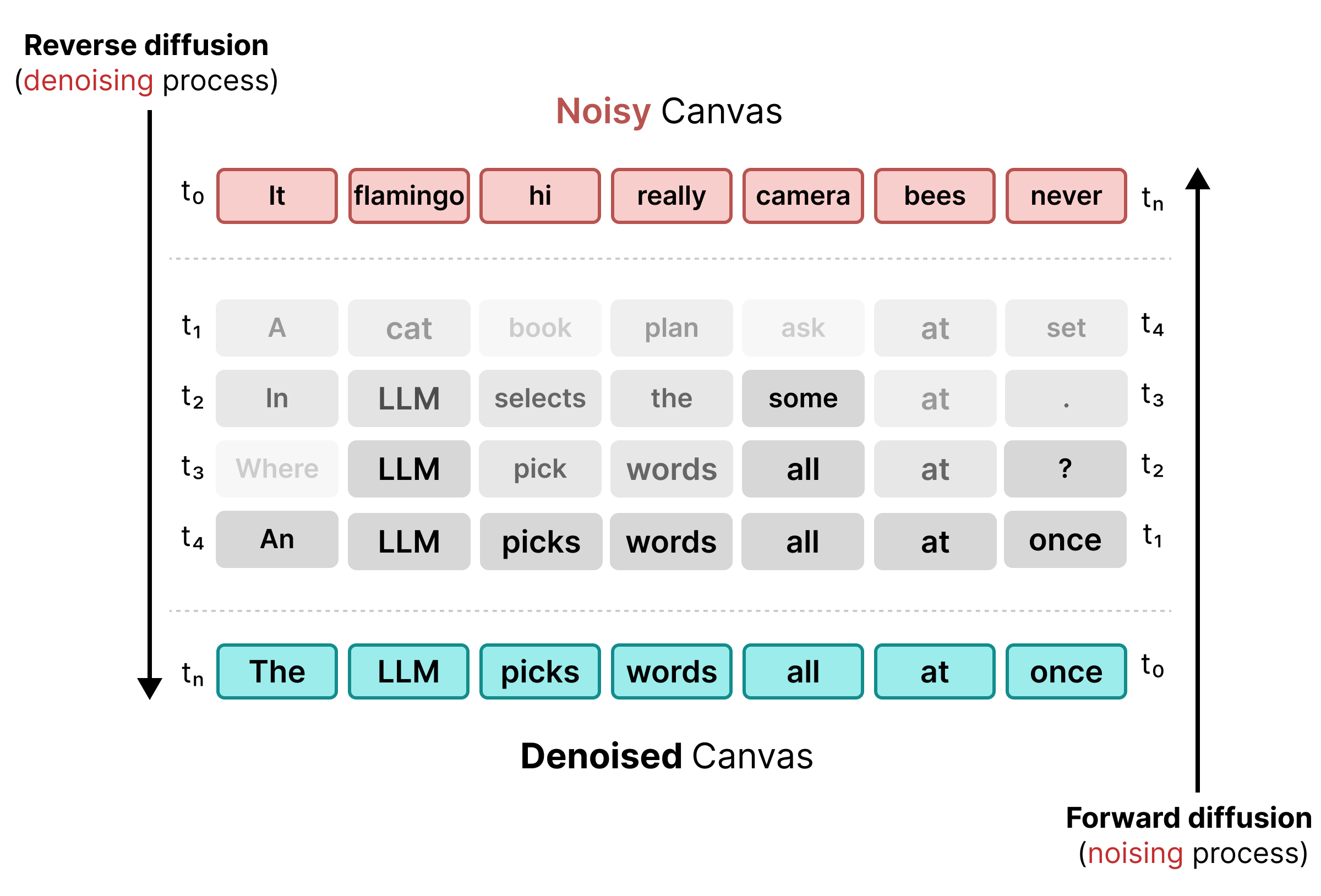
Para resolver las limitaciones del enmascaramiento, DiffusionGemma usa la difusión de estado uniforme. En lugar de un token [MASK] explícito, se introduce ruido reemplazando las palabras originales por tokens aleatorios del vocabulario.
Durante el proceso de reducción de ruido, el modelo analiza todo el lienzo para determinar qué tokens son ruido contextual y los actualiza. Si un token es correcto, conserva una probabilidad alta. Si la probabilidad de un token cae por debajo de un umbral debido a que surge un nuevo contexto en pasos posteriores, se vuelve a agregar ruido con un token aleatorio nuevo. Este ciclo permite la corrección continua de errores y el perfeccionamiento paralelo del lienzo.
Arquitectura: El completado previo y la reducción de ruido incrementales
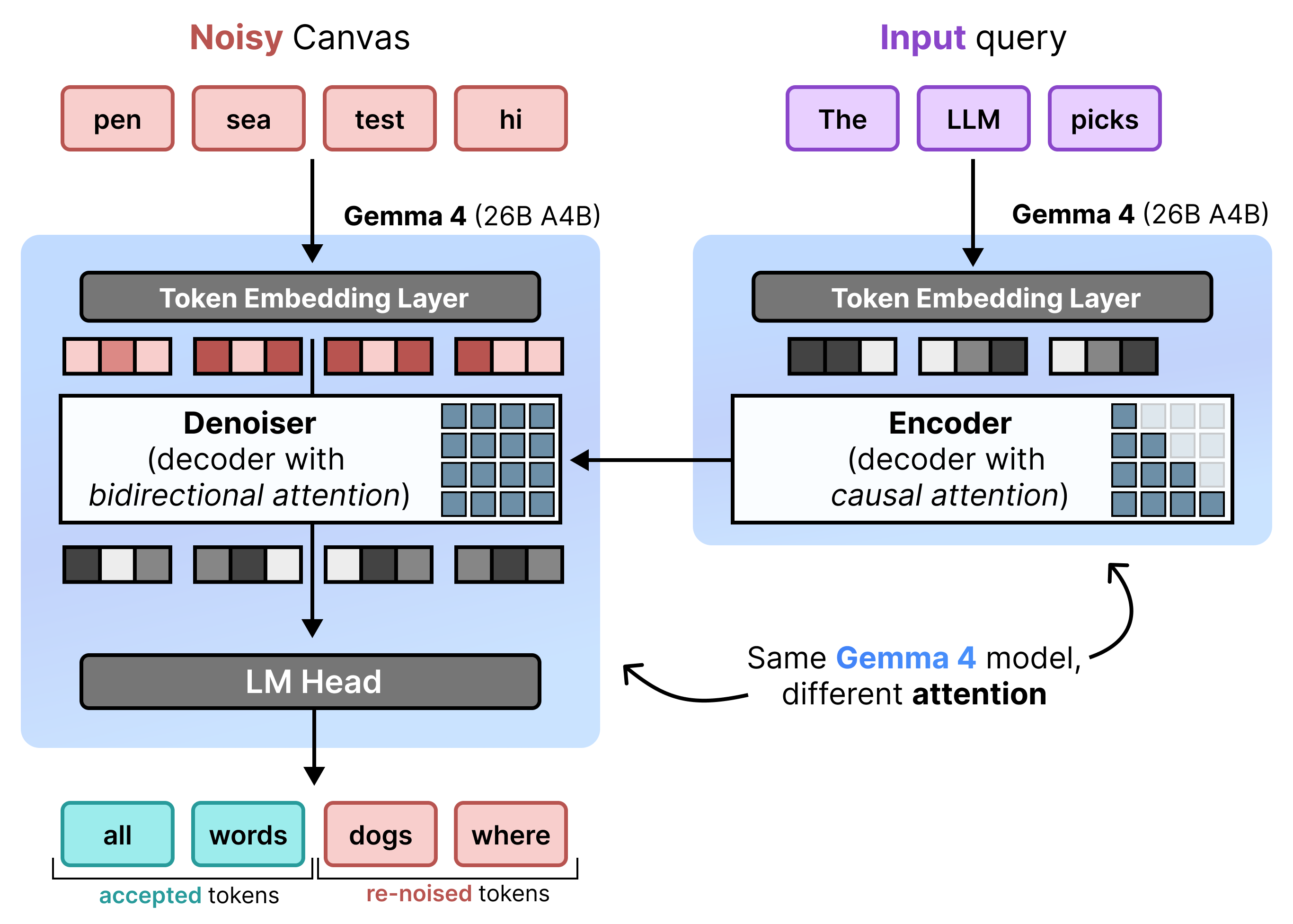
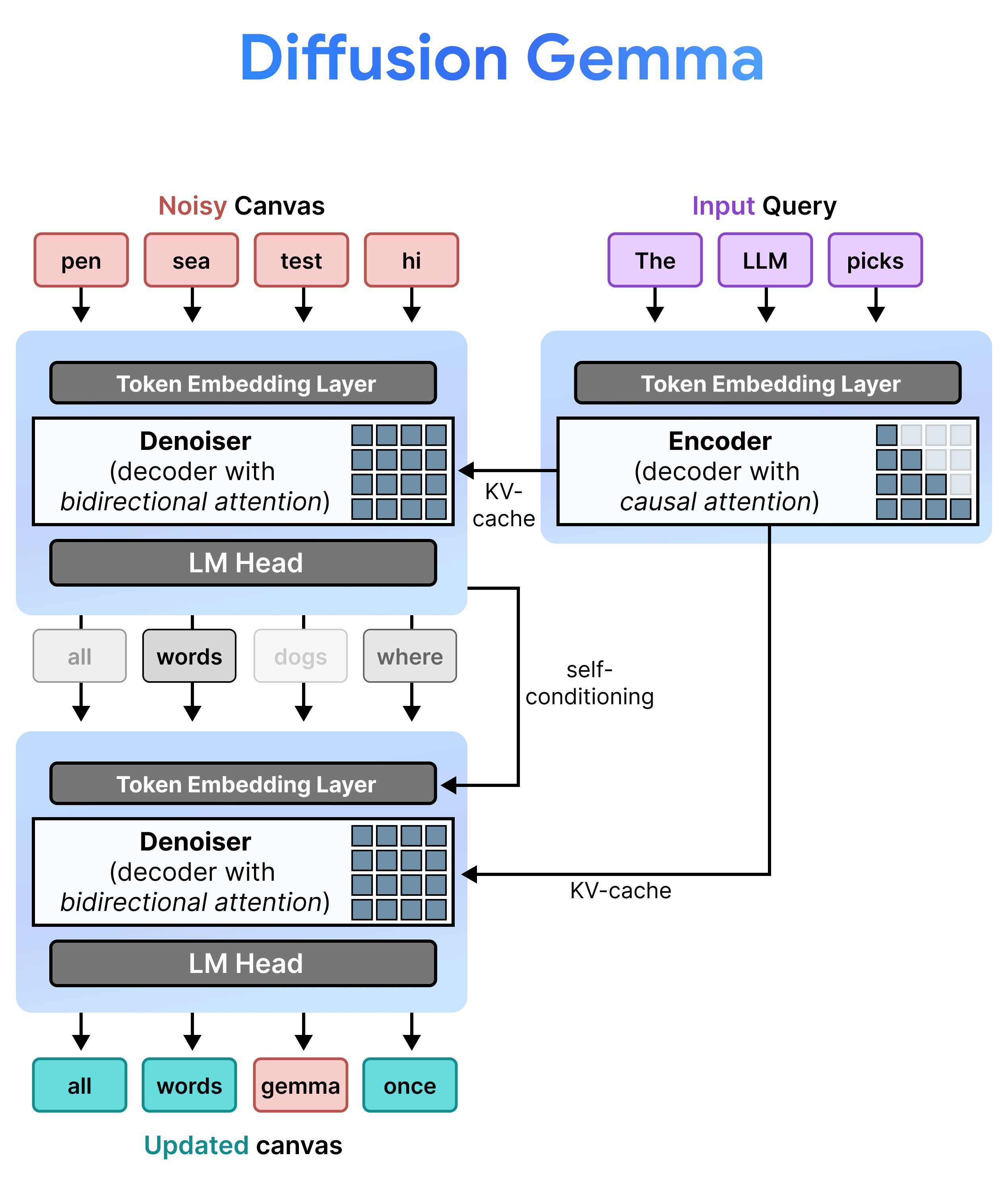
DiffusionGemma implementa la difusión de estados uniforme de manera eficiente alternando entre Incremental Prefill y Denoising. El modelo Gemma 4 26B A4B no se usa de forma nativa, sino que se ajusta para admitir las diferentes tareas de reducción de ruido y codificación. En lugar de usar modelos separados, una sola red troncal alterna dinámicamente entre dos modos:
- Prefill / Incremental Prefill (Causal): Usa la atención causal para incorporar el contexto de la instrucción y escribir en la caché de KV. Se ejecuta una vez para rellenar previamente el contexto inicial y, luego, una vez por bloque para agregar cada lienzo finalizado de 256 tokens a la caché de KV antes de continuar con la reducción de ruido del siguiente lienzo.
- Reducción de ruido (bidireccional): Utiliza la atención bidireccional para reducir el ruido del lienzo de forma iterativa. Los tokens de consulta en cualquier posición del lienzo pueden atender a todos los demás tokens del lienzo (así como a la caché de KV), lo que permite que el modelo procese el contexto de forma bidireccional.
Frameworks de inferencia avanzados
Para pasar de un lienzo de ruido puro a un texto finalizado, DiffusionGemma utiliza una colección de sistemas de decodificación subyacentes:
Self-Conditioning
Durante la inferencia, el decodificador (también conocido como eliminador de ruido) conserva su estado anterior. Después de completar un paso de reducción de ruido, multiplica su matriz de distribución de probabilidad generada por la tabla de incorporación de tokens. Esto produce una representación vectorial localizada que contiene un registro de sus predicciones a priori y métricas de confianza, que se pasa directamente al siguiente paso.
Muestreo de varios lienzos (difusión de bloques)
Dado que un solo lienzo se fija en 256 tokens, DiffusionGemma encadena la difusión y la autorregresión para el texto de formato largo. Ejecuta ciclos de difusión para generar un bloque completo de 256 tokens, agrega ese bloque completado al contexto de la instrucción, actualiza la caché de KV del codificador y comienza un nuevo ciclo de difusión de lienzo de 256 tokens.
Resumen
Los modelos de lenguaje autorregresivos estándar generan texto de forma secuencial (un token a la vez), lo que los limita en cuanto a la memoria y crea un cuello de botella de latencia para los usuarios individuales. DiffusionGemma resuelve este problema cambiando a un modelo vinculado a la capacidad de procesamiento que genera un "lienzo" completo de 256 tokens de forma simultánea.
Con Uniform State Diffusion, el modelo reemplaza el texto con ruido de vocabulario aleatorio y perfecciona de forma iterativa todo el lienzo en paralelo. Utiliza un modelo Gemma 4 26B A4B ajustado para admitir las diferentes tareas de reducción de ruido y codificación. Los frameworks avanzados, como el autocondicionamiento y el muestreo de bloques de múltiples lienzos, permiten que el modelo corrija errores de forma dinámica, controle la generación de formato largo y logre una latencia ultrabaja para un solo usuario.