
DiffusionGemma를 이해하려면 표준 언어 모델의 핵심 제한사항과 텍스트 기반 확산의 차이점을 살펴보는 것이 좋습니다.
자기 회귀 모델의 문제점
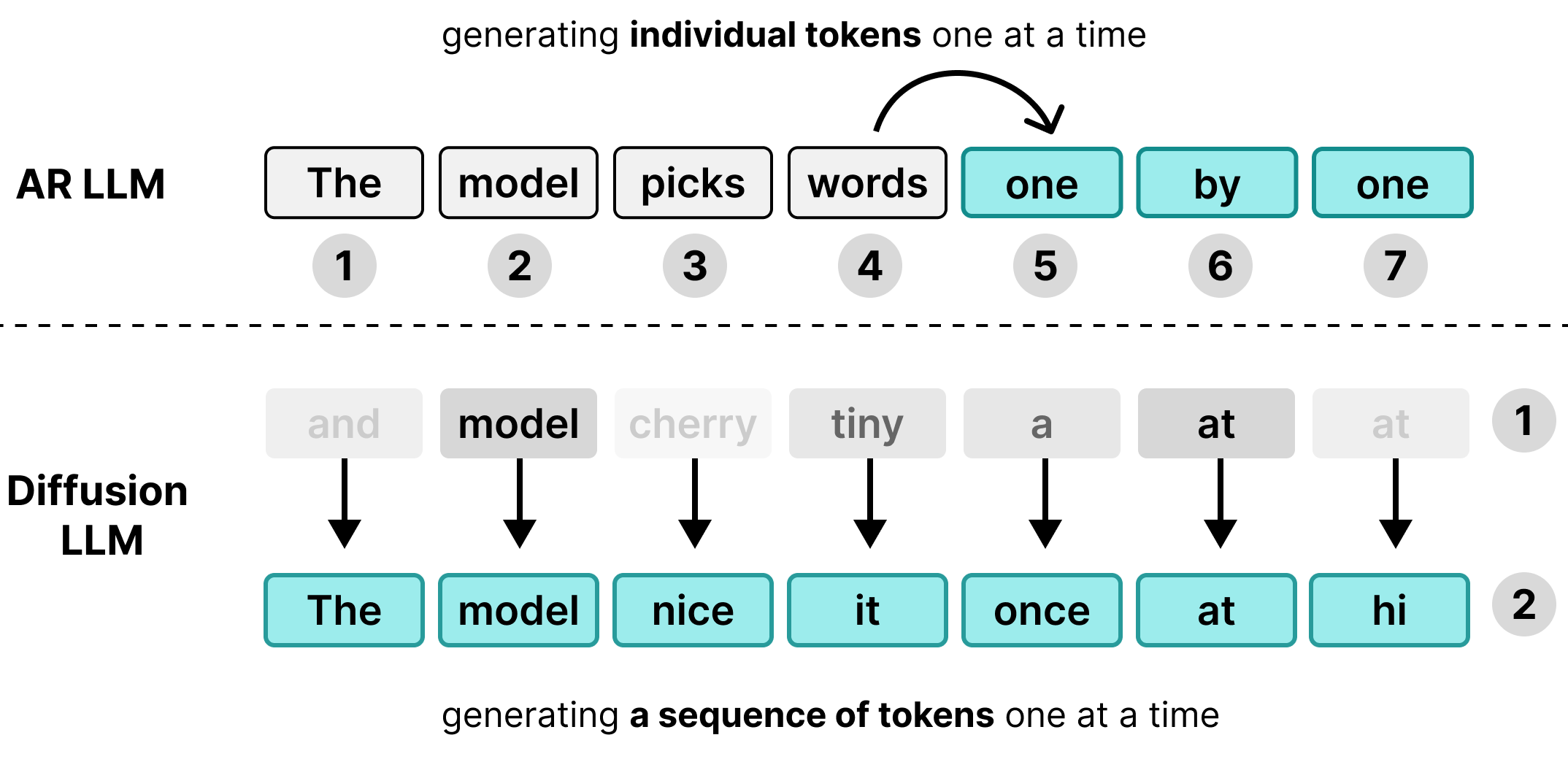
많은 대규모 언어 모델 (LLM)이 자기 회귀적입니다. 즉, 한 번에 하나의 토큰씩 텍스트를 생성합니다. 이 접근 방식은 일괄 처리를 통해 여러 사용자에게 동시에 서비스를 제공하는 데는 적합하지만 개별 사용자에게는 지연 시간 병목 현상을 일으킵니다.
디코딩 단계에서 표준 트랜스포머 모델은 컴퓨팅에 제한되기보다는 메모리에 제한됩니다. 생성 시간의 대부분은 실제 수학적 계산을 수행하는 대신 하드웨어 메모리에서 처리 단위로 모델 가중치를 로드하는 데 사용됩니다. 가중치는 배치 크기에 관계없이 단계당 한 번만 로드하면 되므로 토큰을 생성하는 데 걸리는 시간은 함께 그룹화된 256명의 사용자와 1명의 사용자가 거의 동일합니다.
따라서 개별 사용자는 지연 시간 이점을 누릴 수 없습니다. 메모리 전송을 기다리는 동안 하드웨어의 컴퓨팅 용량이 유휴 상태로 유지되기 때문입니다.
DiffusionGemma는 개인 사용자를 위해 이 유휴 컴퓨팅 시간을 활용합니다. 256명의 개별 사용자에 대해 토큰 1개를 생성하는 대신 단일 사용자에 대해 토큰 256개를 한 번에 생성합니다.
모델은 캔버스라고 하는 256개의 무작위 토큰의 빈 시퀀스를 초기화하고 전체 캔버스를 동시에 반복적으로 평가하고 개선합니다. 이렇게 하면 모델이 메모리 바운드에서 컴퓨팅 바운드로 전환되어 컴퓨팅 성능이 증가함에 따라 처리 속도를 효율적으로 확장할 수 있습니다.
| 부문 | 텍스트 자기 회귀 | 텍스트 확산 |
|---|---|---|
| 토큰 생성 | 한 번에 하나의 토큰 | 한 번에 토큰 전체 캔버스 |
| 단계 | 토큰당 한 단계 | 여러 토큰에 대한 한 단계 |
| 생성 순서 | 왼쪽에서 오른쪽으로 | 모든 위치를 병렬로 |
| 시작점 | 빈 시퀀스 | 어휘에서 샘플링된 무작위 토큰 |
| 오류 수정 | 정적이며 이전 토큰을 수정할 수 없습니다. | 동적입니다. 캔버스 위치를 수정할 수 있습니다. |
| 하드웨어 병목 현상 | 메모리 바운드 | 컴퓨팅 바운드 |
| 처리량 중심 | 높은 멀티 사용자 처리량 | 매우 짧은 단일 사용자 지연 시간 |
텍스트 확산 메커니즘 이해하기
이미지 생성에서 확산 모델은 100% 무작위 가우시안 노이즈로 시작하여 텍스트 프롬프트의 안내에 따라 여러 단계에 걸쳐 점진적으로 노이즈를 제거합니다. 텍스트 토큰은 연속적인 픽셀 값과 달리 이산적인 엔티티이므로 이 논리를 텍스트로 변환하는 것은 더 어렵습니다.
DiffusionGemma는 다음과 같은 전문 방법론을 통해 텍스트 기반 확산을 달성합니다.
1. Masked Diffusion
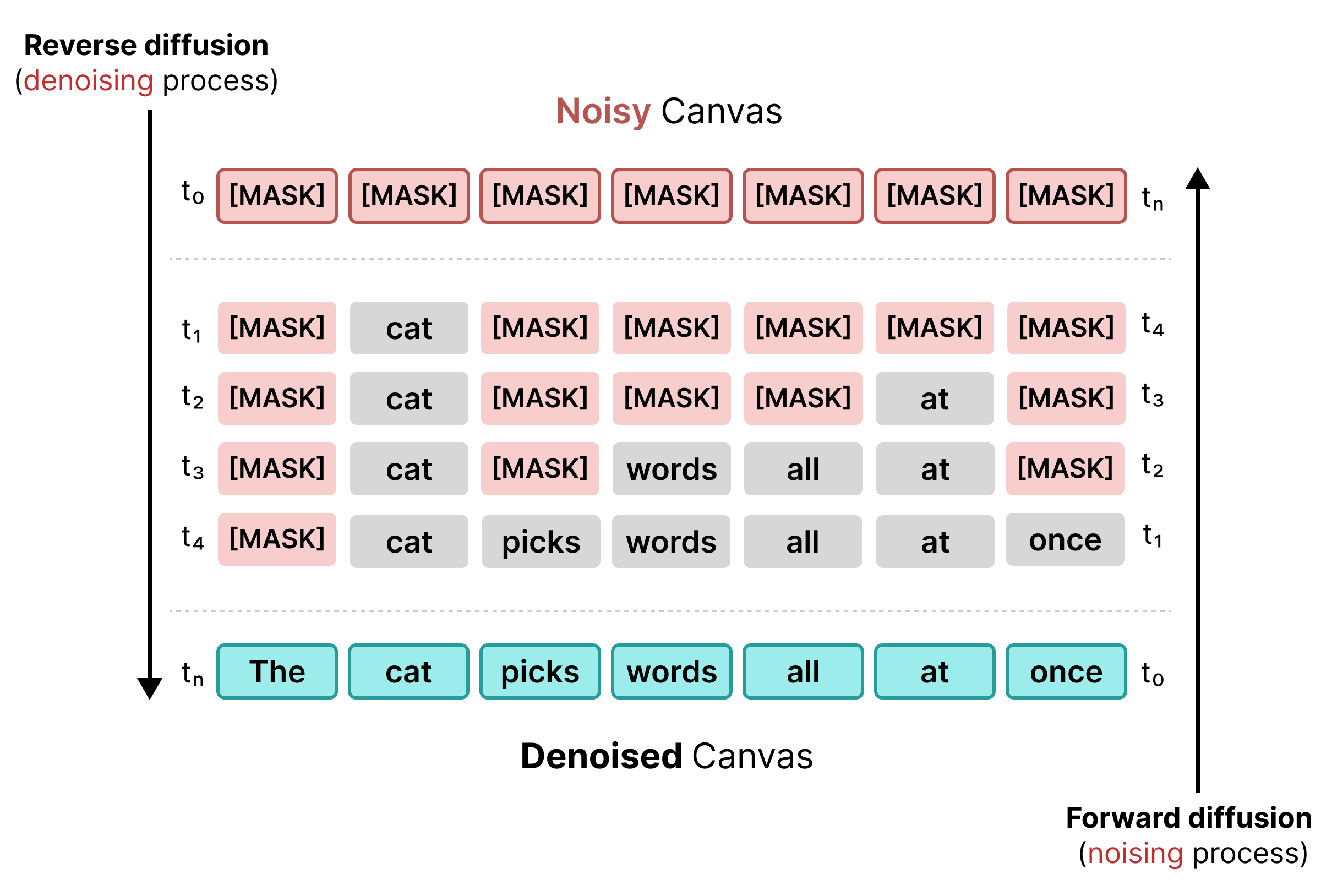
초기 텍스트 확산은 BERT 학습과 유사한 마스킹을 사용했습니다. 시퀀스의 무작위 토큰은 [MASK] 토큰 (노이즈를 나타냄)으로 대체됩니다. 역확산 중에 모델은 마스크 뒤에 있는 올바른 토큰을 예측하여 신뢰도가 특정 기준점을 충족하는 토큰을 대체합니다.
하지만 마스크 처리된 확산은 경직성이라는 문제가 있습니다. [MASK] 토큰이 단어로 대체되면 고정됩니다. 주변 컨텍스트가 변경되면 나중에 수정할 수 없습니다.
2. Uniform State Diffusion
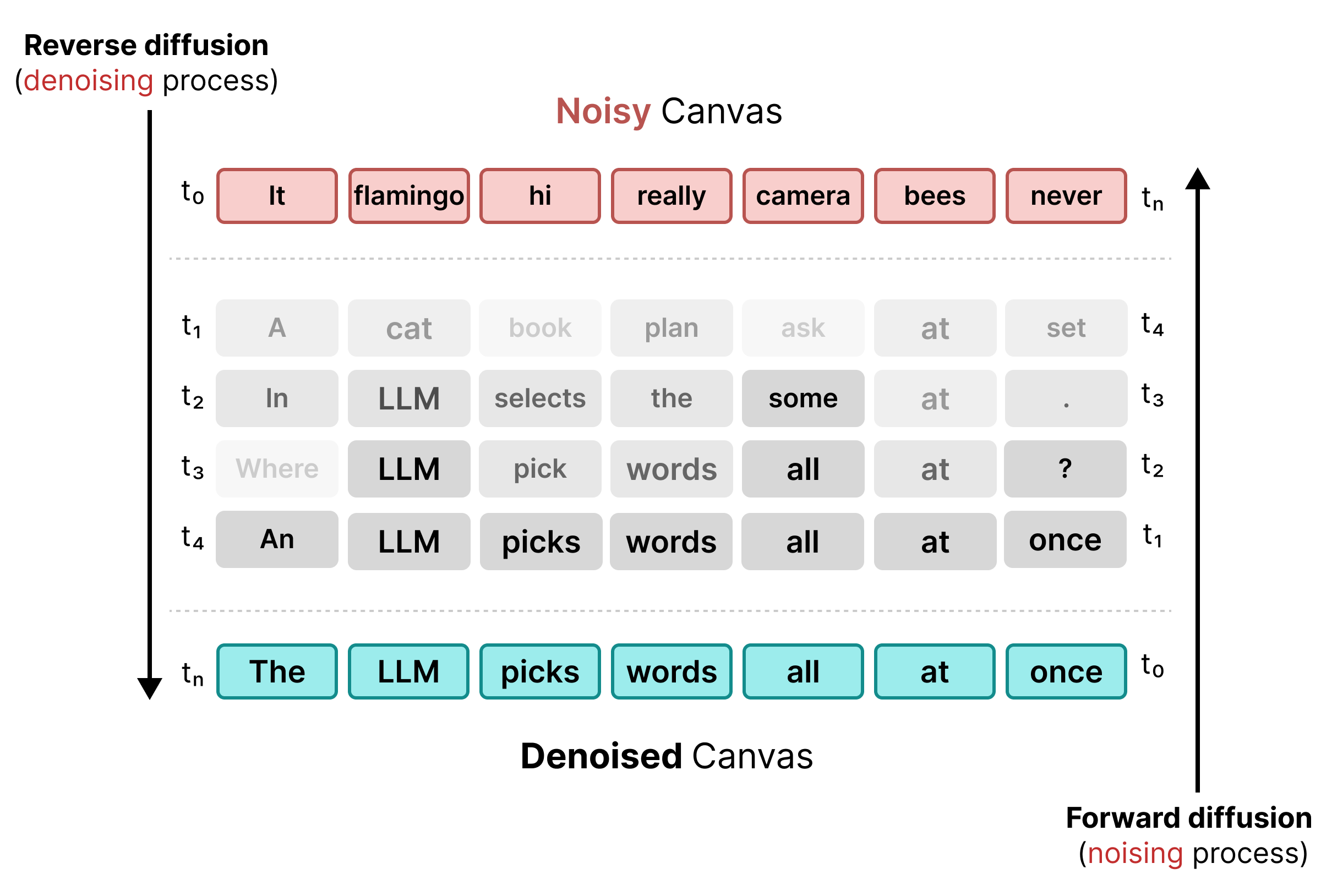
마스킹의 제한사항을 해결하기 위해 DiffusionGemma는 균일한 상태 확산을 사용합니다. 명시적인 [MASK] 토큰 대신 어휘에서 완전히 무작위 토큰으로 원래 단어를 대체하여 노이즈가 도입됩니다.
노이즈 제거 프로세스 중에 모델은 전체 캔버스를 분석하여 컨텍스트 노이즈인 토큰을 확인하고 업데이트합니다. 토큰이 올바르면 높은 확률이 유지됩니다. 후속 단계에서 새로운 컨텍스트가 등장하여 토큰의 확률이 기준점 아래로 떨어지면 새로운 무작위 토큰으로 다시 노이즈 처리됩니다. 이 사이클을 통해 지속적인 오류 수정과 병렬 캔버스 개선이 가능합니다.
아키텍처: 증분 자동 완성 및 노이즈 제거
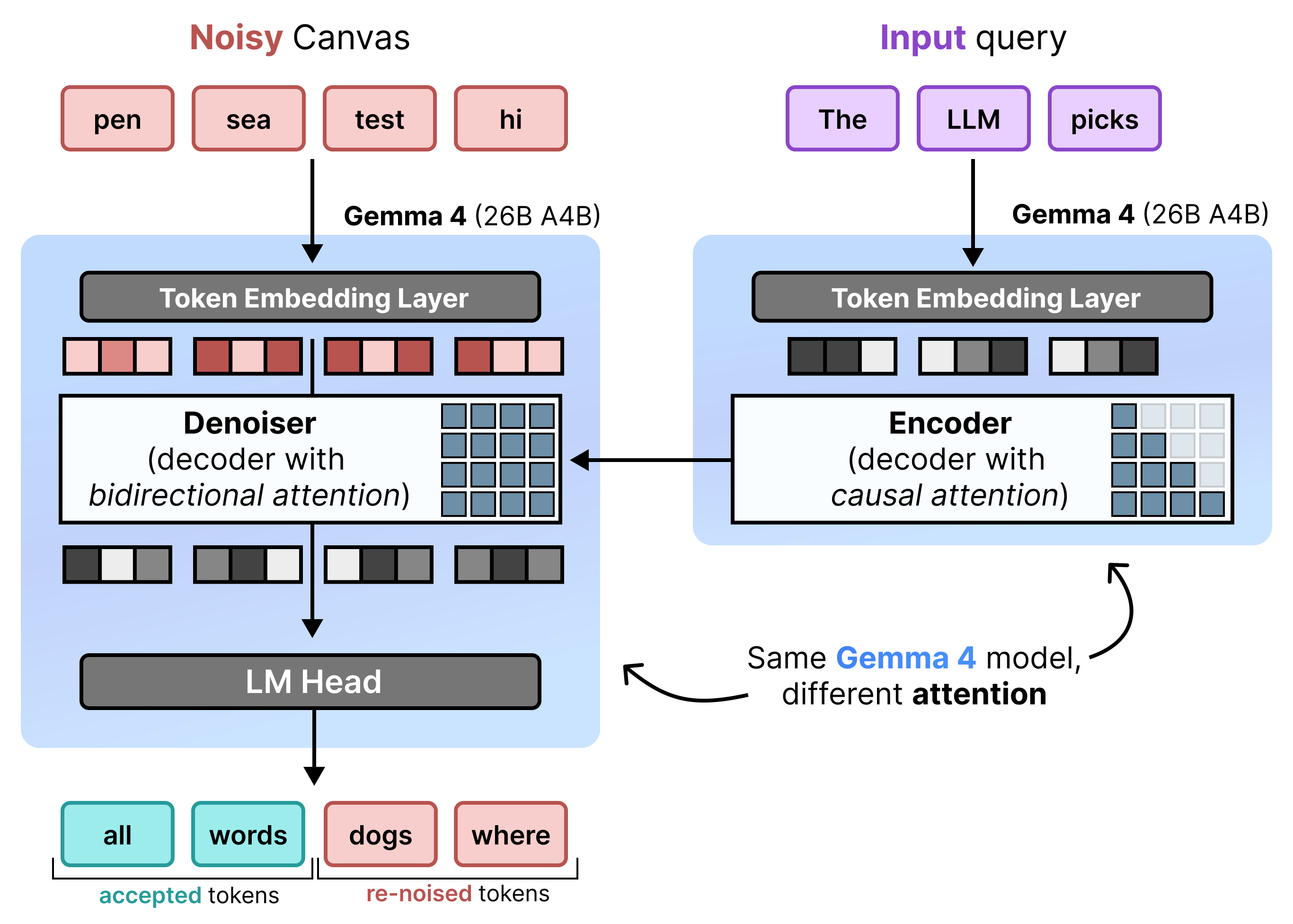
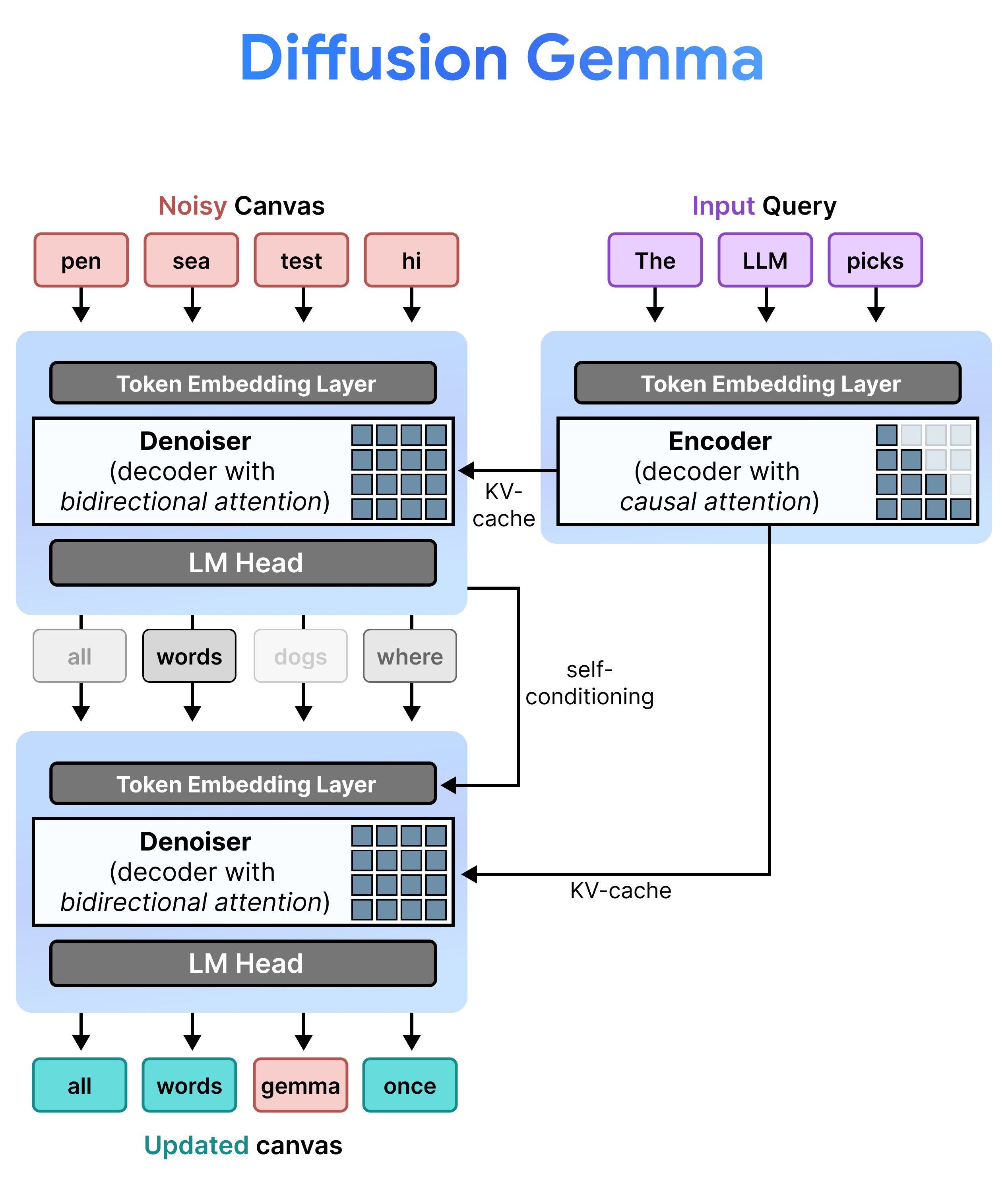
DiffusionGemma는 증분 사전 채우기와 노이즈 제거를 번갈아 가며 사용하여 균일한 상태 확산을 효율적으로 구현합니다. Gemma 4 26B A4B 모델은 기본적으로 사용되지 않지만 노이즈 제거 및 인코딩의 다양한 작업을 지원하도록 미세 조정됩니다. 별도의 모델을 사용하는 대신 단일 백본이 다음 두 모드 간에 동적으로 전환됩니다.
- 사전 입력 / 증분 사전 입력 (인과 관계): 인과 관계 어텐션을 사용하여 프롬프트 컨텍스트를 수집하고 KV 캐시에 씁니다. 이는 초기 컨텍스트를 미리 채우기 위해 한 번 실행되고, 다음 캔버스의 노이즈 제거를 진행하기 전에 각 최종 256 토큰 캔버스를 KV 캐시에 추가하기 위해 블록당 한 번 실행됩니다.
- 노이즈 제거 (양방향): 양방향 어텐션을 사용하여 캔버스의 노이즈를 반복적으로 제거합니다. 캔버스의 모든 위치에 있는 쿼리 토큰이 다른 모든 캔버스 토큰 (KV 캐시 포함)에 어텐션할 수 있으므로 모델이 컨텍스트를 양방향으로 처리할 수 있습니다.
고급 추론 프레임워크
캔버스를 순수한 노이즈에서 최종 텍스트로 이동하기 위해 DiffusionGemma는 다음과 같은 기본 디코딩 시스템 모음을 활용합니다.
자가 컨디셔닝
추론 중에 디코더 (디노이저라고도 함)는 이전 상태를 유지합니다. 노이즈 제거 단계를 완료한 후 생성된 확률 분포 행렬에 토큰 삽입 테이블을 곱합니다. 이렇게 하면 이전 예측과 신뢰도 측정항목의 메모리를 전달하는 현지화된 벡터 표현이 생성되며, 이는 다음 단계로 직접 전달됩니다.
다중 캔버스 샘플링 (블록 확산)
단일 캔버스는 256개의 토큰으로 고정되어 있으므로 DiffusionGemma는 긴 형식 텍스트를 위해 확산과 자동 회귀를 함께 연결합니다. 확산 주기를 실행하여 전체 256 토큰 블록을 생성하고, 완성된 블록을 프롬프트 컨텍스트에 추가하고, 인코더의 KV 캐시를 업데이트하고, 완전히 새로운 256 토큰 캔버스 확산 주기를 시작합니다.
요약
표준 자동 회귀 언어 모델은 텍스트를 순차적으로 (한 번에 하나의 토큰) 생성하므로 메모리 바운드되고 개별 사용자의 지연 시간 병목 현상이 발생합니다. DiffusionGemma는 전체 256 토큰 '캔버스'를 동시에 생성하는 컴퓨팅 바운드 모델로 전환하여 이 문제를 해결합니다.
Uniform State Diffusion을 활용하여 모델은 텍스트를 무작위 어휘 노이즈로 대체하고 전체 캔버스를 병렬로 반복적으로 미세 조정합니다. 미세 조정된 Gemma 4 26B A4B를 사용하여 노이즈 제거 및 인코딩의 다양한 작업을 지원합니다. 자기 조건화, 멀티 캔버스 블록 샘플링과 같은 고급 프레임워크를 통해 모델이 오류를 동적으로 수정하고, 긴 형식 생성을 처리하며, 초저 단일 사용자 지연 시간을 달성할 수 있습니다.