
Side-by-side evaluation has emerged as a common strategy for assessing the quality and safety of responses from large language models (LLMs). Side-by-side comparisons can be used to choose between two different models, two different prompts for the same model, or even two different tunings of a model. However, manually analyzing side-by-side comparison results can be cumbersome and tedious.
The LLM Comparator is a web app with a companion Python library that enables more effective, scalable analysis of side-by-side evaluations with interactive visualizations. LLM Comparator helps you:
See where model performance differs: You can slice the responses to identify subsets of the evaluation data where outputs meaningfully differ between two models.
Understand why it differs: It is common to have a policy against which model performance and compliance is evaluated. Side-by-side evaluation helps automate policy compliance assessments and provides rationales for which model is likely more compliant. LLM Comparator summarizes these reasons into several themes and highlights which model aligns better with each theme.
Examine how model outputs differ: You can further investigate how the outputs from two models differ through built-in and user-defined comparison functions. The tool can highlight specific patterns in the text the models generated, providing a clear anchor to understand their differences.
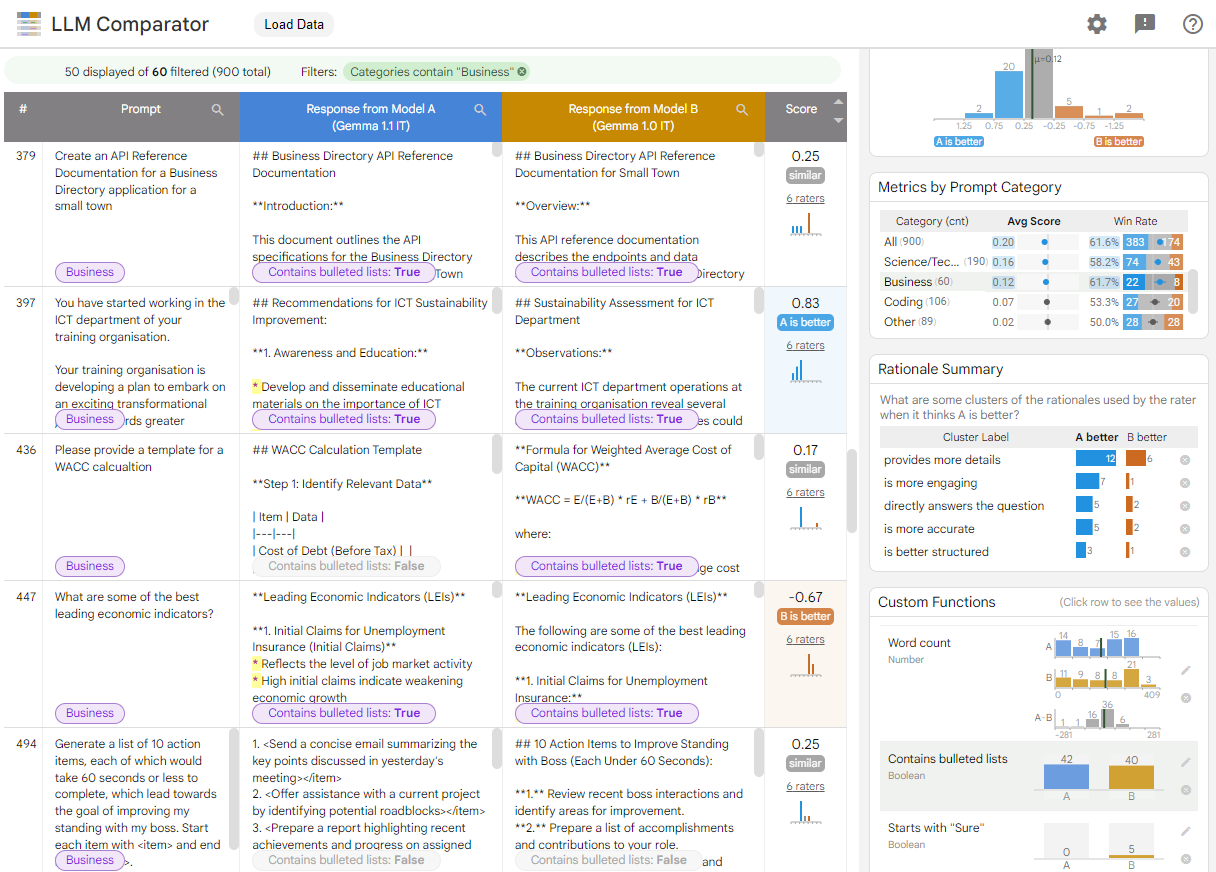
Figure 1. LLM Comparator interface showing a comparison of the Gemma Instruct 7B v1.1 model against v1.0
LLM Comparator helps you analyze side-by-side evaluation results. It visually summarizes model performance from multiple angles, while letting you interactively inspect individual model outputs for a deeper understanding.
Explore LLM Comparator for yourself:
- This demo compares the performance of Gemma Instruct 7B v1.1 against the Gemma Instruct 7B v1.0 on the Chatbot Arena Conversations dataset.
- This Colab notebook uses the Python library to run a small side-by-side evaluation using the Vertex AI API, and loads the results into the LLM Comparator app in a cell.
For more about LLM Comparator, check out the research paper and GitHub repo.