
La evaluación en paralelo surgió como una estrategia común para evaluar la calidad y seguridad de las respuestas de los modelos de lenguaje grandes (LLM). Lado a lado se pueden usar para elegir entre dos modelos diferentes, dos el mismo modelo o incluso dos ajustes diferentes de uno. Sin embargo, analizar manualmente los resultados de la comparación en paralelo puede ser engorroso y tedioso.
El comparador de LLM es una app web con una biblioteca de Python complementaria que permite un análisis más eficaz y escalable de evaluaciones en paralelo con visualizaciones interactivas. El comparador de LLM te ayuda a hacer lo siguiente:
Consulta dónde difiere el rendimiento del modelo: Puedes dividir las respuestas para identificar subconjuntos de los datos de evaluación donde los resultados son significativos difieren entre dos modelos.
Comprende por qué las diferencias: es común tener una política en contra en la que se evalúa el rendimiento y el cumplimiento del modelo. La evaluación en paralelo ayuda a automatizar las evaluaciones de cumplimiento de las políticas y proporciona argumentos para determinar qué modelo es más probable que cumpla con las políticas. El comparador de LLM resume estas razones en varios temas y destaca qué modelo se alinea mejor con cada uno.
Examina en qué se diferencian los resultados del modelo: Puedes investigar en más detalle cómo se diferencian los resultados de dos modelos a través de funciones de comparación integradas y definidas por el usuario. La herramienta puede destacar patrones específicos en el texto los modelos generados, lo que proporciona un argumento claro para comprender diferencias.
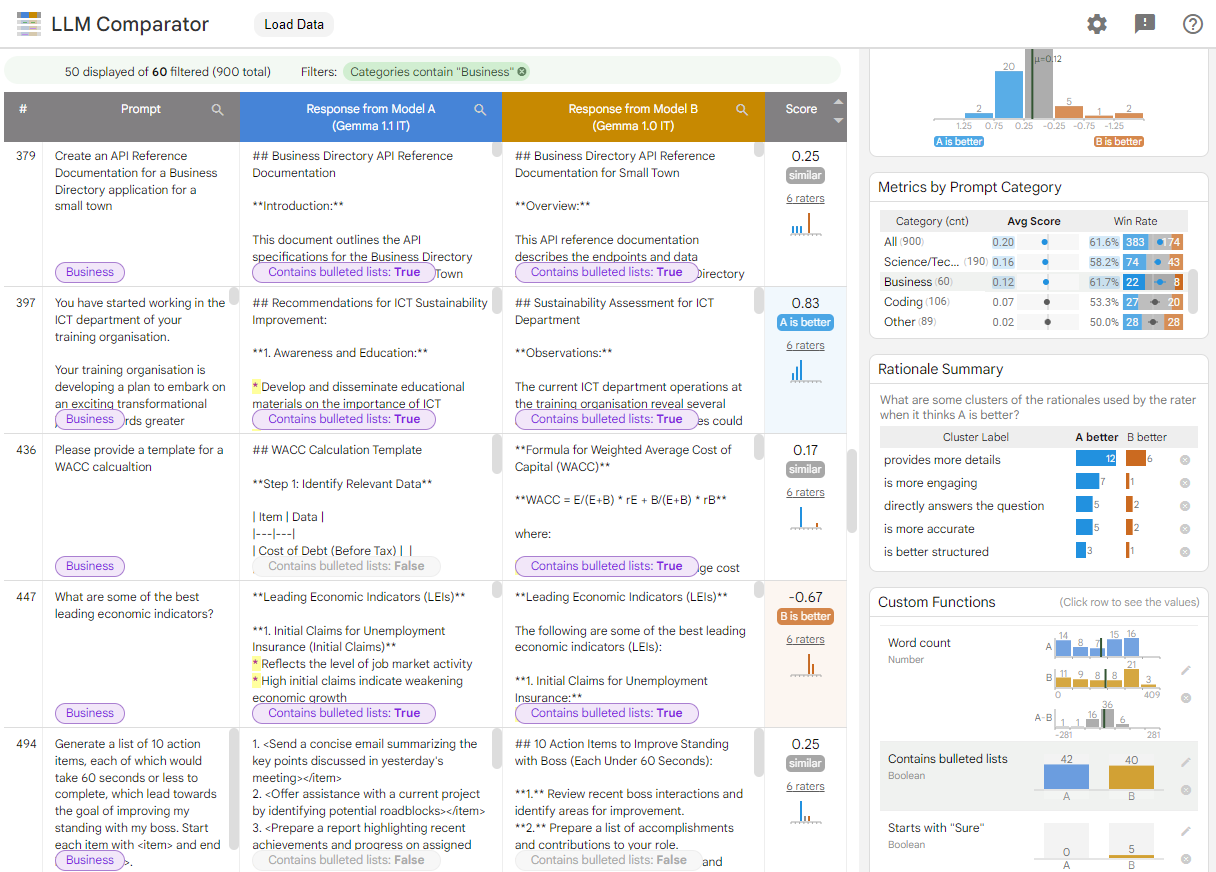
Figura 1: La interfaz del comparador de LLM muestra una comparación de los componentes de Gemma. Indica el modelo 7B v1.1 en comparación con v1.0
El comparador de LLM te ayuda a analizar los resultados de la evaluación en paralelo. Resume visualmente el rendimiento del modelo desde varios ángulos y, al mismo tiempo, te permite inspeccionar de forma interactiva los resultados de los modelos individuales para comprenderlos mejor.
Explora el comparador de LLM por tu cuenta:
- Esta demostración compara el rendimiento de la versión 1.1 de Gemma Instruct 7B. en comparación con la versión 1.0 de Gemma Instruct 7B en la Conjunto de datos de Chatbot Arena Conversations.
- Este notebook de Colab usa la biblioteca de Python para ejecutar una pequeña evaluación en paralelo con la API de Vertex AI y carga los resultados en la app de LLM Comparator en una celda.
Para obtener más información sobre LLM Comparator, consulta el artículo de investigación y el repositorio de GitHub.