
Для понимания DiffusionGemma полезно изучить основные ограничения стандартных языковых моделей и то, чем отличается распространение информации на основе текста.
Проблема авторегрессионных моделей
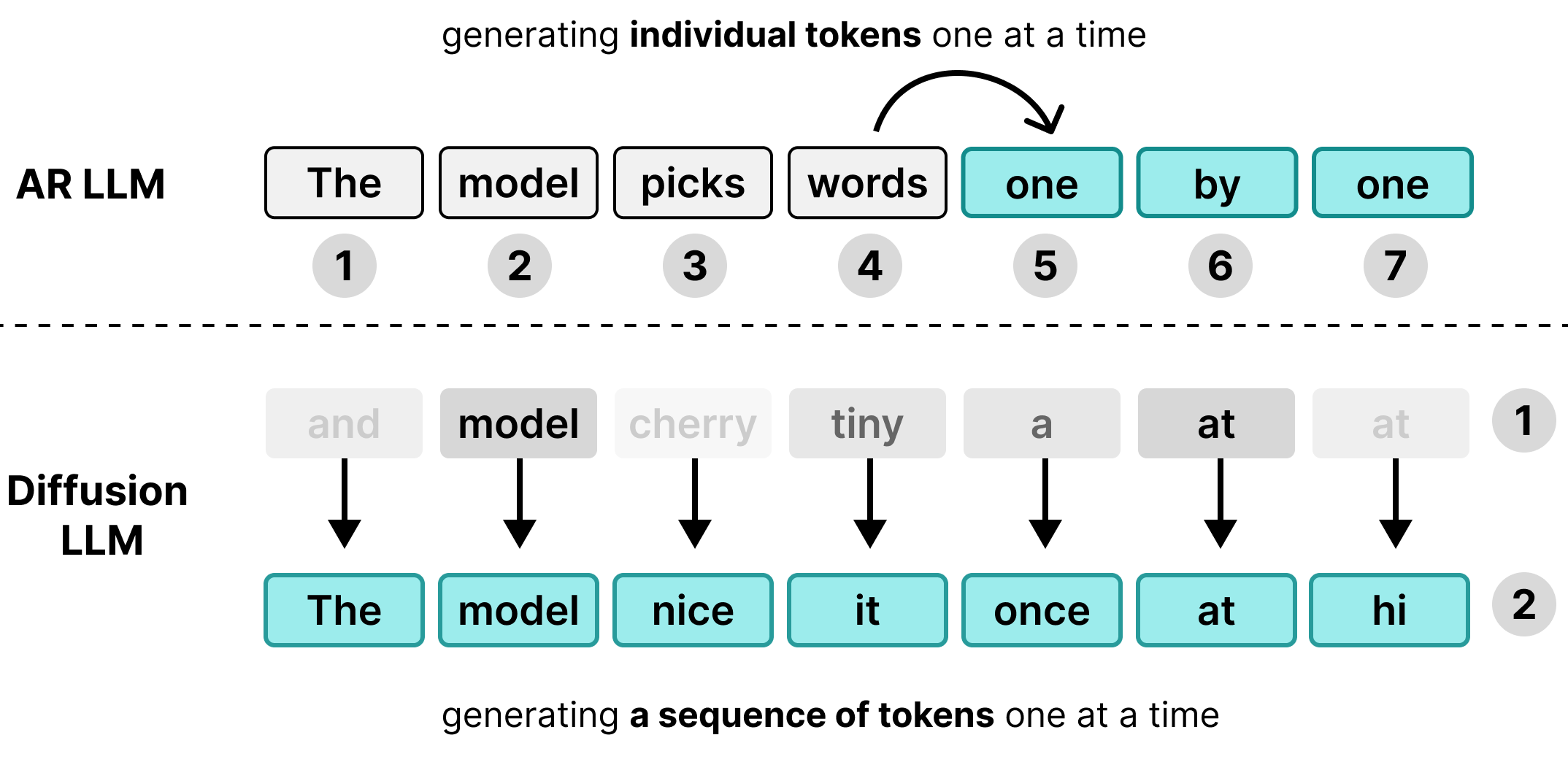
Многие большие языковые модели (LLM) являются авторегрессивными , то есть генерируют текст по одному токену за раз. Хотя такой подход хорошо работает для одновременной обработки большого количества пользователей с помощью пакетной обработки, он создает узкое место в виде задержки для отдельных пользователей.
На этапе декодирования стандартные модели Transformer ограничены объемом памяти, а не вычислительными ресурсами. Большая часть времени генерации тратится на загрузку весов модели из аппаратной памяти в процессоры, а не на выполнение самих математических вычислений. Поскольку веса необходимо загружать только один раз за шаг независимо от размера пакета, генерация токена занимает почти одинаковое время как для одного пользователя, так и для 256 пользователей, объединенных в группу.
Следовательно, отдельный пользователь не видит никаких преимуществ в плане задержки; вычислительные мощности оборудования простаивают, ожидая передачи данных в память.
DiffusionGemma использует это свободное вычислительное время для каждого отдельного пользователя. Вместо генерации одного токена для 256 отдельных пользователей, она генерирует 256 токенов одновременно для одного пользователя.
Модель инициализирует пустую последовательность из 256 случайных токенов — так называемый холст — и итеративно оценивает и уточняет весь холст одновременно. Это переводит модель из разряда моделей, зависящих от памяти, в разряд моделей, зависящих от вычислительных ресурсов , что позволяет ей эффективно масштабировать скорость обработки по мере увеличения вычислительной мощности.
| Аспект | Авторегрессия текста | Распространение текста |
|---|---|---|
| Генерация токенов | По одному жетону за раз | Целое полотно из токенов одновременно |
| Шаги | Один шаг для каждого токена | Один шаг для нескольких токенов |
| Порядок поколений | Слева направо | Все позиции параллельно |
| Отправная точка | Пустая последовательность | Случайные токены, выбранные из словаря. |
| Исправление ошибок | Статический; нельзя изменить прошлые токены. | Динамичный; позволяет изменять положение любого элемента холста. |
| Аппаратное узкое место | Ограниченный памятью | Ограниченная вычислительная мощность |
| Фокус на пропускной способности | Высокая пропускная способность для нескольких пользователей | Сверхнизкая задержка для одного пользователя |
Понимание механики распространения текста
В моделях генерации изображений диффузионные модели начинаются со 100% случайного гауссова шума и постепенно удаляют его (шумоподавление) в несколько этапов, руководствуясь текстовой подсказкой. Перевод этой логики в текст представляет собой более сложную задачу, поскольку текстовые токены являются дискретными сущностями, в отличие от непрерывных значений пикселей.
DiffusionGemma осуществляет распространение информации на основе текста с помощью ряда специализированных методик:
1. Маскированная диффузия
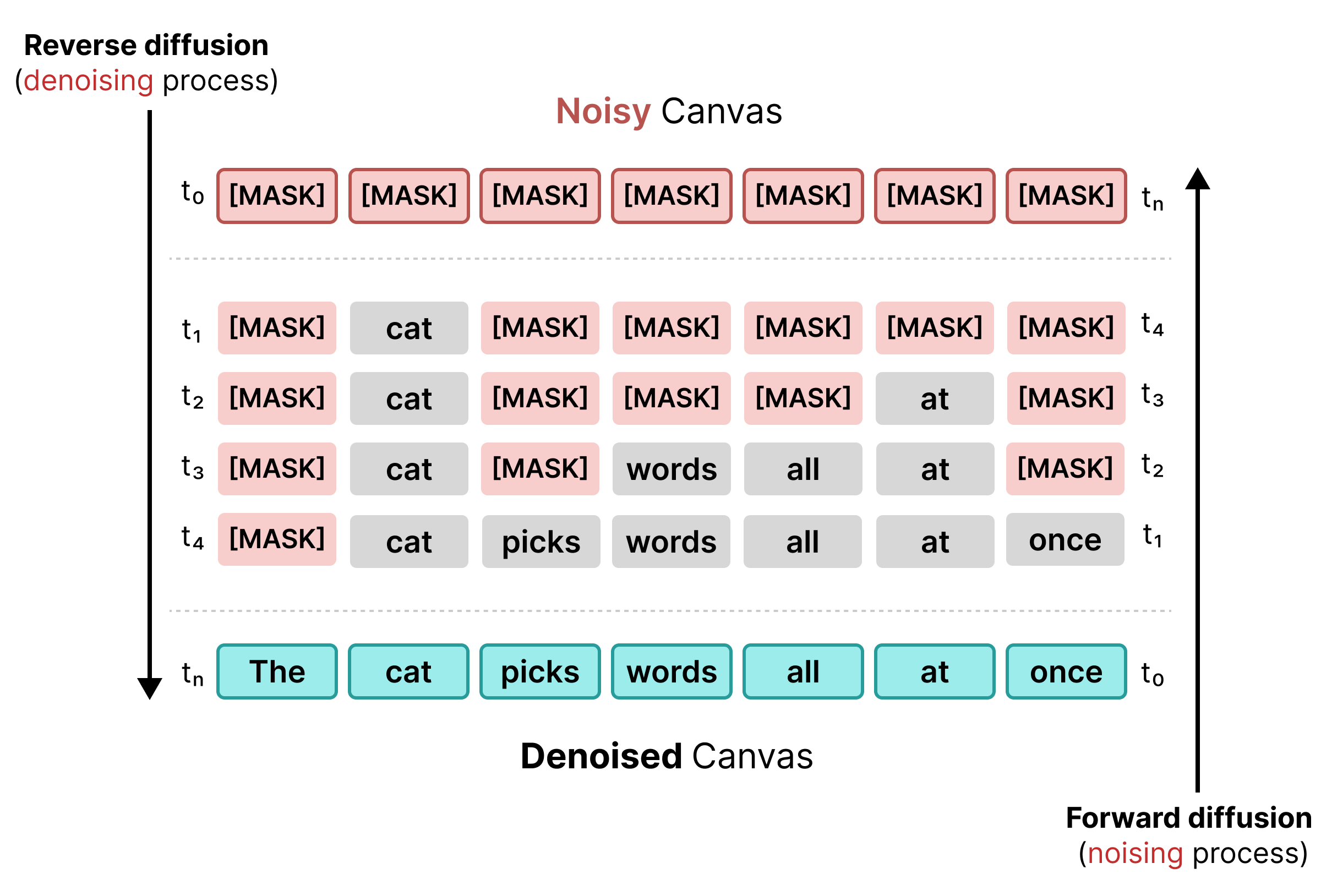
Ранние методы распространения текста основывались на маскировании, аналогично обучению BERT. Случайные токены в последовательности заменяются токеном [MASK] (представляющим шум). При обратном распространении модель предсказывает правильный токен за маской, заменяя токены там, где уровень достоверности соответствует определенному пороговому значению.
Однако маскированная диффузия страдает от жесткости: как только токен [MASK] заменяется словом, он фиксируется. Его нельзя исправить на последующих этапах, если изменится окружающий контекст.
2. Диффузия в равномерном состоянии
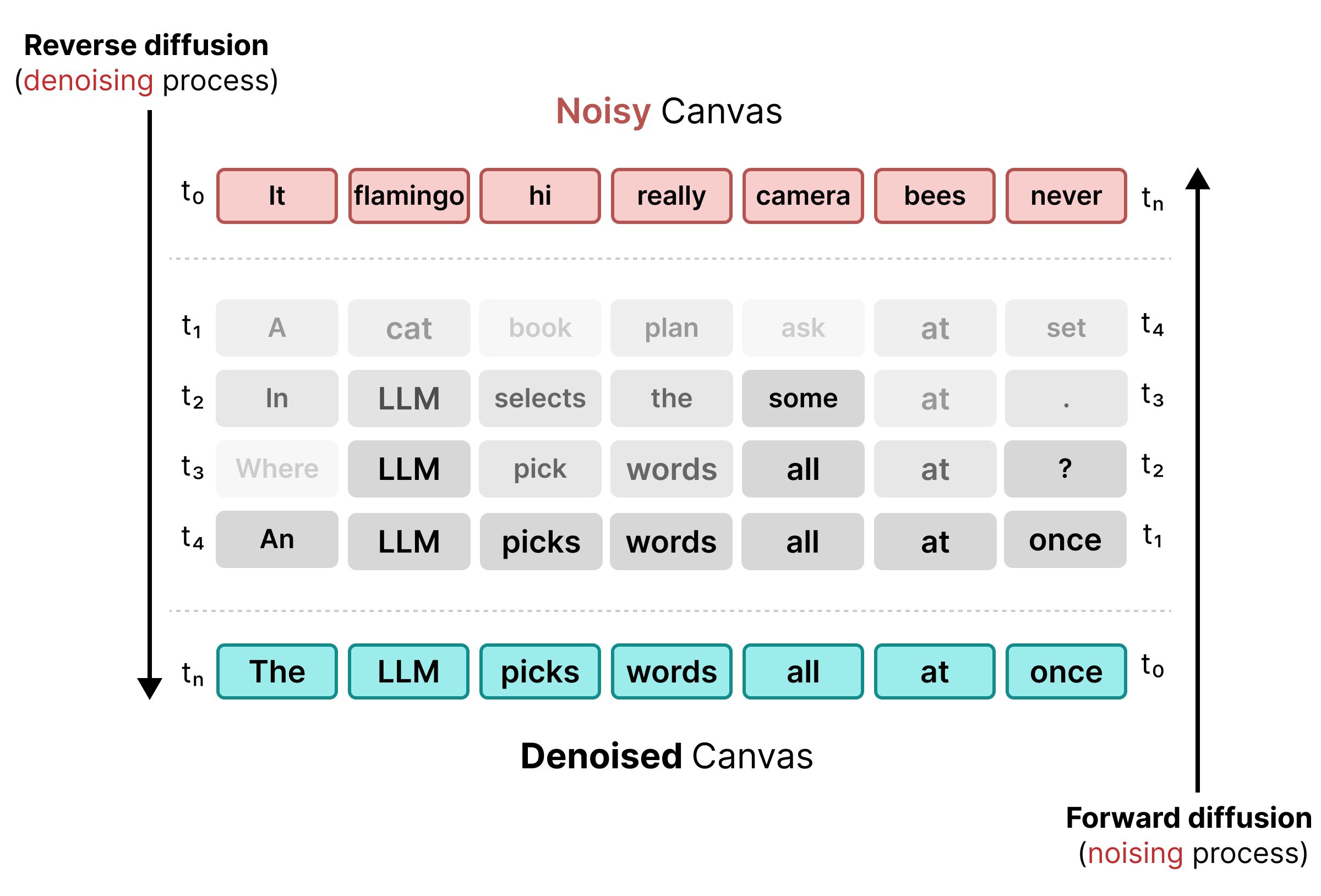
Для преодоления ограничений маскирования DiffusionGemma использует равномерное распределение состояний . Вместо явного токена [MASK] шум вводится путем замены исходных слов полностью случайными токенами из словаря.
В процессе шумоподавления модель анализирует весь холст, чтобы определить, какие токены представляют собой контекстный шум, и обновляет их. Если токен правильный, он сохраняет высокую вероятность. Если вероятность токена падает ниже порогового значения из-за появления нового контекста на последующих этапах, он повторно шумоподавляется с помощью нового случайного токена. Этот цикл позволяет непрерывно исправлять ошибки и параллельно уточнять холст.
Архитектура: поэтапное предварительное заполнение и шумоподавление.
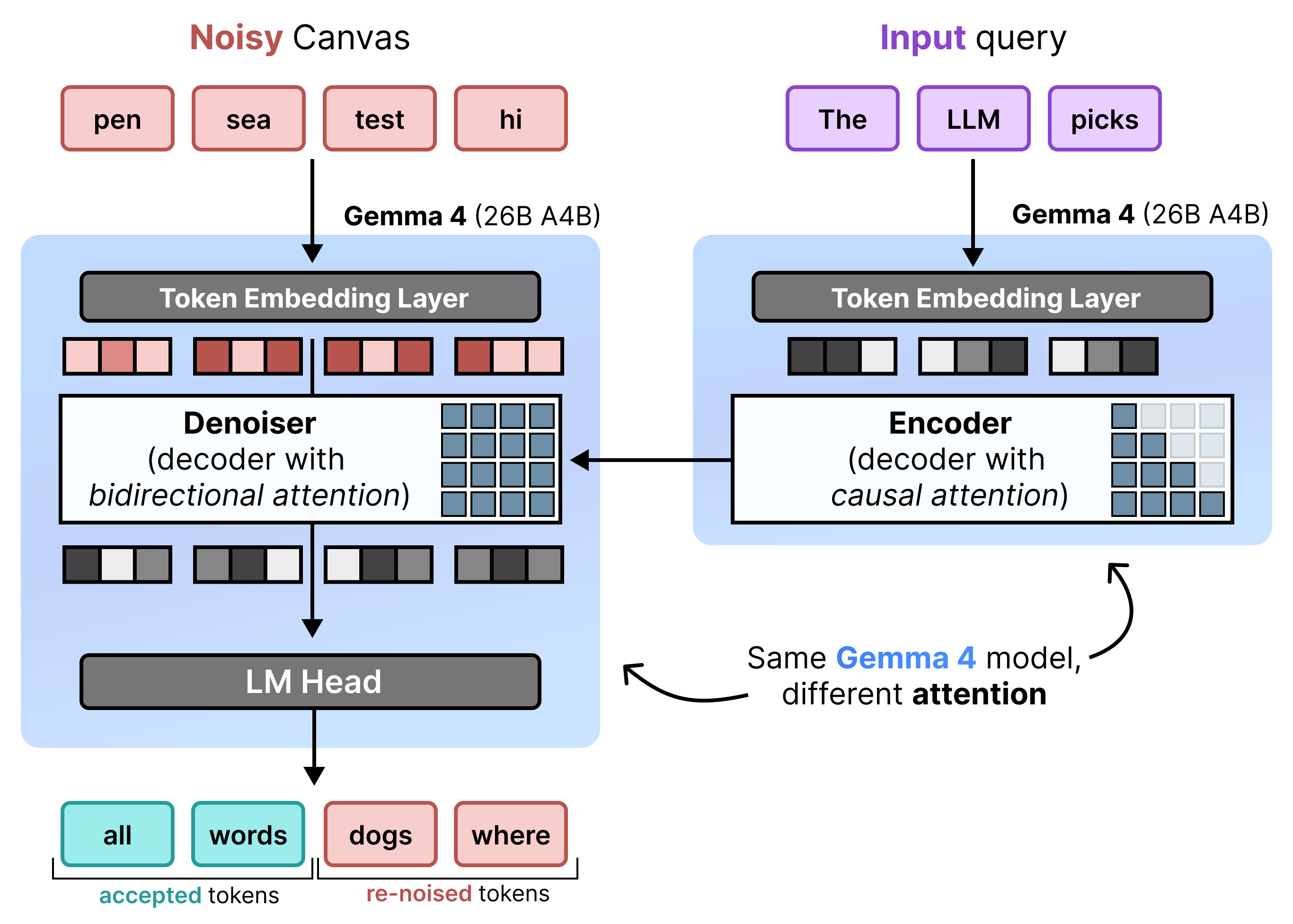
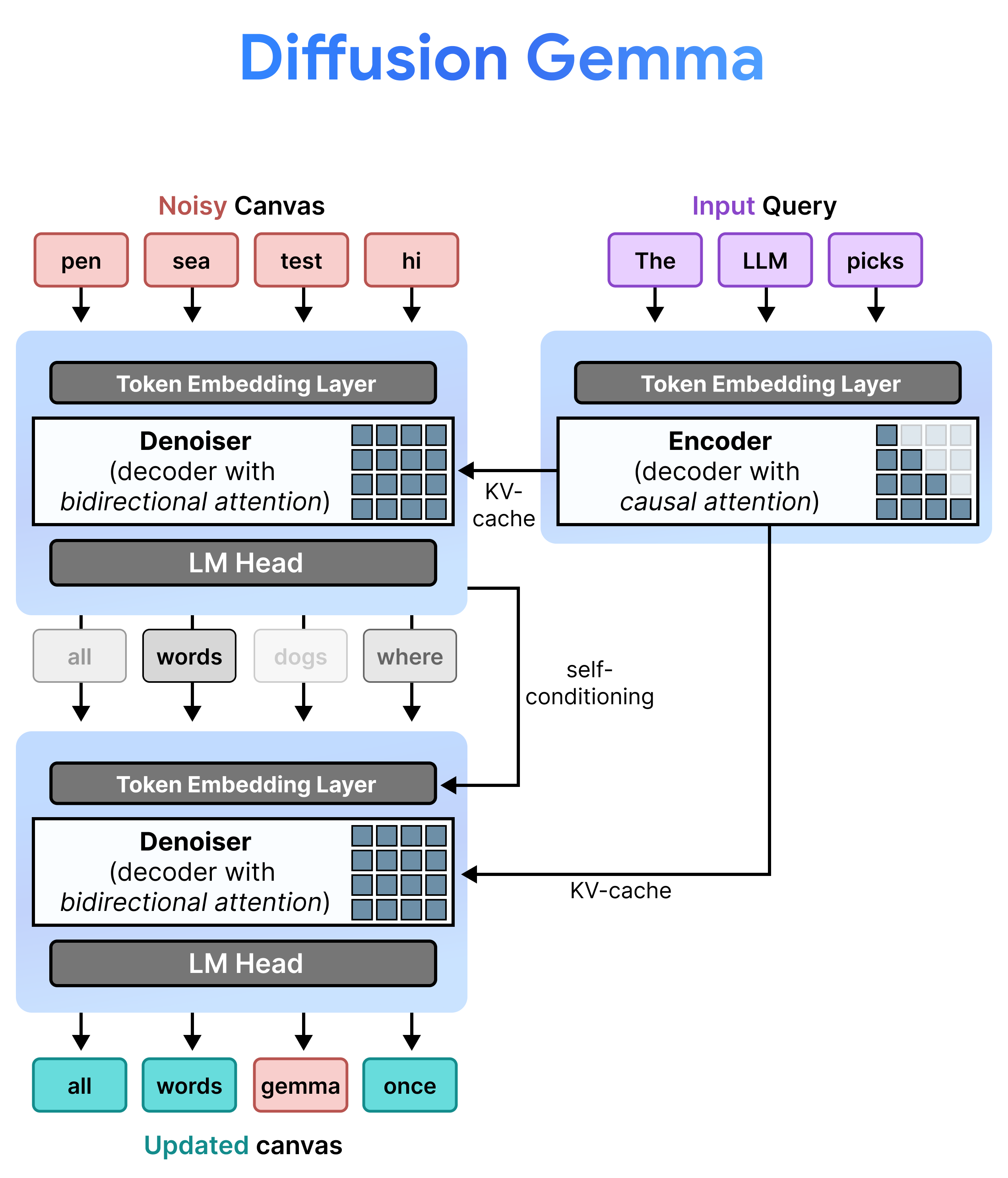
DiffusionGemma эффективно реализует равномерное распределение состояний, чередуя инкрементальное предварительное заполнение и шумоподавление . Модель Gemma 4 26B A4B не используется изначально, но тонко настроена для поддержки различных задач шумоподавления и кодирования. Вместо использования отдельных моделей, единая архитектура динамически переключается между двумя режимами:
- Предварительное заполнение / Инкрементальное предварительное заполнение (причинно-следственное): Использует причинно-следственное внимание для обработки контекста подсказки и записи в кэш ключ-значение. Этот процесс выполняется один раз для предварительного заполнения начального контекста, а затем один раз для каждого блока, чтобы добавить каждый завершенный холст из 256 токенов в кэш ключ-значение перед переходом к шумоподавлению следующего холста.
- Шумоподавление (двунаправленное): Использует двунаправленное внимание для итеративного шумоподавления холста. Токены запроса в любой позиции на холсте могут обрабатывать все остальные токены холста (а также кэш ключ-значение), позволяя модели обрабатывать контекст в двунаправленном режиме.
Расширенные фреймворки для вывода информации
Для преобразования изображения с чистым шумом в окончательный текст DiffusionGemma использует набор базовых систем декодирования:
Самообучение
В процессе вывода декодер (также известный как шумоподавитель) сохраняет свое предыдущее состояние. После завершения этапа шумоподавления он умножает сгенерированную матрицу распределения вероятностей на таблицу векторного представления токенов. В результате получается локализованное векторное представление, содержащее память о предыдущих прогнозах и показателях достоверности, которое передается непосредственно на следующий этап.
Многоканальная выборка (блочная диффузия)
Поскольку размер одного холста ограничен 256 токенами, DiffusionGemma объединяет алгоритмы диффузии и авторегрессии для обработки длинного текста. Он запускает циклы диффузии для генерации полного блока из 256 токенов, добавляет этот завершенный блок в контекст подсказки, обновляет кэш ключ-значение кодировщика и запускает новый цикл диффузии для холста размером 256 токенов.
Краткое содержание
Стандартные авторегрессивные языковые модели генерируют текст последовательно (по одному токену за раз), что делает их ресурсоемкими с точки зрения памяти и создает узкое место в виде задержки для отдельных пользователей. DiffusionGemma решает эту проблему, переходя к вычислительно-требуемой модели, которая генерирует полный «холст» из 256 токенов одновременно.
Используя метод равномерного распределения состояний (Uniform State Diffusion ), модель заменяет текст случайным шумом из словарного запаса и итеративно параллельно уточняет весь холст. Она использует тонко настроенную модель Gemma 4 26B A4B для поддержки различных задач шумоподавления и кодирования. Передовые фреймворки, такие как самообучение и выборка блоков на нескольких холстах, позволяют модели динамически исправлять ошибки, обрабатывать генерацию длинных текстов и достигать сверхнизкой задержки для одного пользователя.