
Aby zrozumieć DiffusionGemma, warto przyjrzeć się głównym ograniczeniom standardowych modeli językowych i różnicom w stosunku do dyfuzji opartej na tekście.
Problem z modelami autoregresywnymi
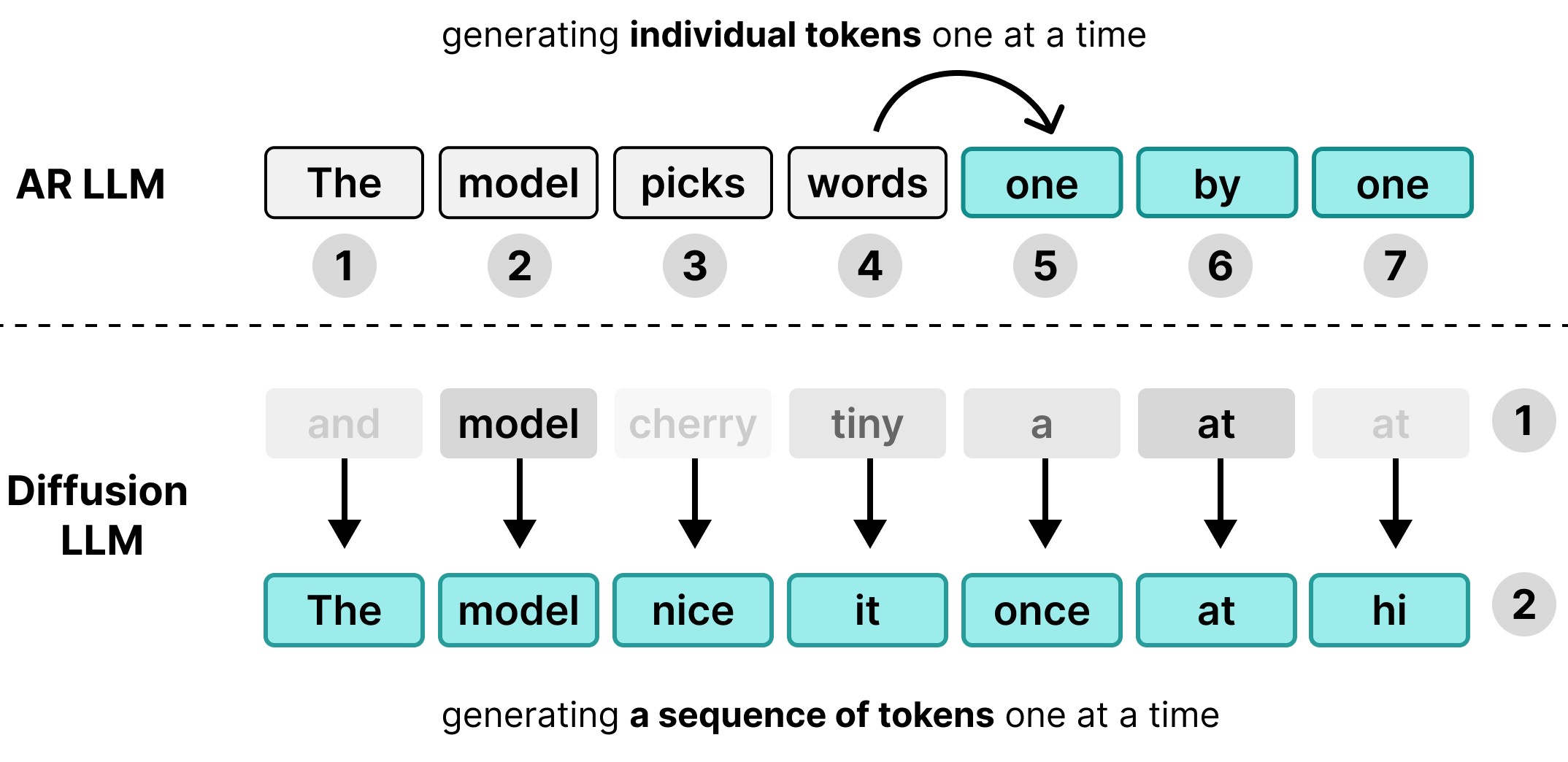
Wiele dużych modeli językowych (LLM) to modele autoregresywne, co oznacza, że generują tekst po jednym tokenie. Chociaż to podejście sprawdza się w przypadku obsługi wielu użytkowników jednocześnie za pomocą przetwarzania wsadowego, powoduje opóźnienia w przypadku poszczególnych użytkowników.
W fazie dekodowania standardowe modele transformera są ograniczone przez pamięć, a nie przez moc obliczeniową. Większość czasu generowania jest poświęcana na wczytywanie wag modelu z pamięci sprzętowej do jednostek przetwarzania, a nie na wykonywanie rzeczywistych obliczeń matematycznych. Ponieważ wagi muszą być wczytywane tylko raz na krok, niezależnie od wielkości wsadu, wygenerowanie tokena zajmuje prawie tyle samo czasu w przypadku 1 użytkownika, co w przypadku 256 użytkowników zgrupowanych razem.
W rezultacie pojedynczy użytkownik nie odczuwa żadnej korzyści związanej z mniejszym opóźnieniem. Moc obliczeniowa sprzętu jest nieużywana podczas oczekiwania na transfery pamięci.
DiffusionGemma wykorzystuje ten czas bezczynności na potrzeby poszczególnych użytkowników. Zamiast generować 1 token dla 256 osobnych użytkowników, generuje 256 tokenów naraz dla jednego użytkownika.
Model inicjuje pustą sekwencję 256 losowych tokenów, zwaną płótnem, i iteracyjnie ocenia oraz udoskonala całe płótno jednocześnie. Dzięki temu model przestaje być ograniczony przez pamięć i zaczyna być ograniczony przez moc obliczeniową, co pozwala mu efektywnie skalować szybkość przetwarzania wraz ze wzrostem mocy obliczeniowej.
| Aspekt | Autoregresja tekstu | Text Diffusion |
|---|---|---|
| Generowanie tokenów | Jeden token naraz | cały obszar roboczy z tokenami naraz, |
| Kroki | Jeden krok dla każdego tokena | Jeden krok dla wielu tokenów |
| Zamówienie generowania | Od lewej do prawej | Wszystkie pozycje równolegle |
| Punkt początkowy | Pusta sekwencja | Losowe tokeny próbkowane ze słownika |
| Korekcja błędów | Statyczne; nie można zmieniać tokenów z przeszłości | Dynamiczne; można zmienić dowolną pozycję elementu |
| Wąskie gardło sprzętowe | Ograniczone przez pamięć | zależne od mocy obliczeniowej, |
| Skupienie na przepustowości | Wysoka przepustowość w przypadku wielu użytkowników | Bardzo małe opóźnienie w przypadku jednego użytkownika |
Zrozumienie mechanizmów dyfuzji tekstu
W przypadku generowania obrazów modele dyfuzyjne zaczynają od całkowicie losowego szumu Gaussa i stopniowo go usuwają (odszumiają) w wielu krokach, kierując się promptem tekstowym. Przeniesienie tej logiki na tekst jest trudniejsze, ponieważ tokeny tekstowe są odrębnymi jednostkami, w przeciwieństwie do ciągłych wartości pikseli.
DiffusionGemma osiąga dyfuzję na podstawie tekstu dzięki zastosowaniu szeregu specjalistycznych metod:
1. Masked Diffusion
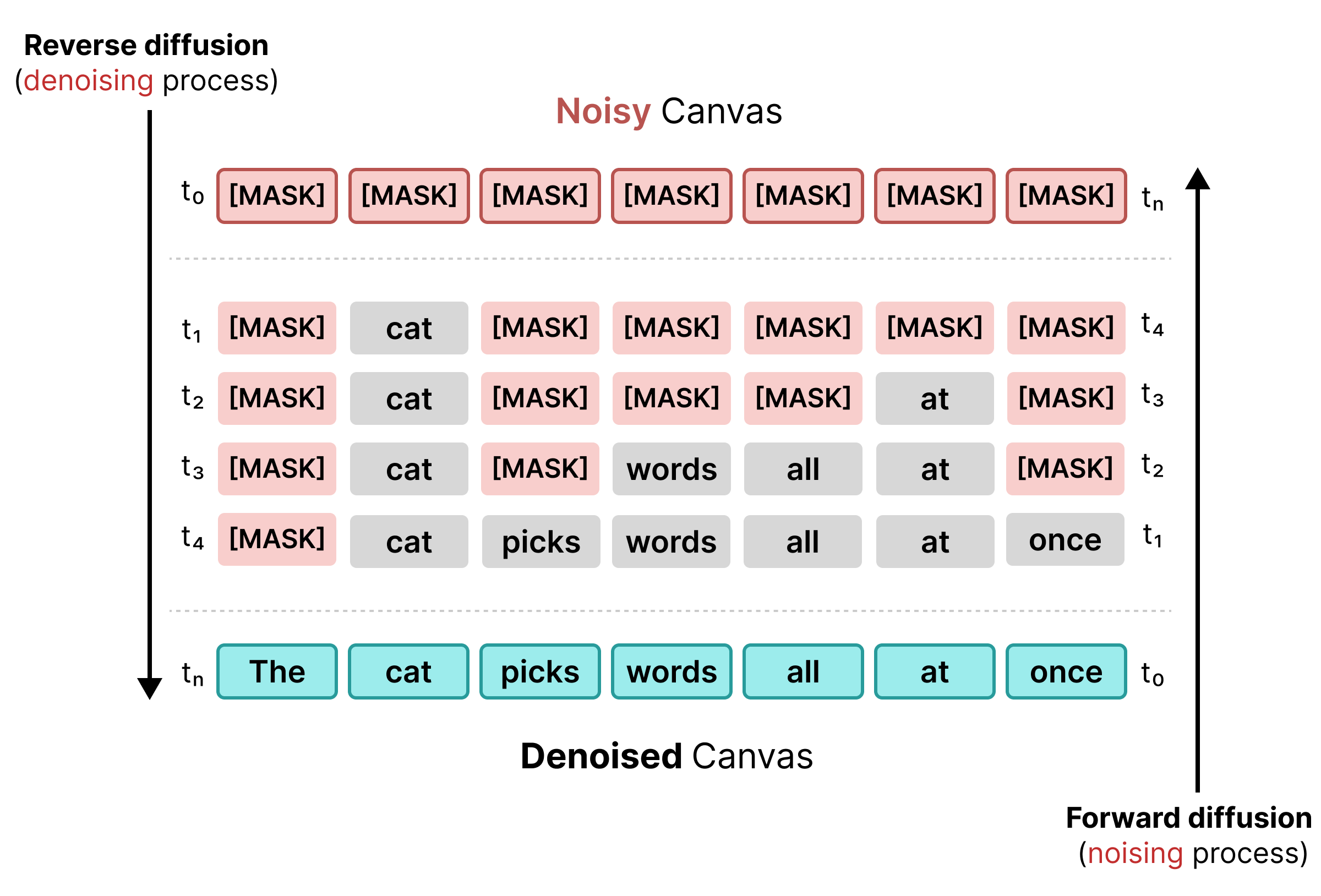
Wczesne modele dyfuzji tekstu opierały się na maskowaniu, podobnie jak trenowanie BERT. Losowe tokeny w sekwencji są zastępowane tokenem [MASK] (reprezentującym szum). Podczas odwróconej dyfuzji model przewiduje prawidłowy token za maską, zastępując tokeny, w przypadku których ufność osiąga określony próg.
Jednak zamaskowana dyfuzja jest sztywna: gdy token [MASK] zostanie zastąpiony słowem, nie można go już zmienić. Jeśli kontekst się zmieni, nie będzie można tego poprawić w późniejszych krokach.
2. Uniform State Diffusion
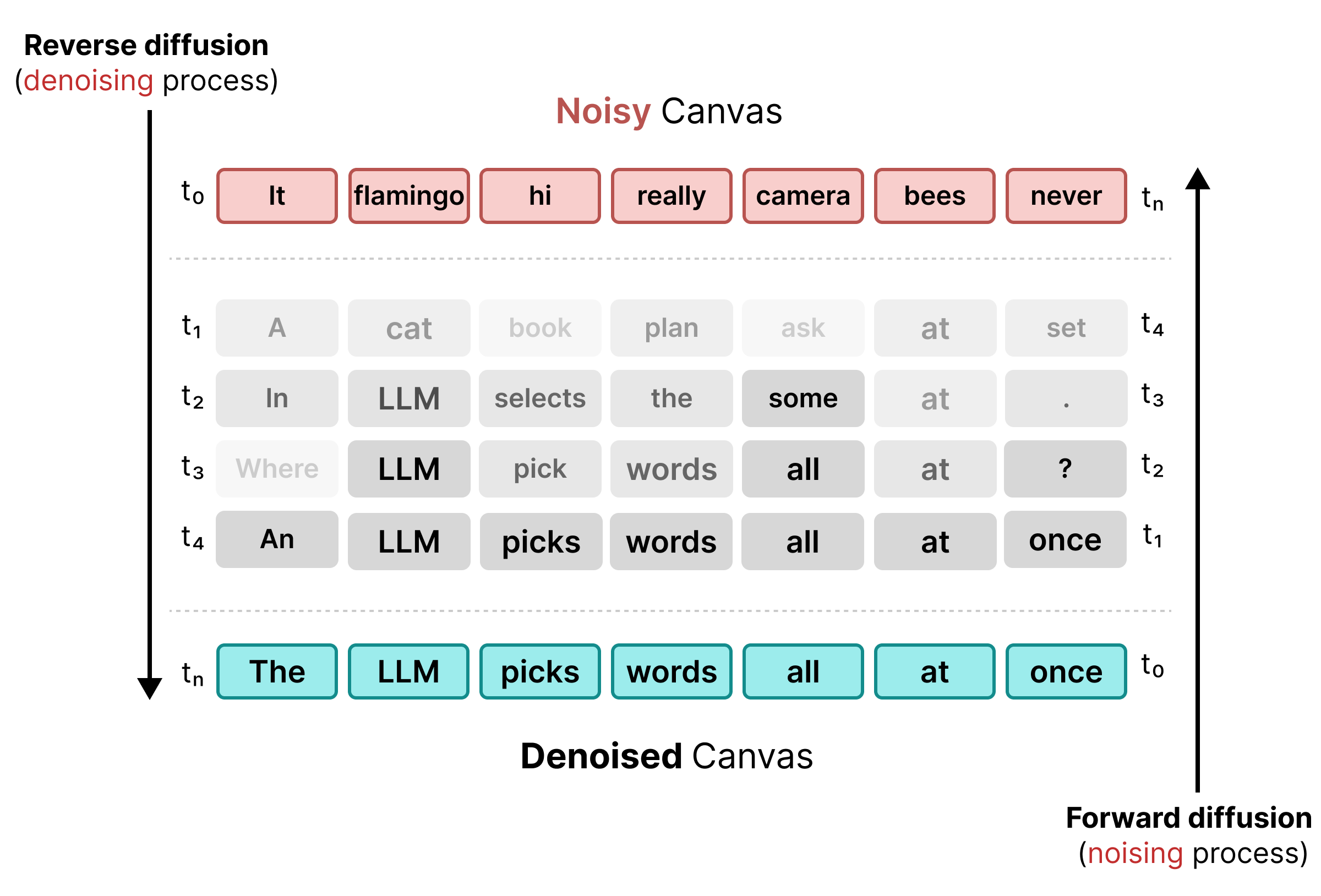
Aby rozwiązać problemy związane z maskowaniem, model DiffusionGemma wykorzystuje jednolite rozpraszanie stanu. Zamiast jawnego tokena [MASK] szum jest wprowadzany przez zastąpienie oryginalnych słów całkowicie losowymi tokenami ze słownika.
Podczas procesu odszumiania model analizuje całe płótno, aby określić, które tokeny są szumem kontekstowym, i je aktualizuje. Jeśli token jest prawidłowy, zachowuje wysokie prawdopodobieństwo. Jeśli prawdopodobieństwo wystąpienia tokena spadnie poniżej progu z powodu nowego kontekstu, który pojawi się w późniejszych krokach, zostanie on ponownie zaszumiony za pomocą nowego losowego tokena. Ten cykl umożliwia ciągłe korygowanie błędów i równoległe ulepszanie płótna.
Architektura: przyrostowe wstępne wypełnianie i odszumianie
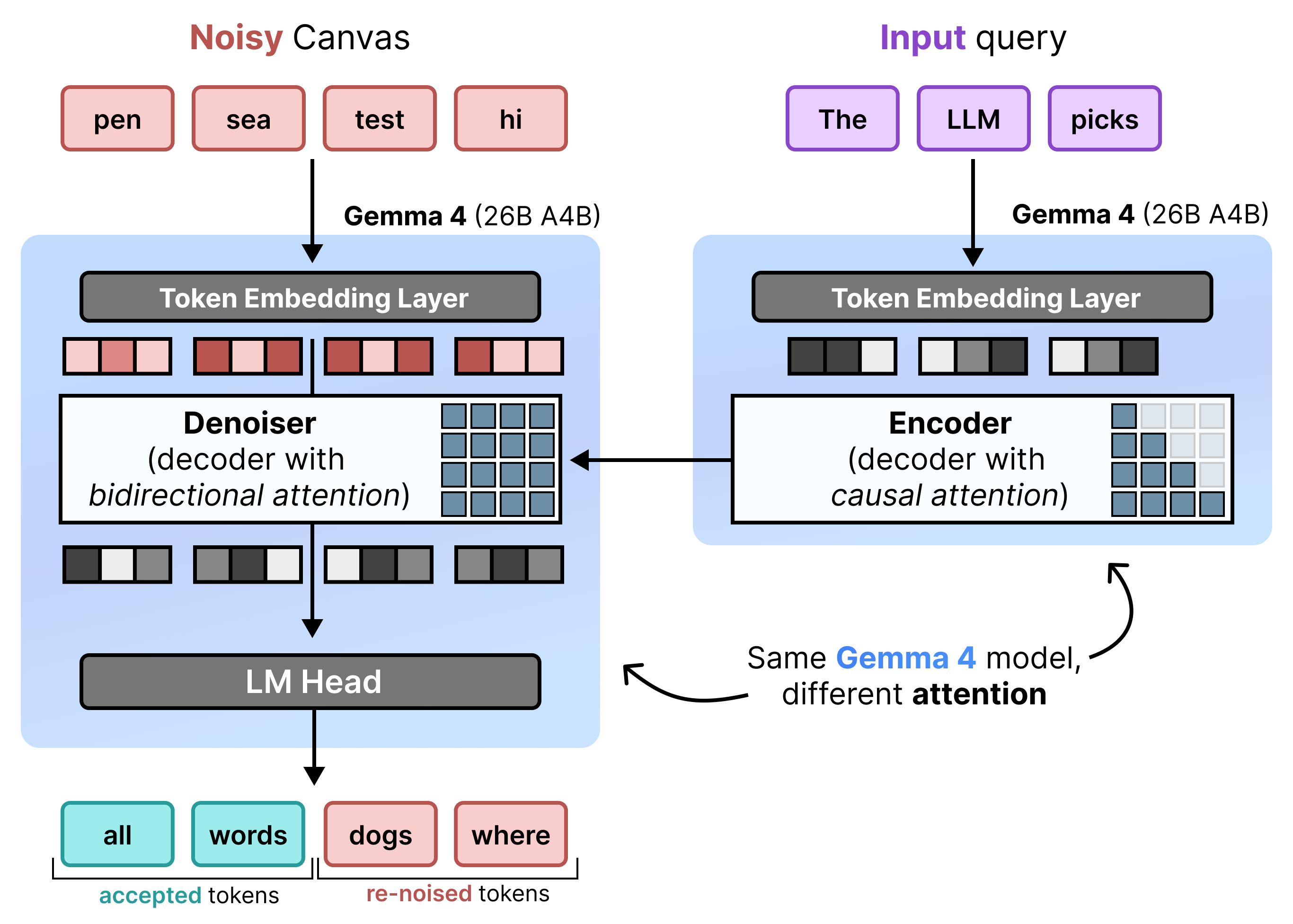
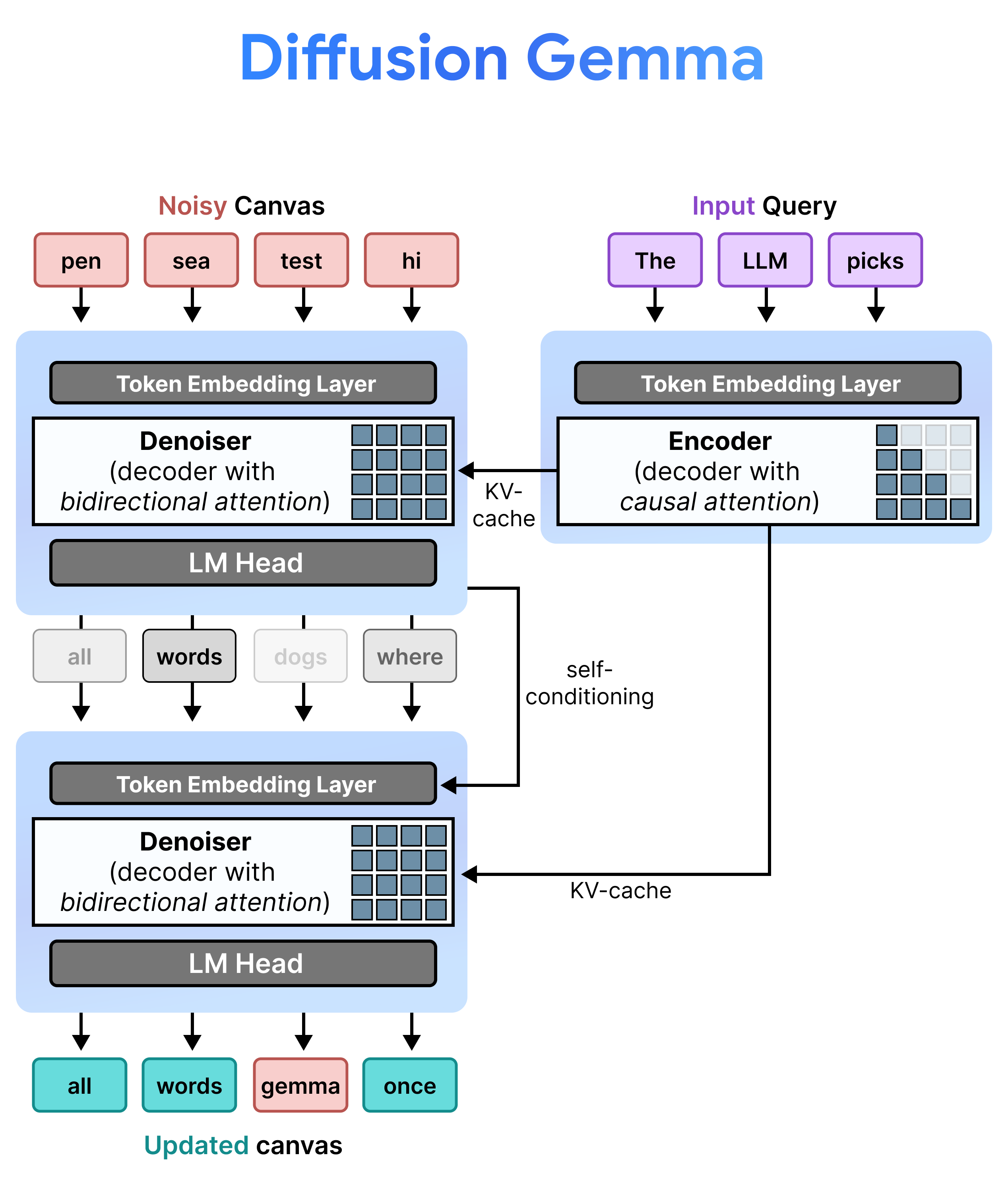
DiffusionGemma wydajnie implementuje ujednolicone rozpraszanie stanu, naprzemiennie stosując przyrostowe wstępne wypełnianie i odszumianie. Model Gemma 4 26B A4B nie jest używany natywnie, ale jest dostrajany do obsługi różnych zadań odszumiania i kodowania. Zamiast używać oddzielnych modeli, pojedynczy model podstawowy dynamicznie przełącza się między dwoma trybami:
- Wstępne wypełnianie / przyrostowe wstępne wypełnianie (przyczynowe): wykorzystuje przyczynową uwagę do wczytywania kontekstu promptu i zapisywania go w pamięci podręcznej klucz-wartość. Jest uruchamiane raz w celu wstępnego wypełnienia początkowego kontekstu, a potem raz na blok, aby dołączyć każdy ukończony 256-tokenowy obszar do pamięci podręcznej klucz-wartość przed przejściem do odszumiania następnego obszaru.
- Usuwanie szumu (dwukierunkowe): wykorzystuje dwukierunkową uwagę do iteracyjnego usuwania szumu z obszaru roboczego. Tokeny zapytania w dowolnej pozycji na obszarze roboczym mogą odnosić się do wszystkich innych tokenów obszaru roboczego (a także do pamięci podręcznej KV), co pozwala modelowi przetwarzać kontekst dwukierunkowo.
Zaawansowane platformy wnioskowania
Aby przekształcić obraz z szumu w gotowy tekst, DiffusionGemma korzysta z kolekcji podstawowych systemów dekodowania:
Samodzielne dostosowywanie
Podczas wnioskowania dekoder (zwany też odszumianiem) zachowuje swój poprzedni stan. Po zakończeniu kroku odszumiania mnoży wygenerowaną macierz rozkładu prawdopodobieństwa przez tabelę osadzania tokenów. W ten sposób powstaje zlokalizowana reprezentacja wektorowa zawierająca pamięć poprzednich prognoz i wskaźniki ufności, która jest przekazywana bezpośrednio do następnego kroku.
Próbkowanie na wielu obszarach roboczych (rozpraszanie blokowe)
Pojedyncze płótno ma 256 tokenów, dlatego DiffusionGemma łączy dyfuzję i autoregresję w przypadku długich tekstów. Wykonuje cykle dyfuzji, aby wygenerować pełny blok 256 tokenów, dołącza ten blok do kontekstu promptu, aktualizuje pamięć podręczną KV enkodera i rozpoczyna nowy cykl dyfuzji płótna o długości 256 tokenów.
Podsumowanie
Standardowe autoregresywne modele językowe generują tekst sekwencyjnie (po jednym tokenie), co ogranicza ich pamięć i powoduje opóźnienia u poszczególnych użytkowników. DiffusionGemma rozwiązuje ten problem, przechodząc na model ograniczony przez moc obliczeniową, który generuje jednocześnie pełne 256-tokenowe „płótno”.
Dzięki wykorzystaniu jednolitej dyfuzji stanu model zastępuje tekst losowym szumem słownictwa i iteracyjnie udoskonala całą przestrzeń roboczą równolegle. Do obsługi różnych zadań odszumiania i kodowania wykorzystuje dostrojony model Gemma 4 26B A4B. Zaawansowane struktury, takie jak samokondycjonowanie i próbkowanie bloków na wielu obszarach roboczych, umożliwiają modelowi dynamiczne korygowanie błędów, obsługę generowania długich form i osiąganie bardzo niskiego opóźnienia dla pojedynczego użytkownika.