
Evaluasi berdampingan telah muncul sebagai strategi umum untuk menilai kualitas dan keamanan respons dari model bahasa besar (LLM). Perbandingan berdampingan dapat digunakan untuk memilih antara dua model yang berbeda, dua perintah yang berbeda untuk model yang sama, atau bahkan dua penyesuaian model yang berbeda. Namun, menganalisis secara manual hasil perbandingan berdampingan bisa merepotkan dan membosankan.
LLM Comparator adalah aplikasi web dengan Library Python yang memungkinkan analisis skalabel yang lebih efektif evaluasi berdampingan dengan visualisasi interaktif. Perbandingan LLM membantu Anda:
Lihat tempat performa model berbeda: Anda dapat mengelompokkan respons untuk mengidentifikasi subkumpulan data evaluasi tempat output berbeda secara signifikan antara dua model.
Pahami alasan perbedaannya: Sangat umum untuk memiliki kebijakan yang melarang performa dan kepatuhan model mana yang dievaluasi. Evaluasi berdampingan membantu mengotomatiskan kepatuhan terhadap kebijakan penilaian dan memberikan alasan mengenai model mana yang mematuhi kebijakan. LLM Comparator meringkas alasan ini ke dalam beberapa tema dan menandai model mana yang lebih selaras dengan setiap tema.
Mempelajari perbedaan output model: Anda dapat menyelidiki lebih lanjut output dari dua model akan berbeda melalui model fungsi perbandingan. Alat ini dapat menyoroti pola tertentu dalam teks yang dihasilkan model, sehingga memberikan anchor yang jelas untuk memahami perbedaannya.
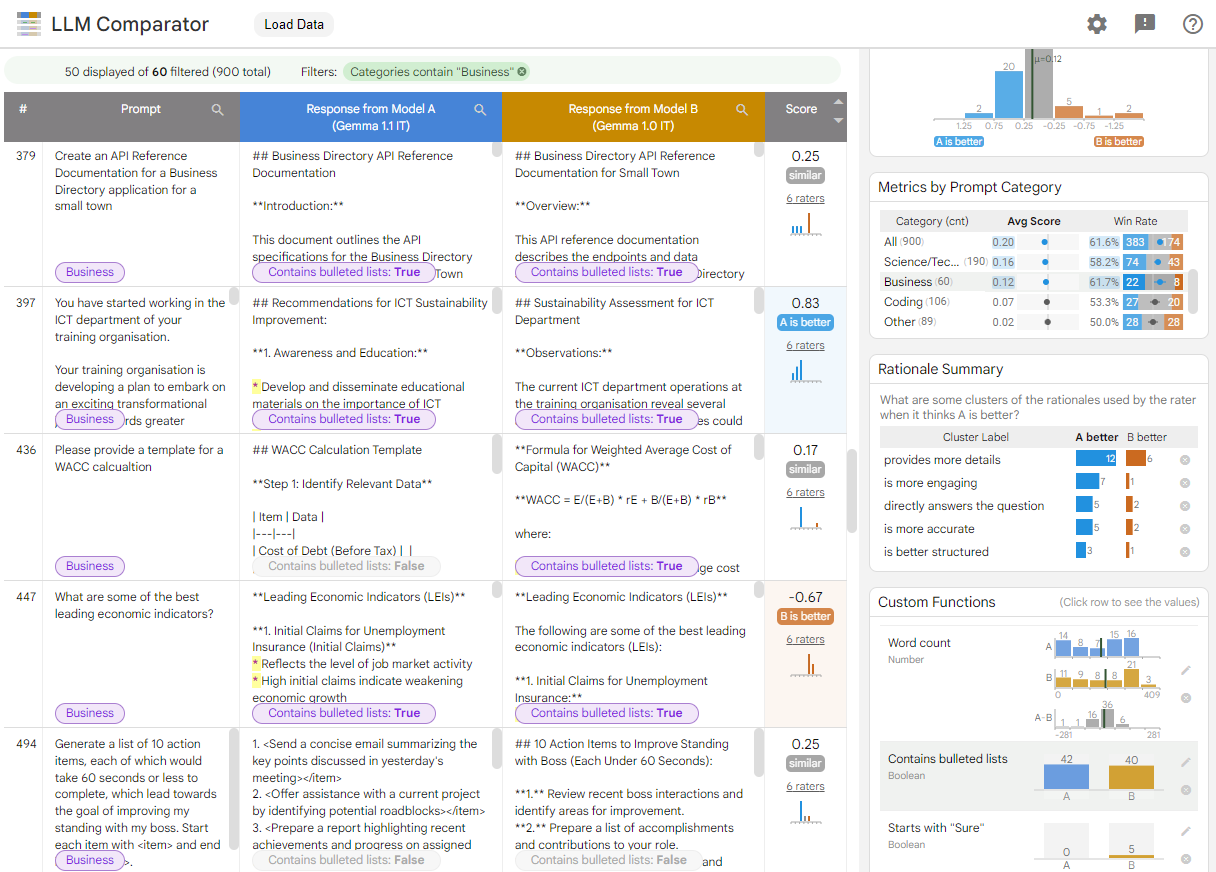
Gambar 1. Antarmuka LLM Comparator yang menampilkan perbandingan model Gemma Instruct 7B v1.1 dengan v1.0
LLM Comparator membantu Anda menganalisis hasil evaluasi secara berdampingan. Ini secara visual merangkum performa model dari berbagai sudut, sekaligus memeriksa output model satu per satu secara interaktif untuk mendapatkan pemahaman yang lebih mendalam.
Jelajahi LLM Comparator sendiri:
- Demo ini membandingkan performa Gemma Instruct 7B v1.1 dengan Gemma Instruct 7B v1.0 pada set data Chatbot Arena Conversations.
- Notebook Colab ini menggunakan library Python untuk menjalankan evaluasi berdampingan menggunakan Vertex AI API, dan memuat hasilnya ke aplikasi LLM Comparator dalam sel.
Untuk mengetahui informasi selengkapnya tentang LLM Comparator, lihat makalah riset dan repo GitHub.