
병렬 평가는 AI 원칙을 평가하기 위한 공통 전략으로 부상하여 응답의 품질과 안전성을 개선하는 데 사용됩니다. 나란히 비교를 사용하면 두 가지 모델, 동일한 모델의 두 가지 프롬프트 또는 모델의 두 가지 튜닝 중에서 선택할 수 있습니다. 하지만 나란히 비교 결과를 수동으로 분석하는 것은 번거롭고 지루할 수 있습니다.
LLM 비교기는 컴패니언을 지원하는 웹 앱으로 보다 효과적이고 확장 가능한 분석을 지원하는 Python 라이브러리 대화형 시각화를 사용하여 나란히 평가할 수 있습니다. LLM Comparator는 다음과 같은 작업에 도움이 됩니다.
모델 성능이 다른 위치 확인: 응답을 슬라이스하여 두 모델 간에 출력이 유의미하게 다른 평가 데이터의 하위 집합을 식별할 수 있습니다.
차이점 이유 이해하기: 모델 성능 및 규정 준수를 평가합니다 나란히 평가를 통해 정책 준수 자동화 어떤 모델이 더 효과적일 가능성이 높은지 근거를 제공하여 . LLM 비교기는 이러한 이유를 몇 가지 테마로 요약하고 어떤 모델이 각 테마에 더 잘 맞는지 강조합니다.
모델 출력의 어떻게 다른지 확인: 모델 출력의 차이점을 더 자세히 조사할 수 있습니다. 기본 제공 및 사용자 정의 모델을 통해 두 모델의 출력이 다름 비교 함수입니다. 도구에서 텍스트의 특정 패턴을 강조 표시할 수 있습니다. 모델이 이해할 수 있도록 해 주는 명확한 앵커를 제공하여 있습니다.
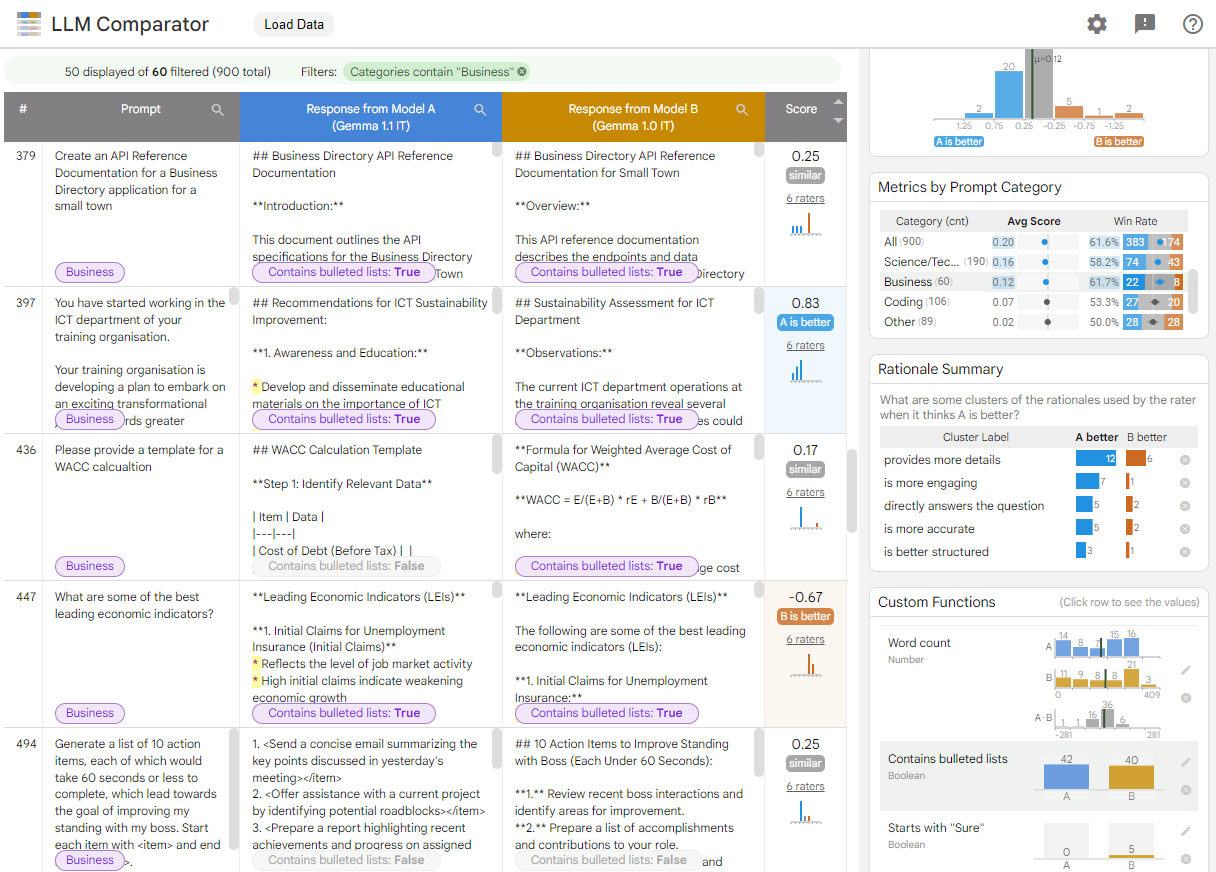
그림 1. Gemma를 비교한 내용을 보여주는 LLM 비교기 인터페이스 v1.0을 대상으로 7B v1.1 모델 지정
LLM 비교 도구를 사용하면 평가 결과를 나란히 분석할 수 있습니다. 여러 각도에서 모델 성능을 시각적으로 요약하는 동시에 개별 모델 출력을 대화식으로 검사하여 더 깊이 이해할 수 있습니다.
LLM 비교 도구를 직접 살펴보세요.
- 이 데모는 Gemma Instruct 7B v1.1의 성능을 비교합니다. Gemma Instruct 7B v1.0을 상대로 Chatbot Arena Conversations 데이터 세트
- 이 Colab 노트북은 Python 라이브러리를 사용하여 Vertex AI API를 사용하여 병렬 평가를 실행하고 결과를 셀의 LLM 비교기 앱으로 보냅니다.
LLM 비교기에 관한 자세한 내용은 연구 논문 및 GitHub 저장소를 참고하세요.