
הערכה זו הוכיחה את עצמה כאסטרטגיה נפוצה להערכת את האיכות והבטיחות של התשובות ממודלים גדולים של שפה (LLM). זה לצד זה השוואות מאפשרות לבחור בין שני מודלים שונים, להפעיל את אותו מודל או אפילו שתי פעולות כוונון שונות של אותו מודל. עם זאת, ניתוח ידני של תוצאות השוואה בטבלה יכול להיות מסורבל ומייגע.
LLM Comparator הוא אפליקציית אינטרנט עם ספריית Python נלווית שמאפשרת לבצע ניתוח גמיש ויעיל יותר של הערכות מקבילות באמצעות תצוגות חזותיות אינטראקטיביות. LLM Comparator עוזר לכם:
לבדוק איפה יש הבדלים בביצועי המודלים: אפשר לפלח את התשובות כדי לזהות קבוצות משנה של נתוני ההערכה שבהן יש הבדלים משמעותיים בין הפלט של שני המודלים.
להבין למה הוא שונה: לעיתים קרובות יש מדיניות נגד שלפיו מתבצעת הערכה של הביצועים והתאימות של המודל. הערכה של שני מודלים זה לצד זה עוזרת להפוך את הבדיקות של תאימות למדיניות לאוטומטיות ומספקת נימוקים לגבי המודל שסביר להניח שהוא תואם יותר. כלי ההשוואה של LLM מסכם את הסיבות האלה בכמה נושאים ומדגיש איזה מודל מתאים יותר לכל נושא.
לבחון איך הפלט של המודל משתנה: תוכלו לחקור באופן מעמיק יותר איך ההבדלים בין הפלט לבין שני מודלים שונים באופן מובנה ומוגדר על ידי המשתמש של פונקציות השוואה. הכלי יכול להדגיש דפוסים ספציפיים בטקסט שנוצר על ידי המודלים, וכך לספק עוגן ברור להבנת ההבדלים ביניהם.
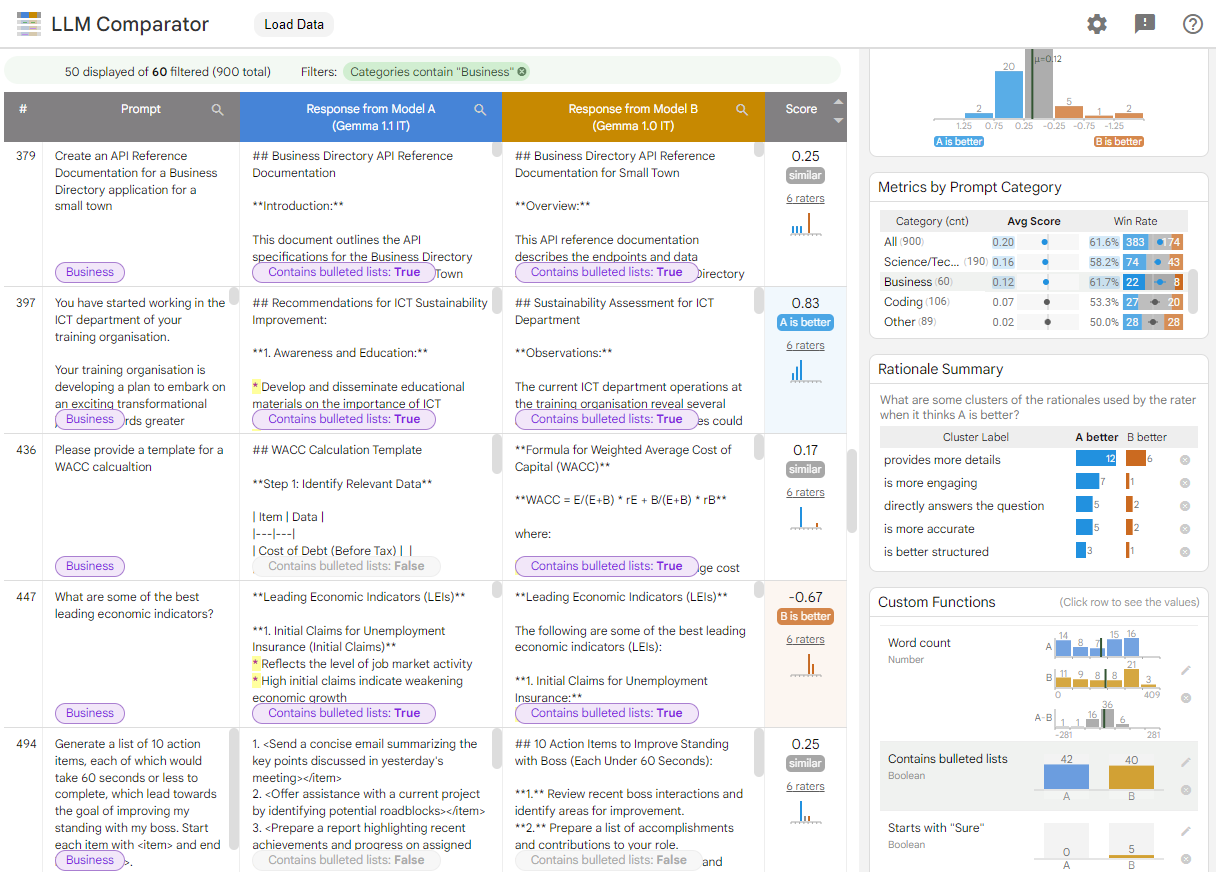
איור 1. ממשק של LLM Comparator שבו מוצגת השוואה בין המודל Gemma Instruct 7B v1.1 לבין המודל v1.0
כלי השוואה של מודלים גדולים של שפה עוזר לנתח תוצאות הערכה זו לצד זו. הוא מסכם באופן חזותי את ביצועי המודל מכמה זוויות שונות, ומאפשר לבצע בדיקה אינטראקטיבית של הפלט של מודל אחד כדי להגיע להבנה עמוקה יותר.
התנסות עצמית בכלי להשוואת מודלים גדולים של שפה:
- בהדגמה הזו מוצגת השוואה בין הביצועים של Gemma Instruct 7B v1.1 לבין Gemma Instruct 7B v1.0 במערך הנתונים Chatbot Arena Conversations.
- בnotebook של Colab הזה נעשה שימוש בספריית Python כדי להריץ הערכה קטנה של מודלים זה לצד זה באמצעות Vertex AI API, ולטעון את התוצאות לתא באפליקציית LLM Comparator.
מידע נוסף על LLM Comparator זמין במאמר המחקר ובמאגר ב-GitHub.