
並べて評価は、組織のリスクを評価するための一般的な 品質と安全性を重視しています。横並び 比較によって、2 つの異なるモデル、2 つの異なる 異なるチューニングを行うこともできます。ただし、並べ替え比較の結果を手動で分析するのは面倒で時間がかかります。
LLM Comparator は、コンパニオン アプリのウェブアプリ より効果的でスケーラブルな分析を可能にする Python ライブラリ インタラクティブな可視化を使用した比較評価。 LLM 比較ツールを使用すると、次のことができます。
モデルのパフォーマンスの場所の違いを確認する: レスポンスをスライスできます。 出力が有意なものである評価データのサブセットを 違いがあるということです。
違いの理由を理解する: 一般的に、ポリシーの相違点を モデルのパフォーマンスとコンプライアンスを評価します 比較評価でポリシーの遵守を自動化 より有用なモデルの根拠を提示する 準拠しているからですLLM Comparator はこれらの理由を複数のテーマに分類し、 どのモデルが各テーマに適しているかが強調されます。
モデル出力の違いを確認する: 組み込み関数とユーザー定義の比較関数を使用して、2 つのモデルの出力の違いを詳しく調査できます。このツールを使用すると、モデルが生成したテキスト内の特定のパターンをハイライト表示し、違いを明確に把握できます。
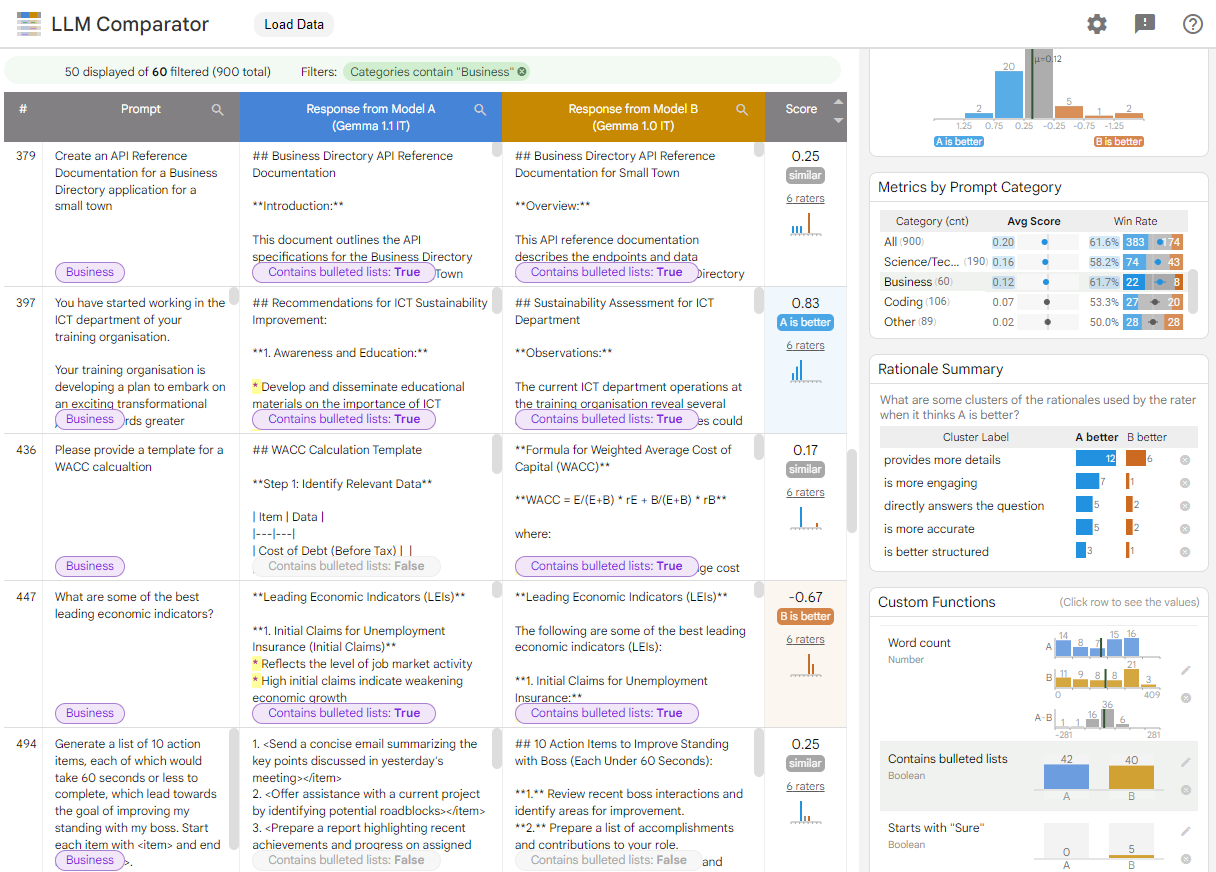
図 1. Gemma との比較を示す LLM コンパレータ インターフェース v1.0 に対して 7B v1.1 モデルに指示する
LLM コンパレータを使用すると、評価結果を並べて分析できます。モデルのパフォーマンスを複数の角度から視覚的に要約し、個々のモデル出力をインタラクティブに検査して詳細を把握できます。
LLM Comparator を使ってみる:
- このデモでは、Gemma Instruct 7B v1.1 のパフォーマンスを比較しています。 Gemma Instruct 7B v1.0 と Chatbot Arena Conversations データセット。
- この Colab ノートブックでは、Python ライブラリを使用して Vertex AI API を使用して小さな並列評価を実行し、結果をセル内の LLM 比較ツールアプリに読み込みます。
LLM Comparator について詳しくは、研究論文と GitHub リポジトリ。