
如要瞭解 DiffusionGemma,建議先瞭解標準語言模型的核心限制,以及文字擴散的差異。
自我迴歸模型的問題
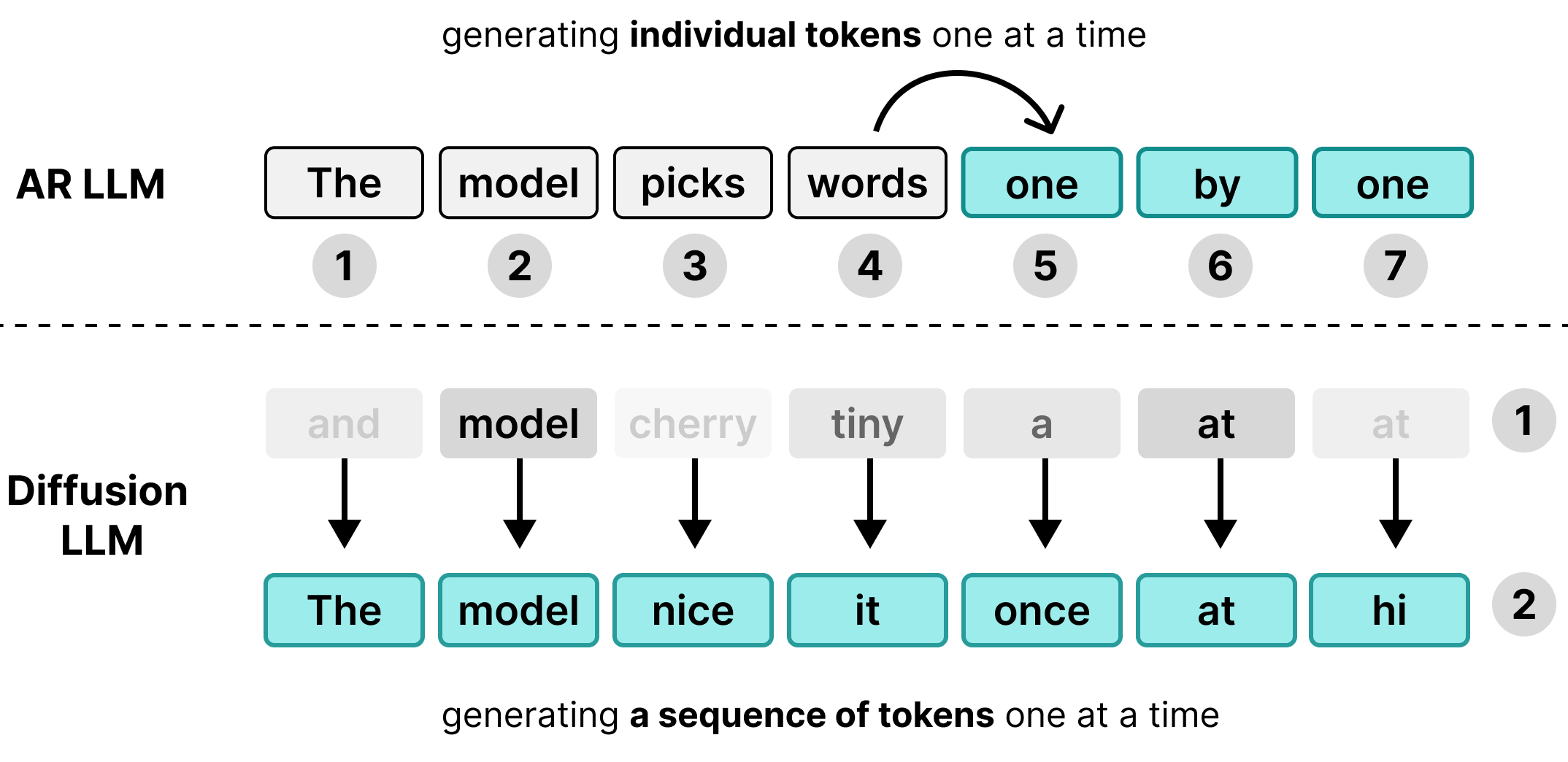
許多大型語言模型 (LLM) 都是自迴歸模型,也就是一次生成一個權杖。雖然這種方法很適合透過批次處理同時服務多位使用者,但會造成個別使用者的延遲瓶頸。
在解碼階段,標準 Transformer 模型是記憶體繫結,而非運算繫結。大部分的生成時間都用於將模型權重從硬體記憶體載入處理單元,而非執行實際的數學計算。由於權重在每個步驟中只需要載入一次,因此無論批量大小為何,為 1 位使用者生成權杖所花費的時間,與為 256 位使用者分組生成權杖所花費的時間幾乎相同。
因此,個別使用者不會感受到延遲優勢;硬體在等待記憶體傳輸時,運算能力會閒置。
DiffusionGemma舉例來說,如果 256 位使用者各自生成 1 個權杖,DiffusionGemma 會為單一使用者一次生成 256 個權杖。
模型會初始化 256 個隨機符記的空白序列 (稱為「畫布」),並同時反覆評估及修正整個畫布。這會讓模型從受記憶體限制轉為受運算限制,進而隨著運算能力提升,有效擴充處理速度。
| 面向 | 文字自迴歸 | Text Diffusion |
|---|---|---|
| 權杖生成 | 一次一個權杖 | 一次取得完整畫布的權杖 |
| 步驟 | 每個權杖一個步驟 | 一次驗證多個權杖 |
| 生成順序 | 由左至右 | 所有位置並行 |
| 起點 | 空序列 | 從字彙表隨機取樣的權杖 |
| 錯誤修正 | 靜態,無法修訂過去的權杖 | 動態,可修訂任何畫布位置 |
| 硬體瓶頸 | 記憶體受限 | 受運算限制 |
| 處理量焦點 | 高多使用者處理量 | 超低單一使用者延遲 |
瞭解文字擴散機制
在圖像生成過程中,擴散模型會先從 100% 隨機高斯雜訊開始,然後在文字提示詞的引導下,逐步移除雜訊 (去噪)。將這項邏輯轉換為文字更具挑戰性,因為文字權杖是離散實體,不像連續像素值。
DiffusionGemma 透過一系列專業方法,逐步實現以文字為基礎的擴散:
1. 遮罩擴散
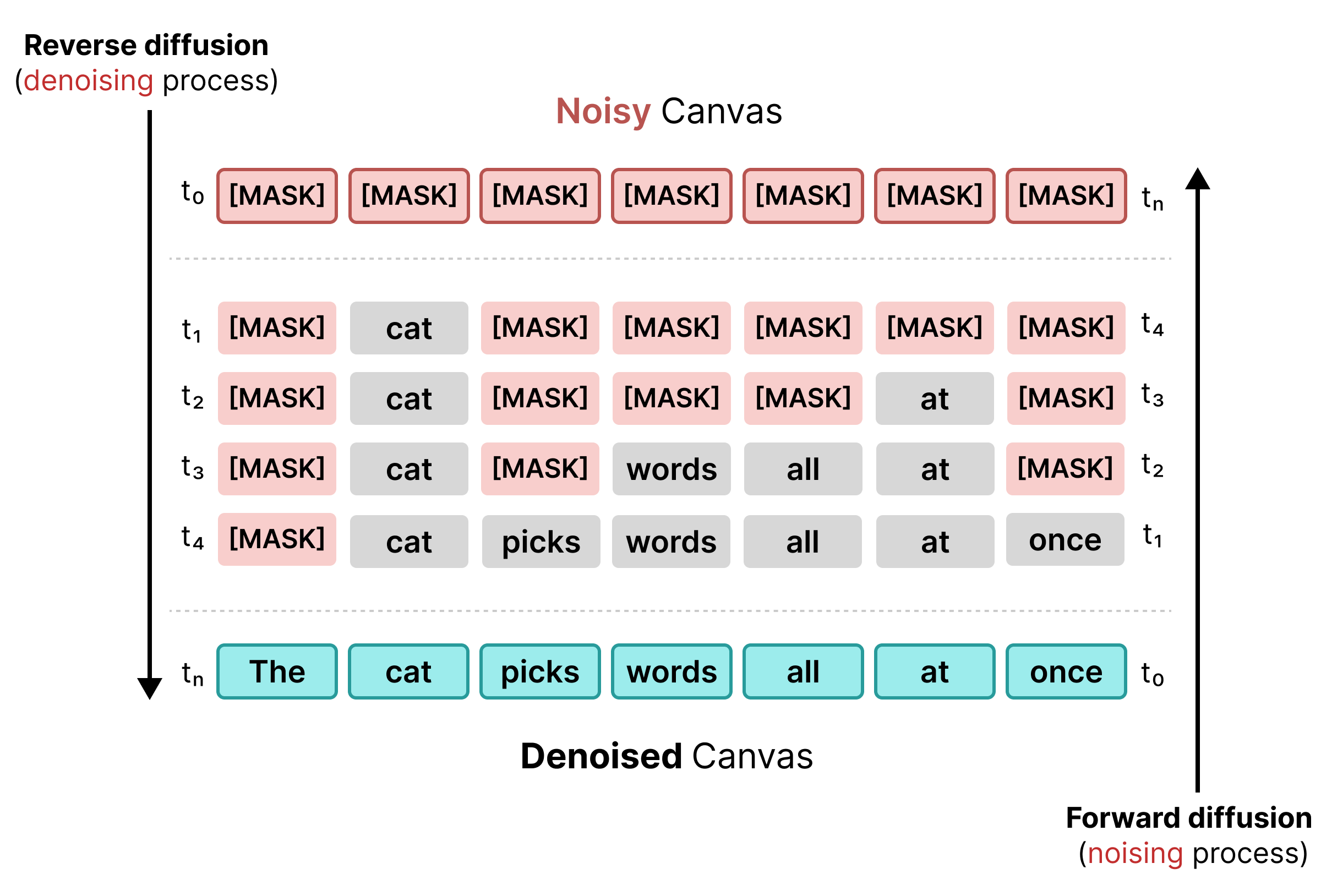
早期的文字擴散技術與 BERT 訓練類似,都是採用遮罩。序列中的隨機符記會替換為 [MASK] 符記 (代表雜訊)。在反向擴散期間,模型會預測遮罩後方的正確符記,並在信賴度達到特定門檻時替換符記。
不過,遮罩擴散法有其限制:[MASK] 權杖一旦替換成字詞,就無法再變更。如果周遭環境有所變化,後續步驟就無法修正。
2. Uniform State Diffusion
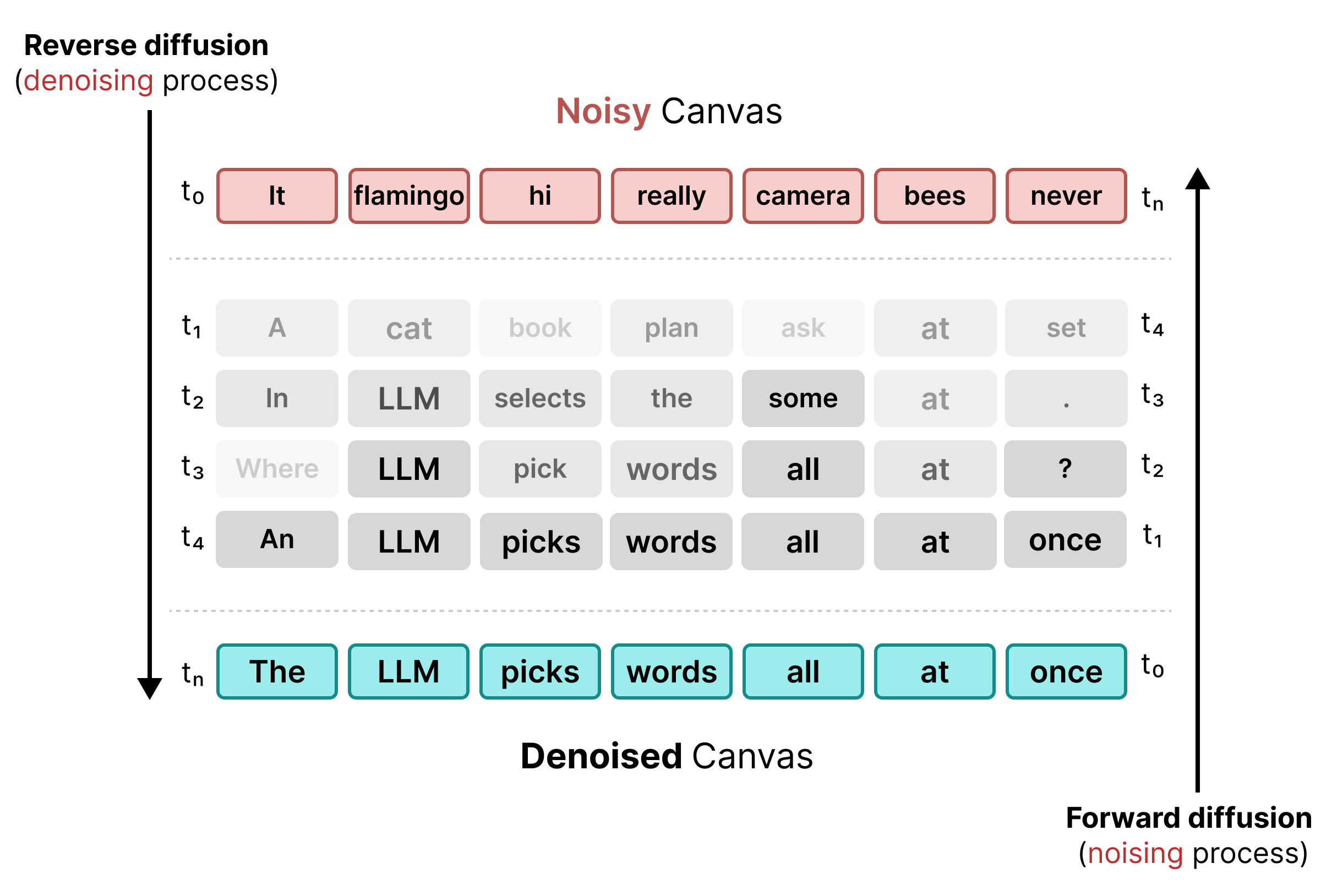
為解決遮蓋限制,DiffusionGemma 使用均勻狀態擴散。系統不會使用明確的 [MASK] 符記,而是從詞彙中選取完全隨機的符記,取代原始字詞來加入雜訊。
在去噪過程中,模型會分析整個畫布,判斷哪些符記是情境噪音並更新。如果符記正確,模型會保留高機率。如果符記的機率因後續步驟中出現的新情境而低於門檻,模型會使用新的隨機符記重新去噪。這個週期可持續修正錯誤,並平行精進畫布。
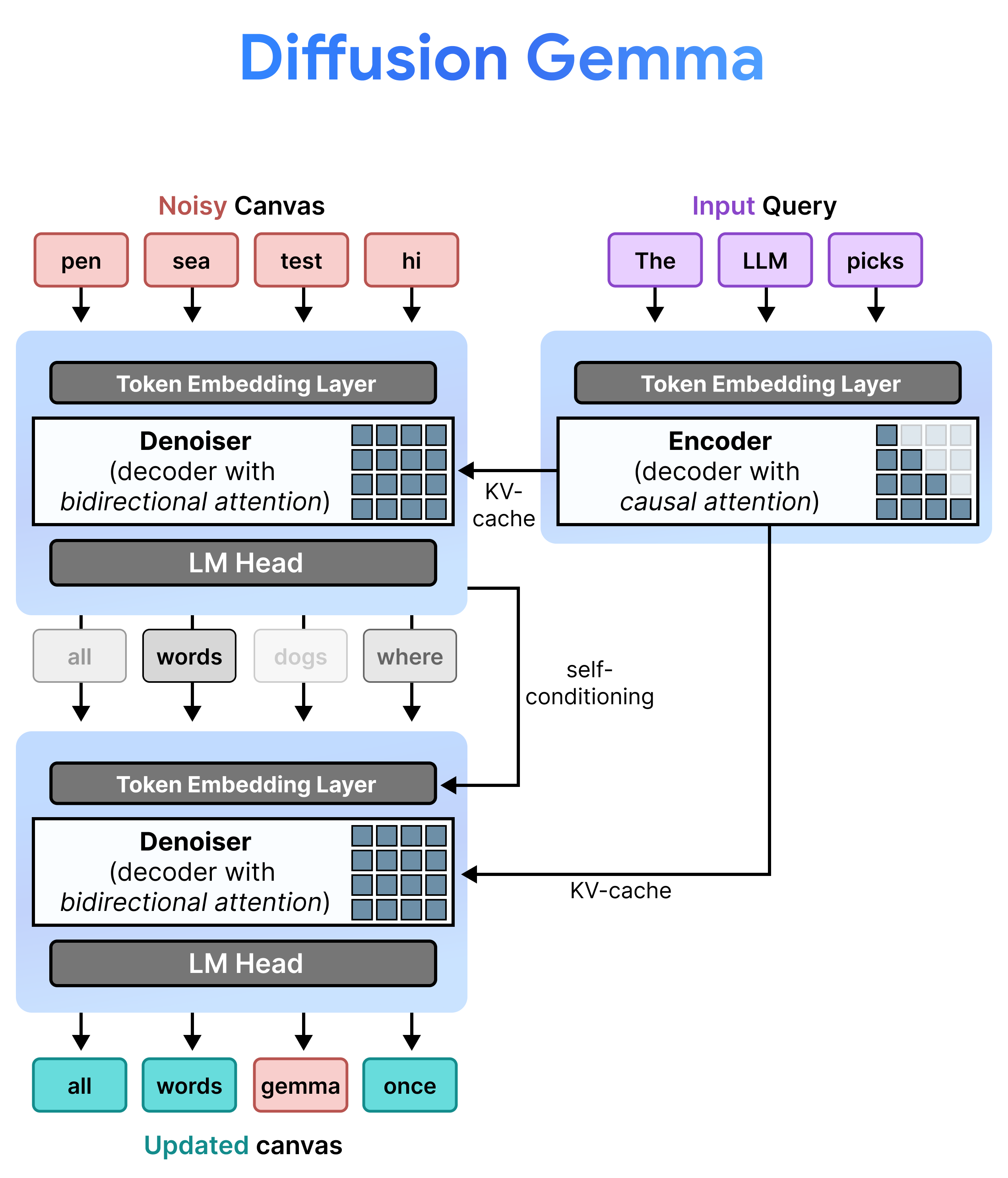
架構:增量預先填入和去噪
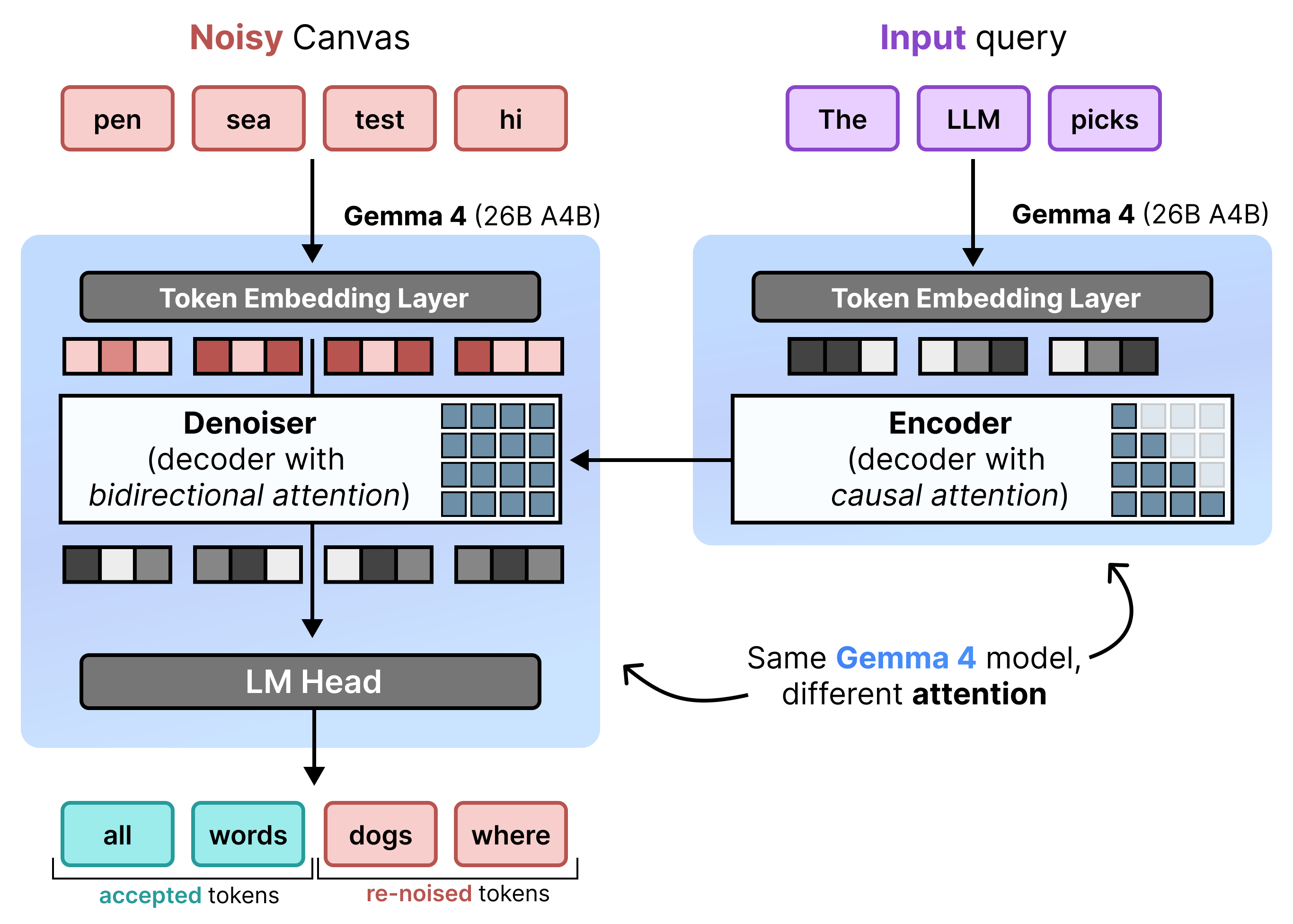
DiffusionGemma 會在「增量預先填入」和「去噪」之間交替,有效率地實作 Uniform State Diffusion。Gemma 4 26B A4B 模型並非原生使用,而是經過微調,可支援不同的去噪和編碼工作。單一主幹會在兩種模式之間動態切換,不必使用個別模型:
- 預先填入 / 增量預先填入 (因果):使用因果注意力機制擷取提示脈絡,並寫入 KV 快取。這項作業會執行一次,預先填入初始脈絡,然後每個區塊執行一次,將每個最終的 256 個權杖畫布附加至 KV 快取,再繼續對下一個畫布進行去噪。
- 去噪 (雙向):使用雙向注意力,反覆對畫布去噪。畫布上任何位置的查詢權杖都可以處理所有其他畫布權杖 (以及 KV 快取),讓模型雙向處理內容。
進階推論架構
如要將畫布從純雜訊轉換為最終文字,DiffusionGemma 會使用一系列基礎解碼系統:
自我調節
在推論期間,解碼器 (又稱去噪器) 會保留先前的狀態。完成去噪步驟後,解碼器會將產生的機率分布矩陣乘以符記嵌入資料表。這會產生局部向量表示,其中包含先前的預測和信賴度指標記憶,並直接傳遞至下一個步驟。
多畫布取樣 (區塊擴散)
由於單一畫布固定為 256 個權杖,DiffusionGemma 會將擴散和自動迴歸鏈結在一起,用於長篇文字。系統會執行擴散週期,產生完整的 256 個權杖區塊,將該區塊附加至提示內容,更新編碼器的 KV 快取,並啟動全新的 256 個權杖畫布擴散週期。
摘要
標準自迴歸語言模型會依序生成文字 (一次一個符記),因此會受到記憶體限制,並為個別使用者造成延遲瓶頸。DiffusionGemma 解決了這個問題,改用運算量受限的模型,同時生成完整的 256 個權杖「畫布」。
模型會運用統一狀態擴散,以隨機詞彙雜訊取代文字,並同時反覆修正整個畫布。這項模型使用微調的 Gemma 4 26B A4B,支援去噪和編碼等不同工作。透過自我調節、多畫布區塊取樣等進階架構,模型可動態修正錯誤、處理長篇生成內容,並達到超低單一使用者延遲。