Gemini puede analizar la entrada de audio y generar respuestas de texto.
Python
from google import genai
import base64
client = genai.Client()
uploaded_file = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const uploadedFile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mp3" }
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
REST
# First upload the file, then use the URI:
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": "YOUR_FILE_URI",
"mime_type": "audio/mp3"
}
]
}'
Descripción general
Gemini puede analizar y comprender la entrada de audio, y generar respuestas de texto, lo que permite casos de uso como los siguientes:
- Describir, resumir o responder preguntas sobre contenido de audio
- Transcripción y traducción (voz a texto)
- Identificación de interlocutores (identificación de diferentes interlocutores)
- Detección de emociones en el habla y la música
- Análisis de segmentos específicos con marcas de tiempo
Para las interacciones de voz y video en tiempo real, consulta la API de Live. Para los modelos dedicados de voz a texto con compatibilidad para la transcripción en tiempo real, usa la API de Google Cloud Speech-to-Text.
Transcribe voz a texto
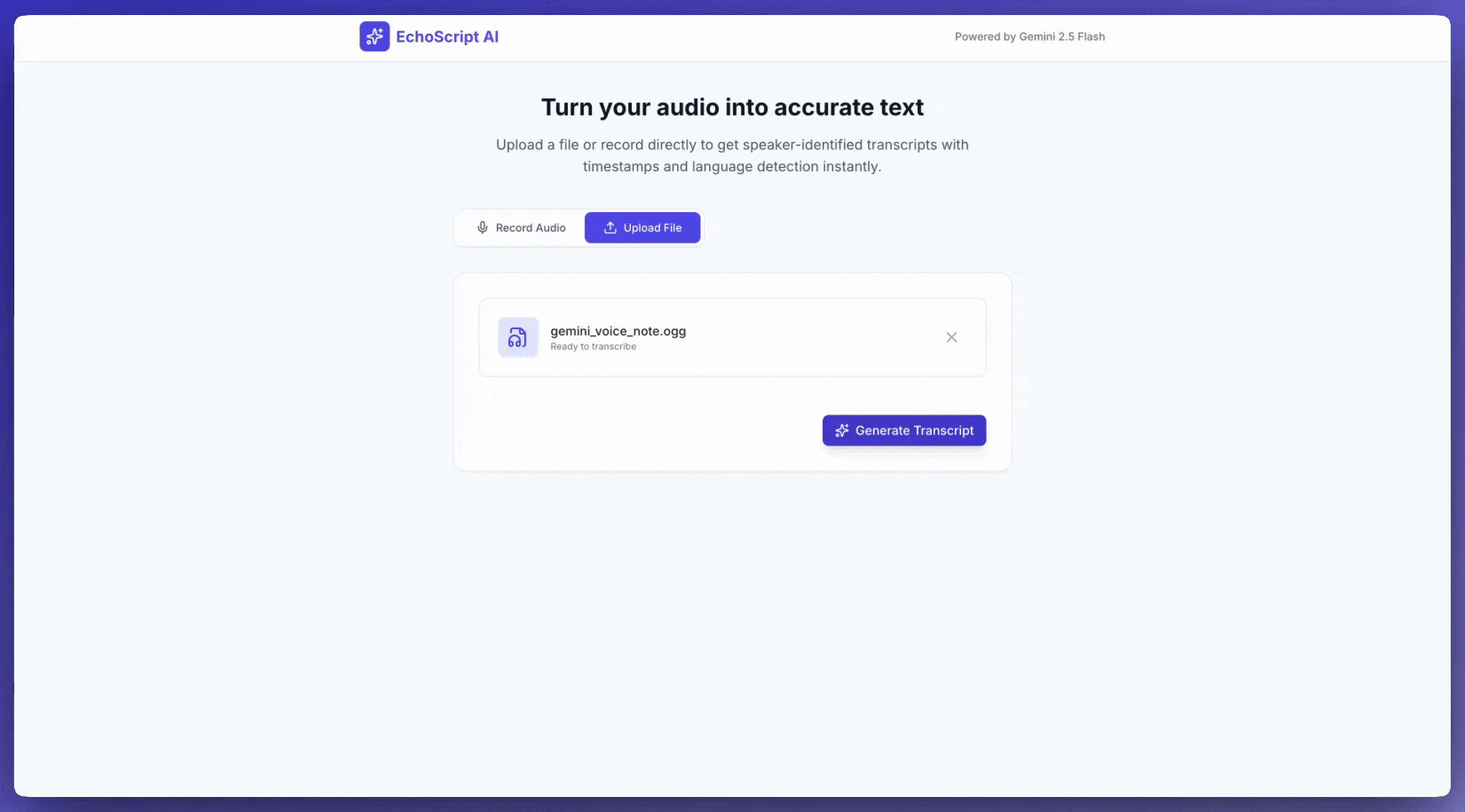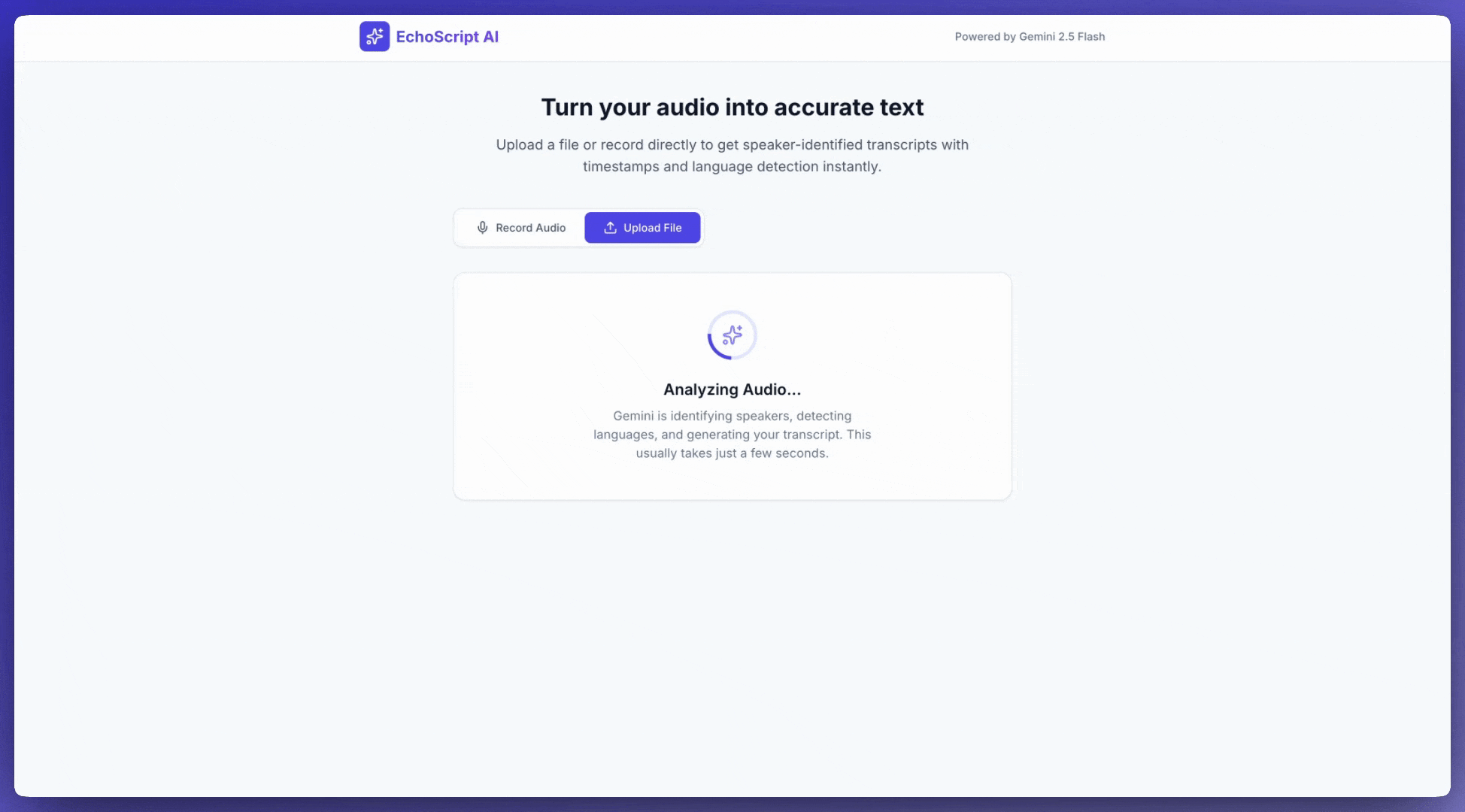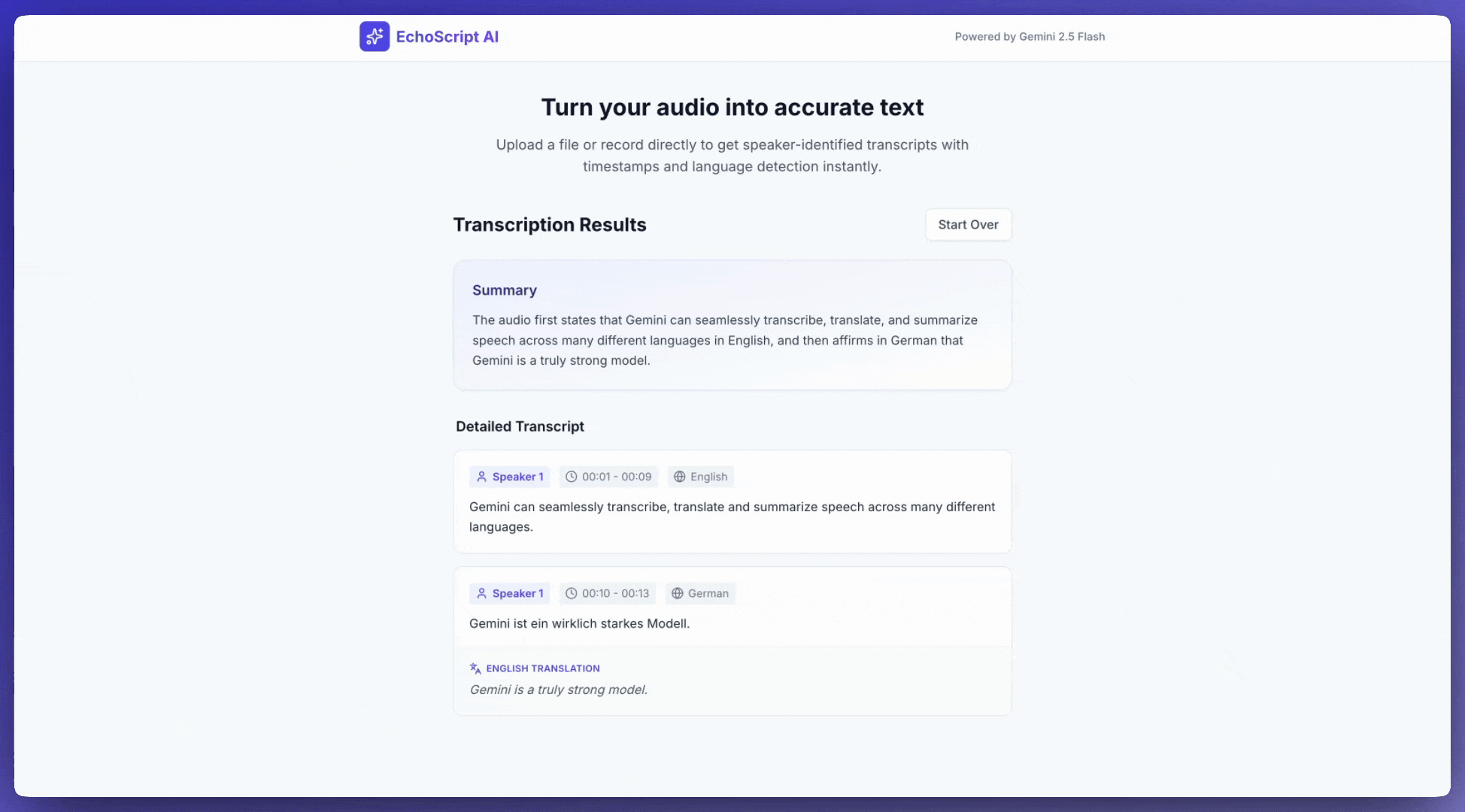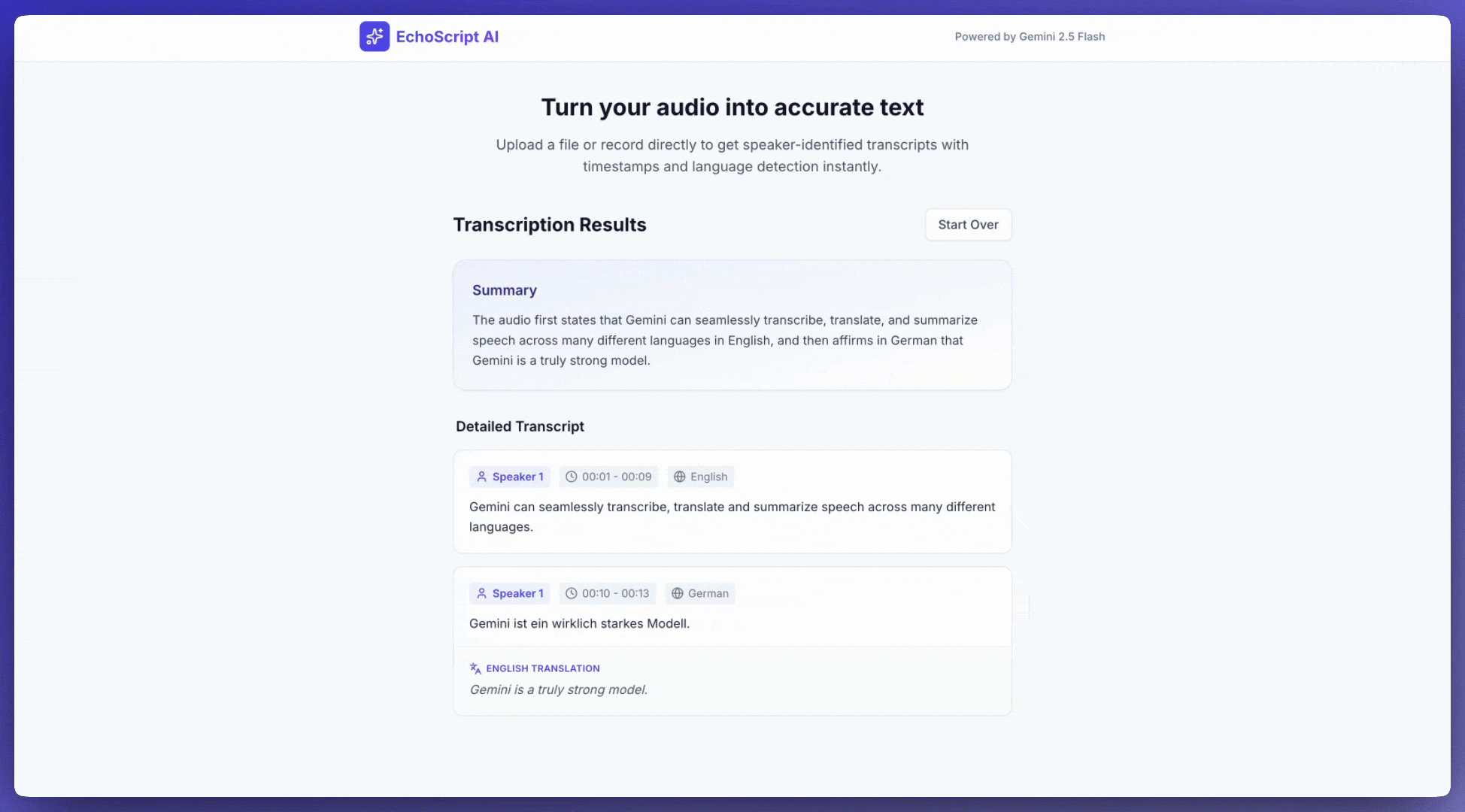
En este ejemplo, se muestra cómo transcribir, traducir y resumir el habla con marcas de tiempo, identificación de interlocutores y detección de emociones mediante resultados estructurados.
Python
from google import genai
client = genai.Client()
YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM"
prompt = """
Process the audio file and generate a detailed transcription.
Requirements:
1. Identify distinct speakers (e.g., Speaker 1, Speaker 2).
2. Provide accurate timestamps for each segment (Format: MM:SS).
3. Detect the primary language of each segment.
4. If not English, provide the English translation.
5. Identify the primary emotion: Happy, Sad, Angry, or Neutral.
6. Provide a brief summary at the beginning.
"""
response_schema = {
"type": "object",
"properties": {
"summary": {"type": "string"},
"segments": {
"type": "array",
"items": {
"type": "object",
"properties": {
"speaker": {"type": "string"},
"timestamp": {"type": "string"},
"content": {"type": "string"},
"language": {"type": "string"},
"emotion": {
"type": "string",
"enum": ["happy", "sad", "angry", "neutral"]
}
},
"required": ["speaker", "timestamp", "content", "emotion"]
}
}
},
"required": ["summary", "segments"]
}
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "video", "uri": YOUTUBE_URL, "mime_type": "video/mp4"},
{"type": "text", "text": prompt}
],
response_format=response_schema,
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM";
const prompt = `
Process the audio file and generate a detailed transcription.
Requirements:
1. Identify distinct speakers (e.g., Speaker 1, Speaker 2).
2. Provide accurate timestamps for each segment (Format: MM:SS).
3. Detect the primary language of each segment.
4. If not English, provide the English translation.
5. Identify the primary emotion: Happy, Sad, Angry, or Neutral.
6. Provide a brief summary at the beginning.
`;
const responseSchema = {
type: "object",
properties: {
summary: { type: "string" },
segments: {
type: "array",
items: {
type: "object",
properties: {
speaker: { type: "string" },
timestamp: { type: "string" },
content: { type: "string" },
language: { type: "string" },
emotion: {
type: "string",
enum: ["happy", "sad", "angry", "neutral"]
}
},
required: ["speaker", "timestamp", "content", "emotion"]
}
}
},
required: ["summary", "segments"]
};
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "video", uri: YOUTUBE_URL, mime_type: "video/mp4" },
{ type: "text", text: prompt }
],
response_format: responseSchema,
});
console.log(JSON.parse(interaction.output_text));
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=ku-N-eS1lgM",
"mime_type": "video/mp4"
},
{
"type": "text",
"text": "Transcribe with speaker diarization and emotion detection."
}
],
"response_format": {
"type": "object",
"properties": {
"summary": {"type": "string"},
"segments": {
"type": "array",
"items": {
"type": "object",
"properties": {
"speaker": {"type": "string"},
"timestamp": {"type": "string"},
"content": {"type": "string"},
"emotion": {"type": "string", "enum": ["happy", "sad", "angry", "neutral"]}
}
}
}
}
}
}'
Audio de entrada
Puedes proporcionar datos de audio de las siguientes maneras:
- Sube un archivo de audio antes de realizar una solicitud.
- Pasa datos de audio intercalados con la solicitud.
Cómo subir un archivo de audio
Usa la API de Files para archivos de más de 20 MB.
Python
from google import genai
client = genai.Client()
uploaded_file = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const uploadedFile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mp3" }
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
REST
# First upload the file using the Files API, then use the URI:
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": "YOUR_FILE_URI",
"mime_type": "audio/mp3"
}
]
}'
Pasa datos de audio intercalados
Para archivos de audio pequeños con un tamaño total de solicitud inferior a 20 MB, haz lo siguiente:
Python
from google import genai
import base64
client = genai.Client()
with open('path/to/small-sample.mp3', 'rb') as f:
audio_bytes = f.read()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"data": base64.b64encode(audio_bytes).decode('utf-8'),
"mime_type": "audio/mp3"
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const client = new GoogleGenAI({});
const audioData = fs.readFileSync("path/to/small-sample.mp3", {
encoding: "base64"
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
data: audioData,
mime_type: "audio/mp3"
}
]
});
console.log(interaction.output_text);
REST
AUDIO_PATH="path/to/sample.mp3"
if [[ "$(base64 --version 2>&1)" = *"FreeBSD"* ]]; then
B64FLAGS="--input"
else
B64FLAGS="-w0"
fi
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"data": "'$(base64 $B64FLAGS $AUDIO_PATH)'",
"mime_type": "audio/mp3"
}
]
}'
Notas sobre los datos de audio intercalados: * El tamaño máximo de la solicitud es de 20 MB en total (incluidas las instrucciones y todos los archivos). * Para volver a usar el archivo, súbelo.
Obtén una transcripción
Para obtener una transcripción, solicítala en la instrucción:
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Generate a transcript of the speech."},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "text", text: "Generate a transcript of the speech." },
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
Consulta las marcas de tiempo
Usa el formato MM:SS para hacer referencia a secciones específicas:
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Provide a transcript from 02:30 to 03:29."},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
JavaScript
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "text", text: "Provide a transcript from 02:30 to 03:29." },
{ type: "audio", uri: uploadedFile.uri, mime_type: "audio/mp3" }
]
});
Cuenta tokens
Cuenta tokens en un archivo de audio:
Python
response = client.models.count_tokens(
model="gemini-3.5-flash",
contents=[uploaded_file]
)
print(response)
JavaScript
const response = await client.models.countTokens({
model: "gemini-3.5-flash",
contents: [
{ fileData: { fileUri: uploadedFile.uri, mimeType: uploadedFile.mimeType } }
]
});
console.log(response.totalTokens);
Formatos de audio compatibles
- WAV -
audio/wav - MP3 -
audio/mp3 - AIFF -
audio/aiff - AAC -
audio/aac - OGG Vorbis -
audio/ogg - FLAC -
audio/flac
Detalles técnicos sobre el audio
- Tokens: 32 tokens por segundo de audio (1 minuto = 1,920 tokens)
- Sonidos no verbales: Gemini comprende los sonidos no verbales (canto de pájaros, sirenas, etcétera).
- Duración máxima: 9.5 horas de audio por instrucción
- Resolución: Submuestreado a 16 Kbps
- Canales: Audio multicanal combinado en un solo canal
¿Qué sigue?
- API de Files: Sube y administra archivos de audio
- Instrucciones del sistema: Personaliza el comportamiento del modelo
- Resultados estructurados: Obtén resultados de transcripción en formato JSON