
Để hiểu rõ về DiffusionGemma, bạn cần xem xét các hạn chế cốt lõi của mô hình ngôn ngữ tiêu chuẩn và cách thức hoạt động của mô hình khuếch tán dựa trên văn bản.
Vấn đề với mô hình tự hồi quy
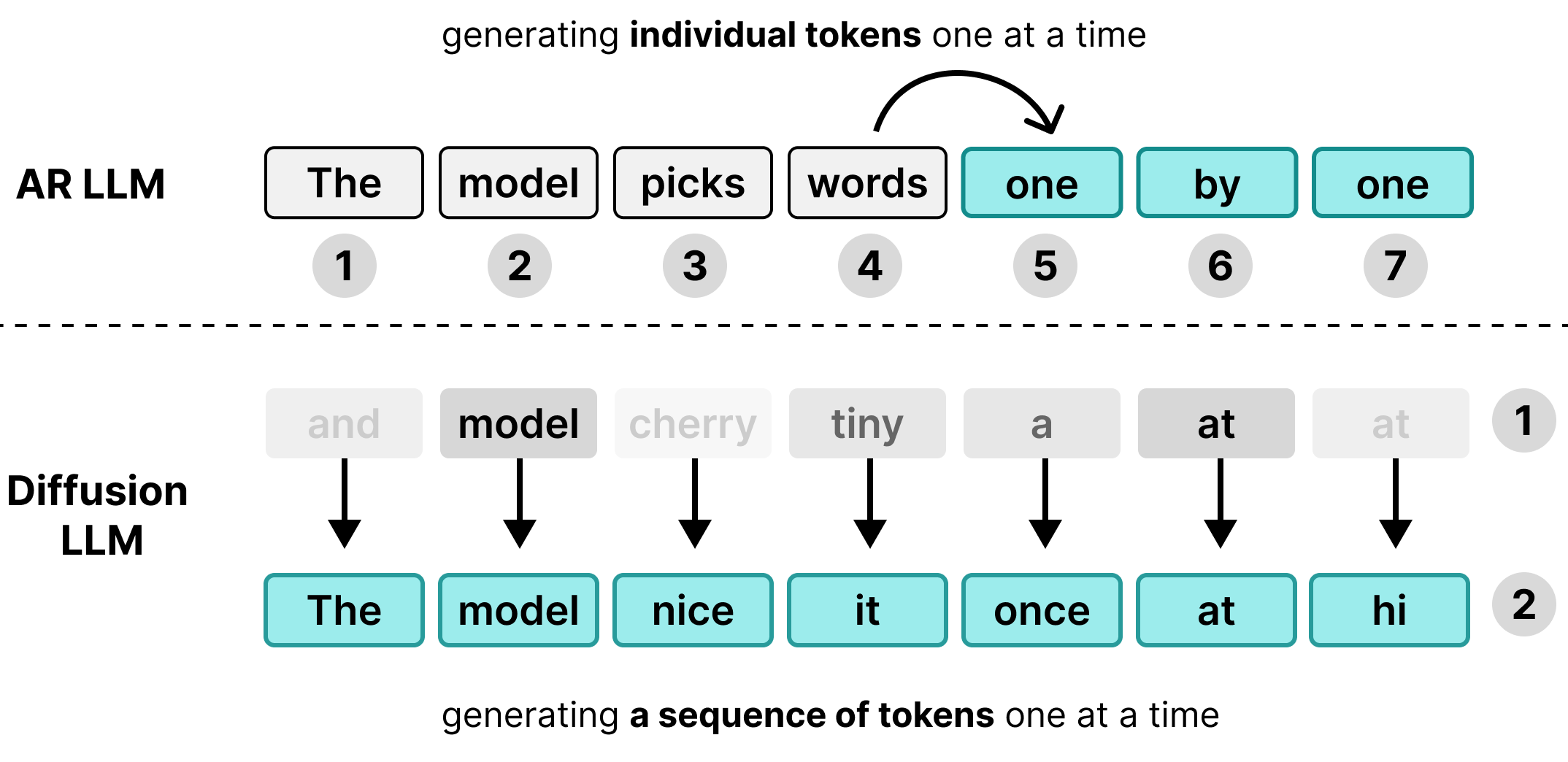
Nhiều Mô hình ngôn ngữ lớn (LLM) là tự hồi quy, nghĩa là chúng tạo văn bản từng mã thông báo một. Mặc dù phương pháp này hoạt động hiệu quả khi phục vụ nhiều người dùng cùng lúc thông qua việc xử lý theo lô, nhưng nó lại tạo ra nút thắt cổ chai về độ trễ cho từng người dùng.
Trong giai đoạn giải mã, các mô hình Transformer tiêu chuẩn bị giới hạn về bộ nhớ chứ không phải giới hạn về khả năng tính toán. Hầu hết thời gian tạo đều dành cho việc tải trọng số mô hình từ bộ nhớ phần cứng vào các đơn vị xử lý, thay vì thực hiện các phép tính toán học thực tế. Vì trọng số chỉ cần được tải một lần cho mỗi bước bất kể kích thước lô, nên việc tạo một mã thông báo mất gần như cùng một khoảng thời gian cho 1 người dùng như đối với 256 người dùng được nhóm lại với nhau.
Do đó, người dùng cá nhân không thấy được lợi thế về độ trễ; năng lực tính toán của phần cứng ở trạng thái nhàn rỗi trong khi chờ chuyển bộ nhớ.
DiffusionGemma tận dụng thời gian tính toán nhàn rỗi này cho từng người dùng. Thay vì tạo 1 mã thông báo cho 256 người dùng riêng biệt, mô hình này sẽ tạo 256 mã thông báo cùng một lúc cho một người dùng.
Mô hình này khởi tạo một chuỗi trống gồm 256 mã thông báo ngẫu nhiên (gọi là canvas) và lặp lại việc đánh giá cũng như tinh chỉnh toàn bộ canvas cùng một lúc. Điều này giúp mô hình chuyển từ trạng thái bị giới hạn về bộ nhớ sang trạng thái bị giới hạn về khả năng tính toán, cho phép mô hình mở rộng tốc độ xử lý một cách hiệu quả khi tăng sức mạnh tính toán.
| Tỷ lệ | Tự hồi quy văn bản | Khuếch tán văn bản |
|---|---|---|
| Tạo mã thông báo | Từng mã thông báo một | Toàn bộ canvas mã thông báo cùng một lúc |
| Các bước | Một bước cho mỗi mã thông báo | Một bước cho nhiều mã thông báo |
| Thứ tự tạo | Trái sang phải | Tất cả vị trí song song |
| Điểm bắt đầu | Chuỗi trống | Mã thông báo ngẫu nhiên được lấy mẫu từ từ vựng |
| Sửa lỗi | Tĩnh; không thể sửa đổi mã thông báo trước đó | Động; có thể sửa đổi mọi vị trí trên canvas |
| Điểm tắc nghẽn phần cứng | Giới hạn về bộ nhớ | Giới hạn về khả năng tính toán |
| Tập trung vào thông lượng | Thông lượng cao cho nhiều người dùng | Độ trễ cực thấp cho một người dùng |
Tìm hiểu cơ chế khuếch tán văn bản
Trong quá trình tạo hình ảnh, các mô hình khuếch tán bắt đầu bằng nhiễu Gaussian ngẫu nhiên 100% và loại bỏ dần nhiễu này (khử nhiễu) qua nhiều bước được hướng dẫn bằng lời nhắc văn bản. Việc chuyển đổi logic này sang văn bản sẽ khó khăn hơn vì mã thông báo văn bản là các thực thể rời rạc, không giống như các giá trị pixel liên tục.
DiffusionGemma đạt được khả năng khuếch tán dựa trên văn bản thông qua một loạt phương pháp chuyên biệt:
1. Khuếch tán có che
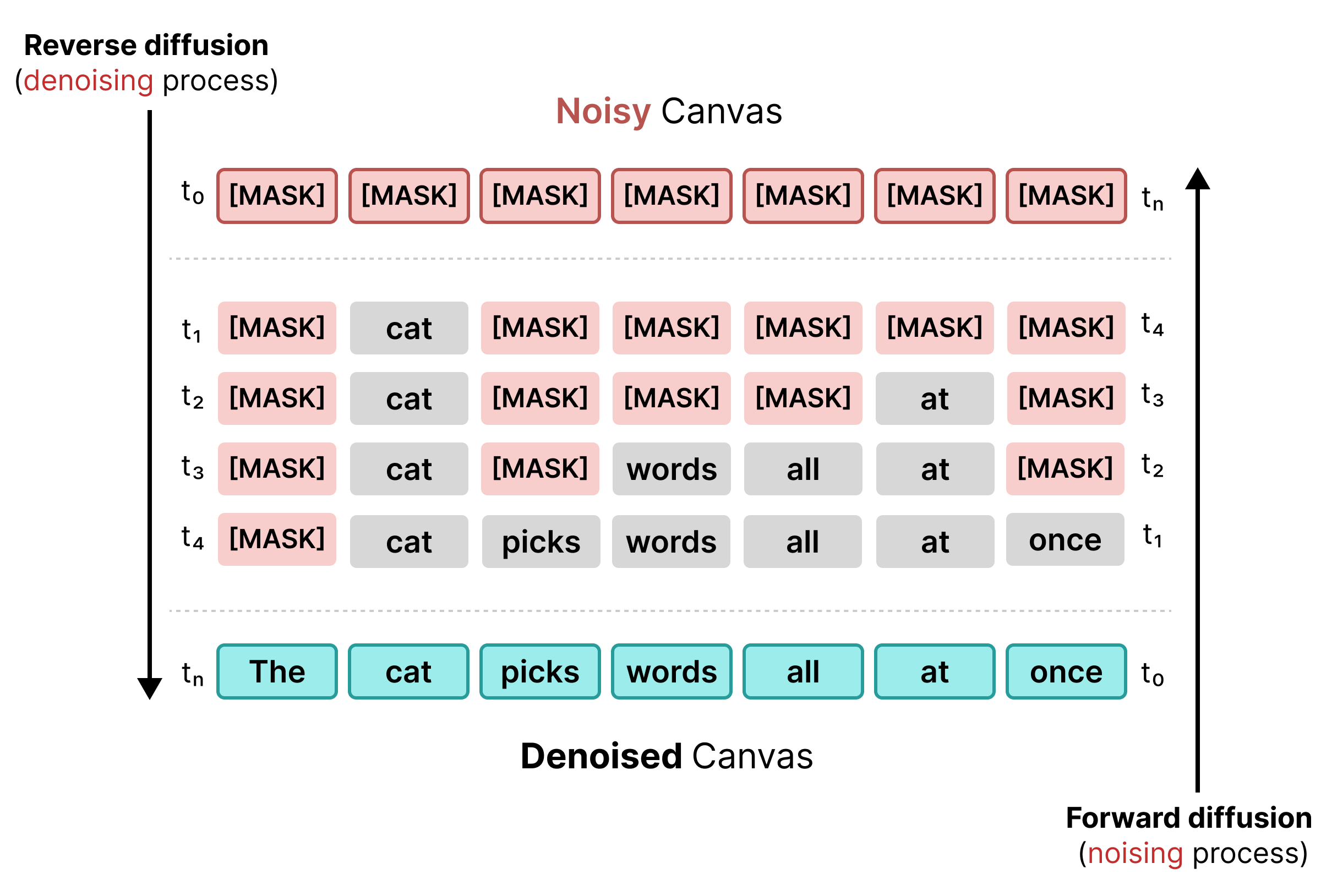
Quá trình khuếch tán văn bản ban đầu dựa vào việc che, tương tự như quá trình huấn luyện BERT. Các mã thông báo ngẫu nhiên trong một chuỗi được thay thế bằng mã thông báo [MASK] (đại diện cho nhiễu). Trong quá trình khuếch tán ngược, mô hình này sẽ dự đoán mã thông báo chính xác phía sau mặt nạ, thay thế các mã thông báo khi độ tin cậy đáp ứng một ngưỡng cụ thể.
Tuy nhiên, quá trình khuếch tán có che gặp phải vấn đề về tính cứng nhắc: sau khi mã thông báo [MASK] được thay thế bằng một từ, mã thông báo đó sẽ bị khoá. Bạn không thể sửa mã thông báo đó trong các bước sau nếu ngữ cảnh xung quanh thay đổi.
2. Khuếch tán trạng thái đồng nhất
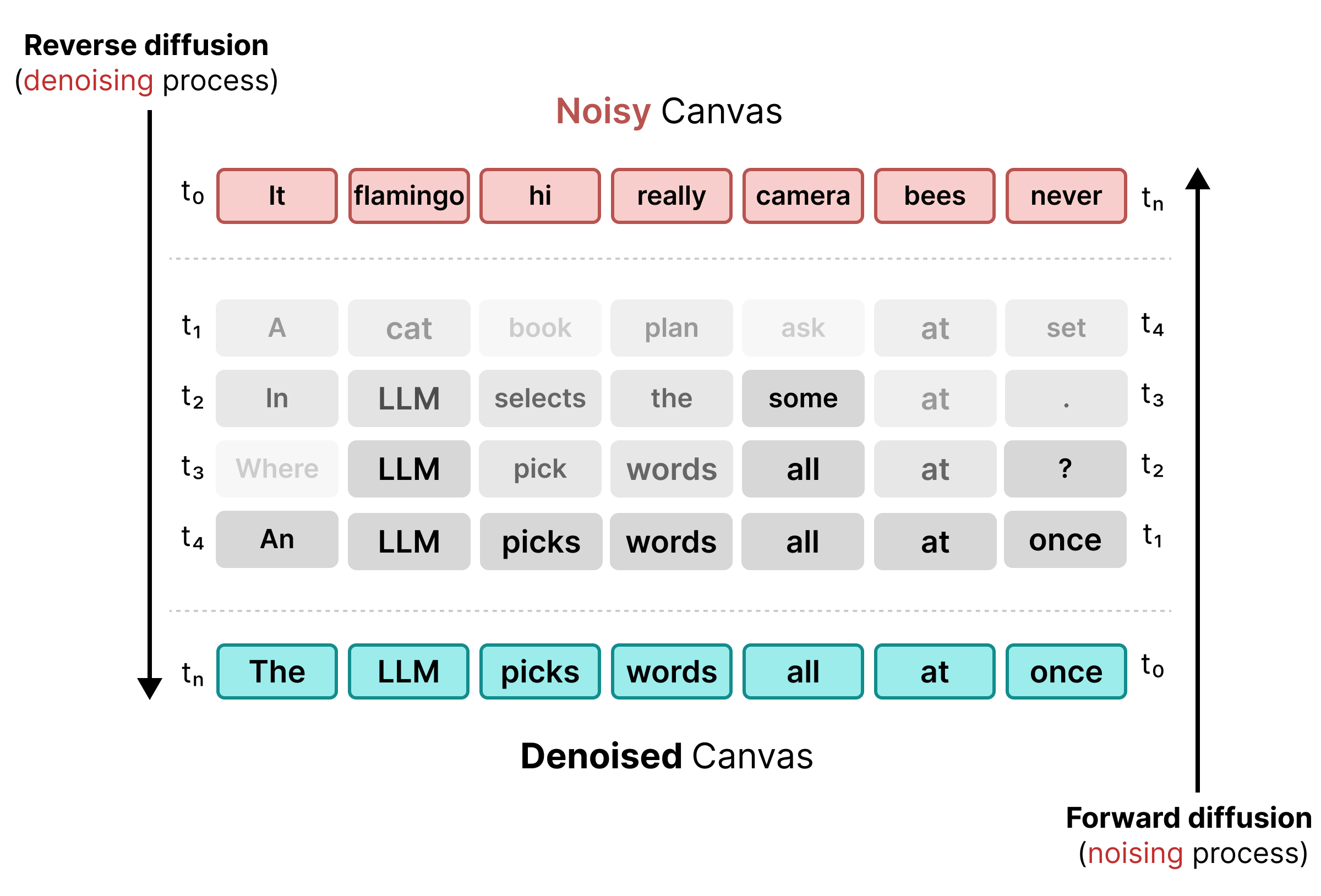
Để giải quyết các hạn chế của việc che, DiffusionGemma sử dụng Khuếch tán trạng thái đồng nhất. Thay vì mã thông báo [MASK] rõ ràng, nhiễu được đưa vào bằng cách thay thế các từ gốc bằng mã thông báo hoàn toàn ngẫu nhiên từ từ vựng.
Trong quá trình khử nhiễu, mô hình này sẽ phân tích toàn bộ canvas để xác định mã thông báo nào là nhiễu theo ngữ cảnh và cập nhật các mã thông báo đó. Nếu một mã thông báo chính xác, mã thông báo đó sẽ giữ lại xác suất cao. Nếu xác suất của một mã thông báo giảm xuống dưới ngưỡng do ngữ cảnh mới xuất hiện trong các bước sau, thì mã thông báo đó sẽ được tạo lại nhiễu bằng một mã thông báo ngẫu nhiên mới. Chu kỳ này cho phép sửa lỗi liên tục và tinh chỉnh canvas song song.
Cấu trúc: Quá trình điền trước và khử nhiễu tăng dần
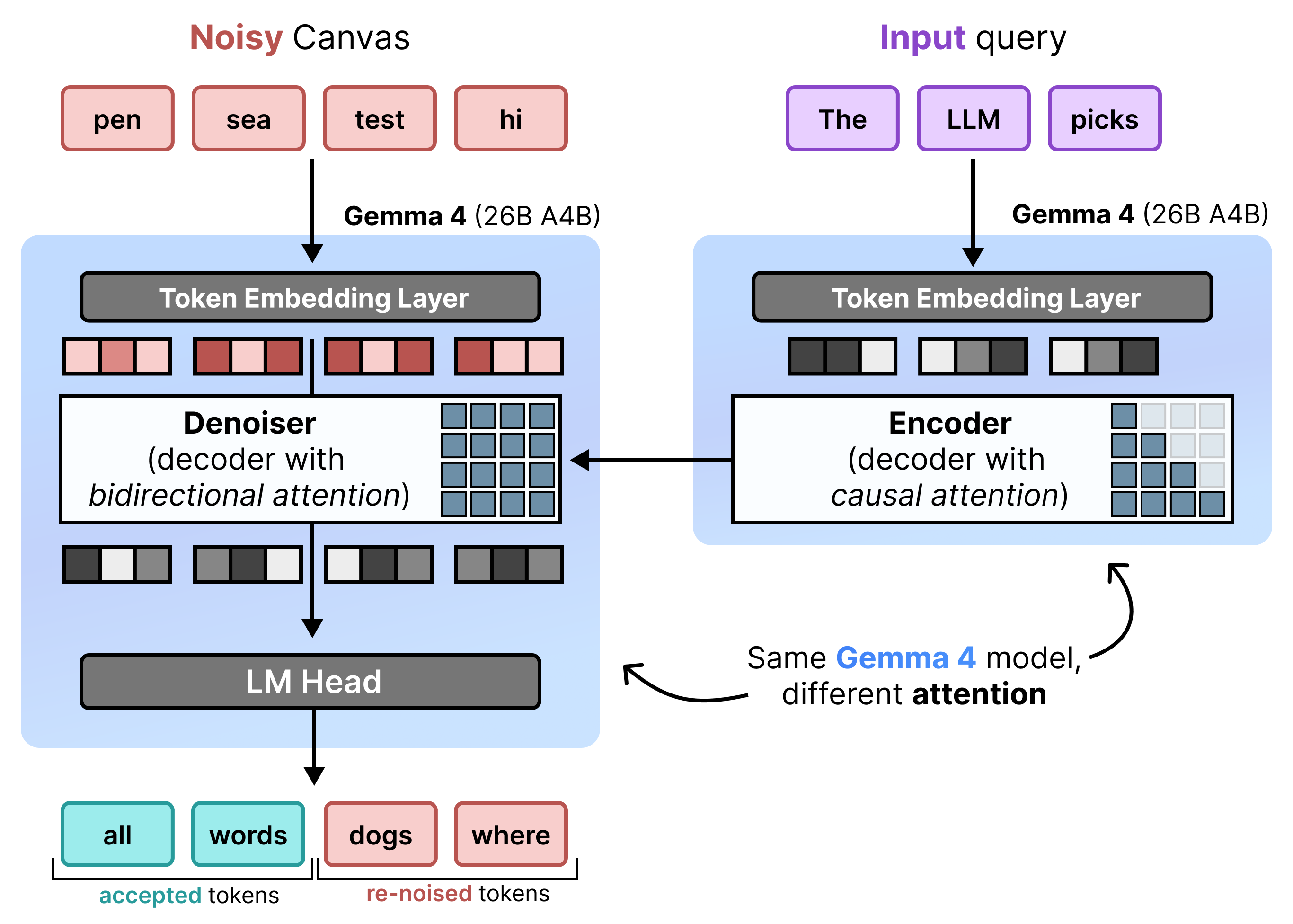
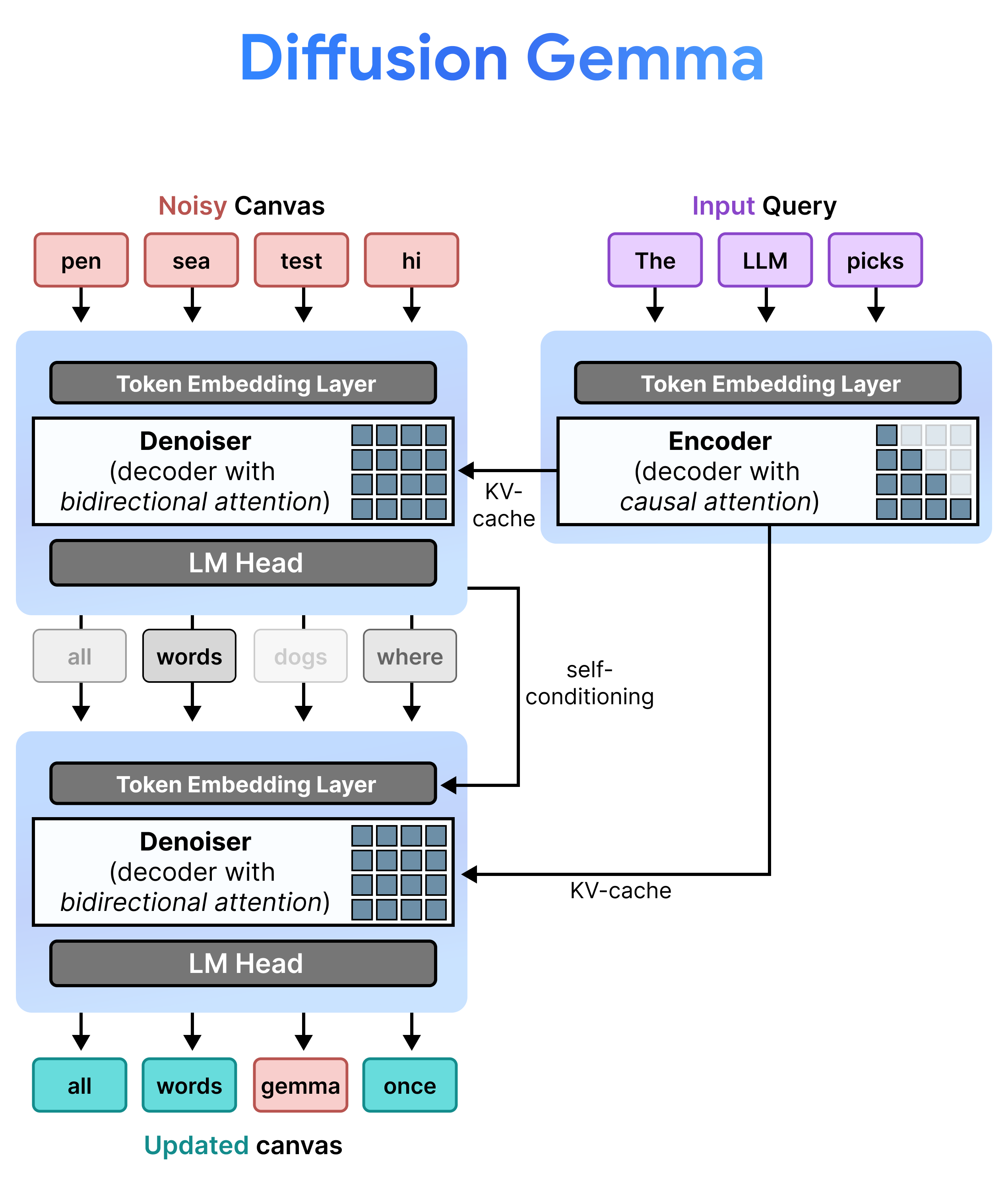
DiffusionGemma triển khai hiệu quả quá trình Khuếch tán trạng thái đồng nhất bằng cách luân phiên giữa Điền trước tăng dần và Khử nhiễu. Mô hình Gemma 4 26B A4B không được sử dụng nguyên bản mà được tinh chỉnh để hỗ trợ các nhiệm vụ khác nhau về khử nhiễu và mã hoá. Thay vì sử dụng các mô hình riêng biệt, một xương sống duy nhất sẽ chuyển đổi linh hoạt giữa hai chế độ:
- Điền trước / Điền trước tăng dần (Nhân quả): Sử dụng cơ chế chú ý nhân quả để thu thập ngữ cảnh lời nhắc và ghi vào bộ nhớ đệm KV. Quá trình này chạy một lần để điền trước ngữ cảnh ban đầu, sau đó chạy một lần cho mỗi khối để thêm từng canvas 256 mã thông báo đã hoàn thiện vào bộ nhớ đệm KV trước khi chuyển sang khử nhiễu canvas tiếp theo.
- Khử nhiễu (Hai chiều): Sử dụng cơ chế chú ý hai chiều để khử nhiễu canvas một cách lặp đi lặp lại. Mã thông báo truy vấn ở bất kỳ vị trí nào trên canvas đều có thể chú ý đến tất cả các mã thông báo khác trên canvas (cũng như bộ nhớ đệm KV), cho phép mô hình xử lý ngữ cảnh theo hai chiều.
Khung suy luận nâng cao
Để chuyển canvas từ nhiễu thuần tuý sang văn bản hoàn thiện, DiffusionGemma sử dụng một tập hợp các hệ thống giải mã cơ bản:
Tự điều kiện hoá
Trong quá trình suy luận, bộ giải mã (còn gọi là bộ khử nhiễu) sẽ giữ lại trạng thái trước đó. Sau khi hoàn tất bước khử nhiễu, bộ giải mã sẽ nhân ma trận phân phối xác suất đã tạo với bảng nhúng mã thông báo. Điều này tạo ra một biểu diễn vectơ cục bộ mang theo bộ nhớ về các dự đoán trước đó và các chỉ số độ tin cậy, được truyền trực tiếp vào bước tiếp theo.
Lấy mẫu nhiều canvas (Khuếch tán khối)
Vì một canvas được cố định thành 256 mã thông báo, nên DiffusionGemma sẽ xâu chuỗi quá trình khuếch tán và tự hồi quy với nhau cho văn bản dạng dài. Mô hình này chạy các chu kỳ khuếch tán để tạo một khối 256 mã thông báo đầy đủ, thêm khối đã hoàn thành đó vào ngữ cảnh lời nhắc, cập nhật bộ nhớ đệm KV của bộ mã hoá và bắt đầu một chu kỳ khuếch tán canvas 256 mã thông báo hoàn toàn mới.
Tóm tắt
Các mô hình ngôn ngữ tự hồi quy tiêu chuẩn tạo văn bản theo trình tự (từng mã thông báo một), khiến chúng bị giới hạn về bộ nhớ và tạo ra điểm tắc nghẽn về độ trễ cho từng người dùng. DiffusionGemma giải quyết vấn đề này bằng cách chuyển sang mô hình bị giới hạn về khả năng tính toán, tạo đồng thời một "canvas" 256 mã thông báo đầy đủ.
Bằng cách sử dụng Khuếch tán trạng thái đồng nhất, mô hình này sẽ thay thế văn bản bằng nhiễu từ vựng ngẫu nhiên và lặp lại việc tinh chỉnh toàn bộ canvas song song. Mô hình này sử dụng Gemma 4 26B A4B được tinh chỉnh để hỗ trợ các nhiệm vụ khác nhau về khử nhiễu và mã hoá. Các khung nâng cao như tự điều kiện hoá, lấy mẫu khối nhiều canvas cho phép mô hình này sửa lỗi một cách linh hoạt, xử lý quá trình tạo văn bản dạng dài và đạt được độ trễ cực thấp cho một người dùng.