
若要了解 DiffusionGemma,不妨先了解标准语言模型的核心限制,以及基于文本的扩散有何不同。
自回归模型存在的问题

许多大语言模型 (LLM) 都是自回归的,这意味着它们会逐个生成文本令牌。虽然这种方法非常适合通过批处理同时为许多用户提供服务,但会为单个用户带来延迟瓶颈。
在解码阶段,标准 Transformer 模型是内存受限,而不是计算受限。大部分生成时间都用于将模型权重从硬件内存加载到处理单元,而不是执行实际的数学计算。由于无论批次大小如何,每个步骤只需加载一次权重,因此为 1 个用户生成令牌所花费的时间与为 256 个用户(分组在一起)生成令牌所花费的时间几乎相同。
因此,单个用户看不到延迟优势;在等待内存传输时,硬件的计算能力处于闲置状态。
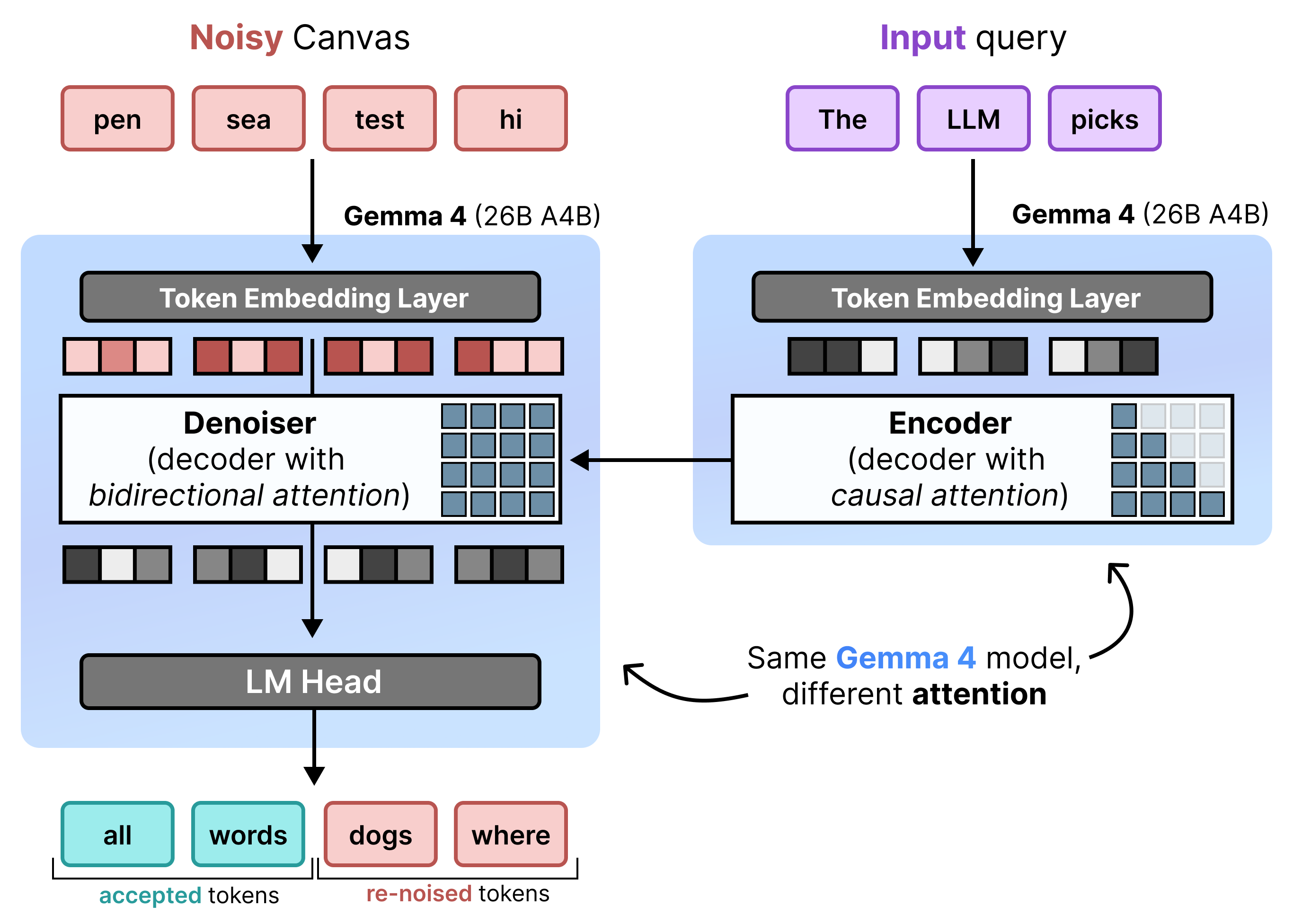
DiffusionGemma 会将此空闲计算时间用于单个用户。它不会为 256 个单独的用户生成 1 个 token,而是为单个用户一次性生成 256 个 token。
该模型会初始化一个包含 256 个随机令牌的空白序列(称为画布),并同时迭代评估和优化整个画布。这使得模型从受内存限制转变为受计算限制,从而能够随着计算能力的提高高效地扩展处理速度。
| 方面 | 文本自回归 | 文本扩散 |
|---|---|---|
| 令牌生成 | 一次一个令牌 | 一次性生成完整画布的令牌 |
| 步骤 | 每个令牌一个步骤 | 一步完成多个令牌的授权 |
| 生成顺序 | 从左到右 | 并行处理所有位置 |
| 起始代码 | 空序列 | 从词汇表中随机抽样的 token |
| 纠错 | 静态;无法修改过去的令牌 | 动态;可以修改任何画布位置 |
| 硬件瓶颈 | 内存受限 | 受计算限制 |
| 吞吐量重点 | 高多用户吞吐量 | 超低单用户延迟时间 |
了解文本扩散机制
在图像生成方面,扩散模型从 100% 的随机高斯噪声开始,并在文本提示的引导下,通过多个步骤逐步移除噪声(去噪)。将此逻辑转换为文本更具挑战性,因为文本令牌是离散实体,而像素值是连续的。
DiffusionGemma 通过一系列专业方法实现基于文本的扩散:
1. Masked Diffusion
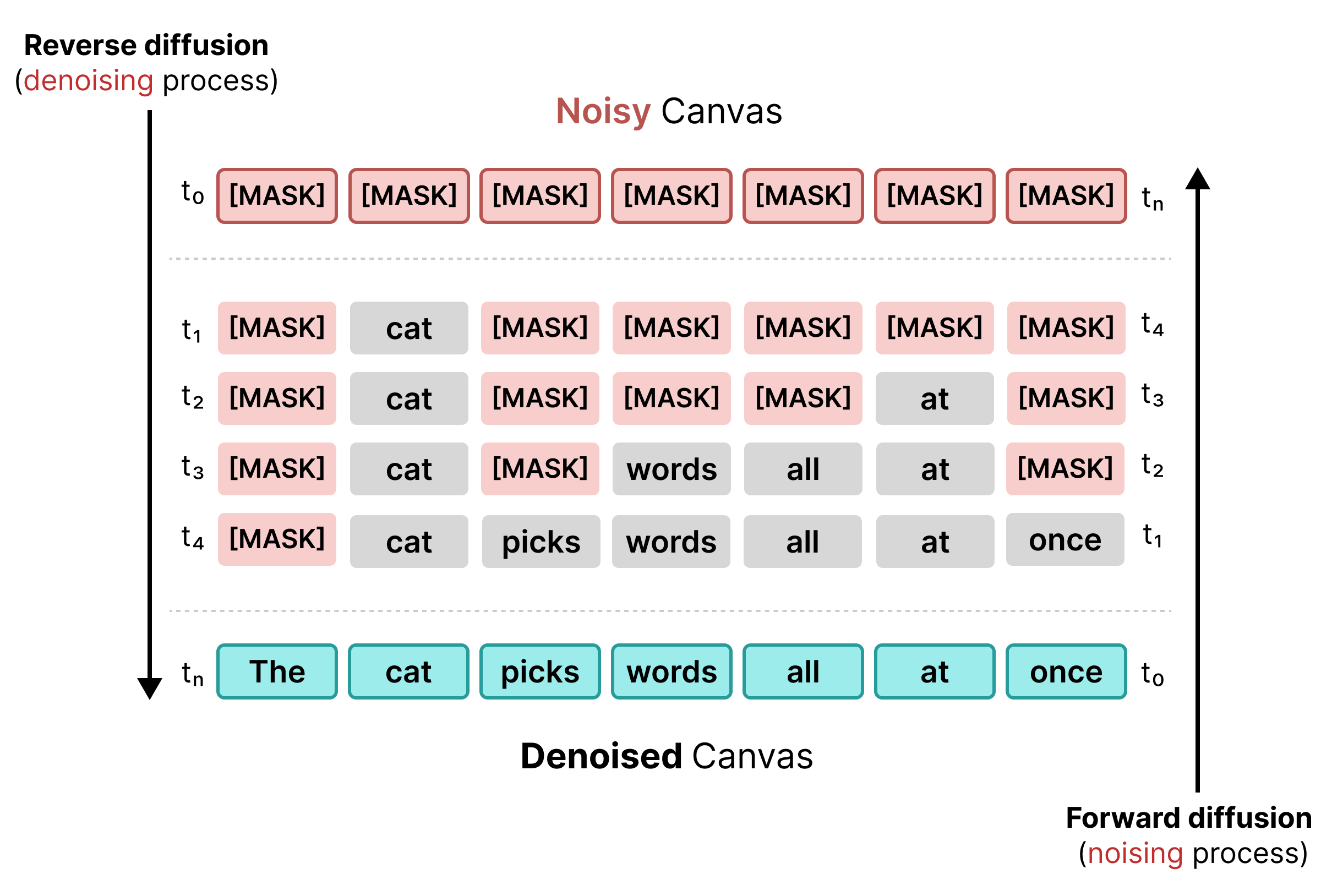
早期的文本扩散依赖于遮盖,类似于 BERT 训练。序列中的随机令牌会被替换为 [MASK] 令牌(表示噪声)。在反向扩散过程中,模型会预测掩码后面的正确令牌,并在置信度达到特定阈值时替换令牌。
不过,遮盖扩散存在僵化问题:一旦 [MASK] 令牌被替换为某个字词,就无法再更改。如果周围的上下文发生变化,则无法在后续步骤中进行更正。
2. Uniform State Diffusion
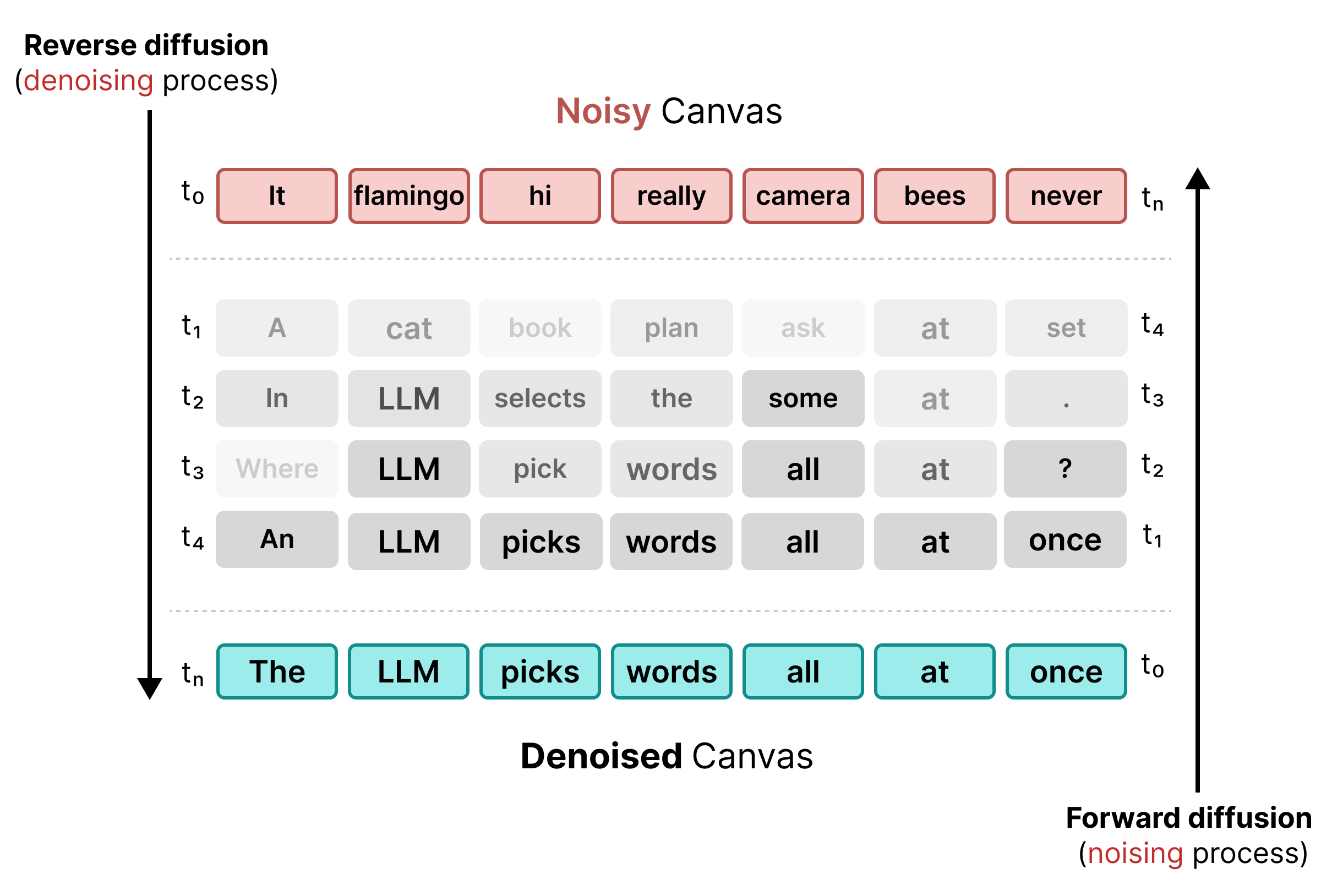
为解决遮盖带来的限制,DiffusionGemma 使用了均匀状态扩散。与显式 [MASK] 令牌不同,噪声是通过将原始字词替换为词汇表中的完全随机的令牌来引入的。
在去噪过程中,模型会分析整个画布,以确定哪些 token 是上下文噪声并更新这些 token。如果某个 token 是正确的,则会保留较高的概率。如果由于后续步骤中出现的新上下文,某个令牌的概率降至阈值以下,则会使用新的随机令牌对其进行重新加噪。此循环可实现持续的错误修正和并行画布优化。
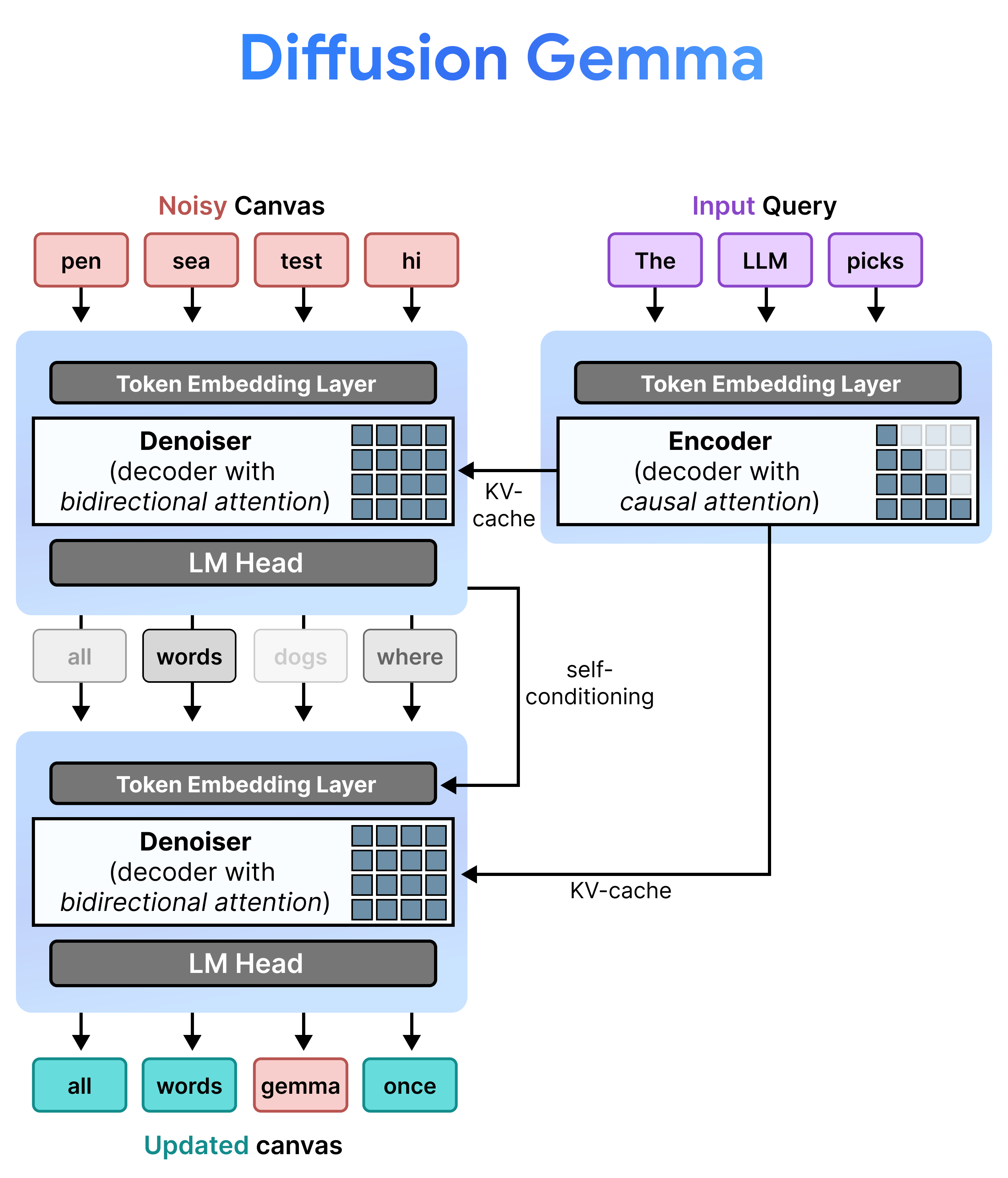
架构:增量预填充和去噪
DiffusionGemma 通过在增量预填充和去噪之间交替,高效实现均匀状态扩散。Gemma 4 26B A4B 模型并非原生使用,而是经过微调以支持不同的去噪和编码任务。单个主干网络可在两种模式之间动态切换,而不是使用单独的模型:
- 预填充 / 增量预填充(因果):使用因果注意力机制来提取提示上下文并写入 KV 缓存。此操作运行一次以预填充初始上下文,然后每个块运行一次,以在对下一个画布进行去噪之前将每个最终的 256-token 画布附加到 KV 缓存。
- 去噪(双向):使用双向注意力机制以迭代方式对画布进行去噪。画布上任何位置的查询令牌都可以关注所有其他画布令牌(以及 KV 缓存),从而让模型能够双向处理上下文。
高级推理框架
为了将画布从纯噪声转换为最终文本,DiffusionGemma 利用了一系列底层解码系统:
自我调节
在推理期间,解码器(也称为去噪器)会保留其之前的状态。完成去噪步骤后,它会将生成的概率分布矩阵乘以词元嵌入表。这样会生成一个局部向量表示,其中包含之前预测的记忆和置信度指标,并直接传递到下一步。
多画布抽样(块扩散)
由于单个画布固定为 256 个令牌,因此 DiffusionGemma 会将扩散和自回归链接在一起,以生成长文本。它运行扩散周期以生成完整的 256-token 块,将该完成的块附加到提示上下文,更新编码器的 KV 缓存,并启动全新的 256-token 画布扩散周期。
摘要
标准自回归语言模型会按顺序(一次一个 token)生成文本,这使得它们受内存限制,并为单个用户造成延迟瓶颈。DiffusionGemma 通过改用计算密集型模型来解决此问题,该模型可同时生成完整的 256-token“画布”。
通过利用统一状态扩散,该模型用随机词汇噪声替换文本,并并行迭代细化整个画布。它使用经过微调的 Gemma 4 26B A4B 来支持不同的去噪和编码任务。借助自条件化、多画布块采样等高级框架,该模型可以动态纠正错误、处理长篇生成内容,并实现极低的单用户延迟。