Binjakët mund të analizojnë të dhënat audio dhe të gjenerojnë përgjigje me tekst.
Python
from google import genai
import base64
client = genai.Client()
uploaded_file = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const uploadedFile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mp3" }
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
PUSHTIM
# First upload the file, then use the URI:
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": "YOUR_FILE_URI",
"mime_type": "audio/mp3"
}
]
}'
Përmbledhje
Gemini mund të analizojë dhe kuptojë të dhënat audio dhe të gjenerojë përgjigje me tekst, duke mundësuar raste përdorimi si:
- Përshkruani, përmbledhni ose përgjigjuni pyetjeve rreth përmbajtjes audio
- Transkriptim dhe përkthim (nga të folurit në tekst)
- Diarizimi i folësit (identifikimi i folësve të ndryshëm)
- Zbulimi i emocioneve në të folur dhe muzikë
- Analizimi i segmenteve specifike me vula kohore
Për ndërveprimet me zë dhe video në kohë reale, shihni Live API . Për modele të dedikuara të të folurit në tekst me mbështetje për transkriptim në kohë reale, përdorni Google Cloud Speech-to-Text API .
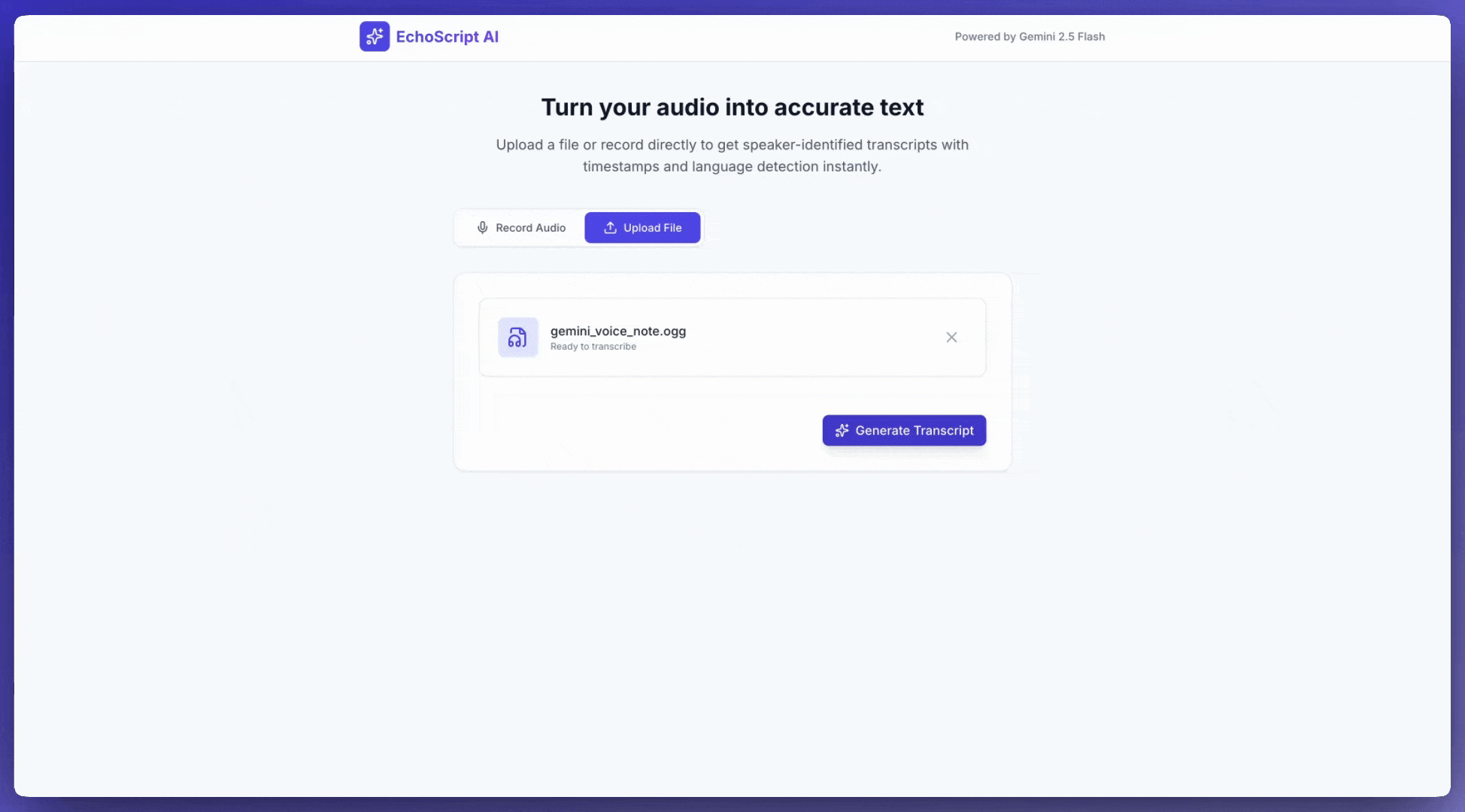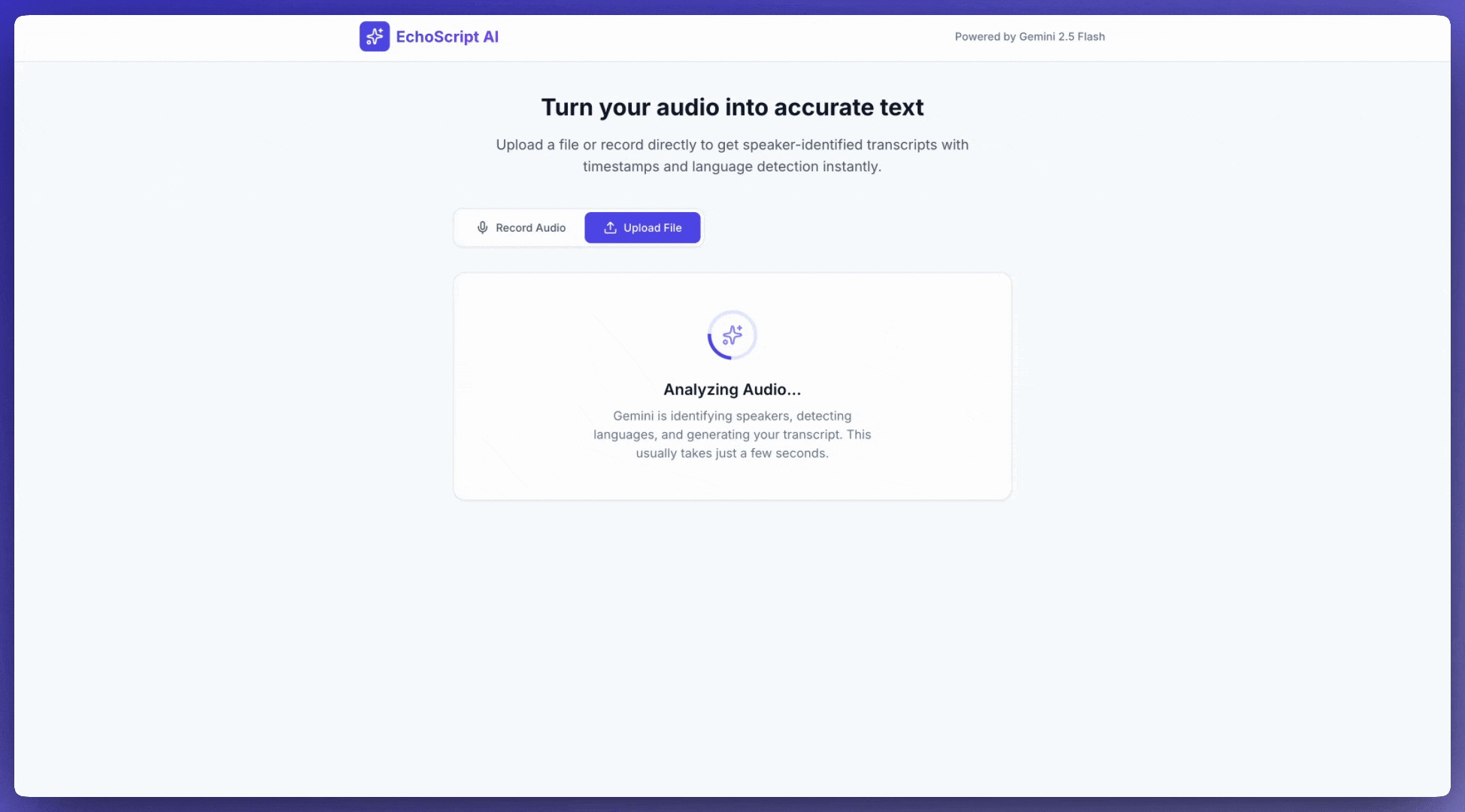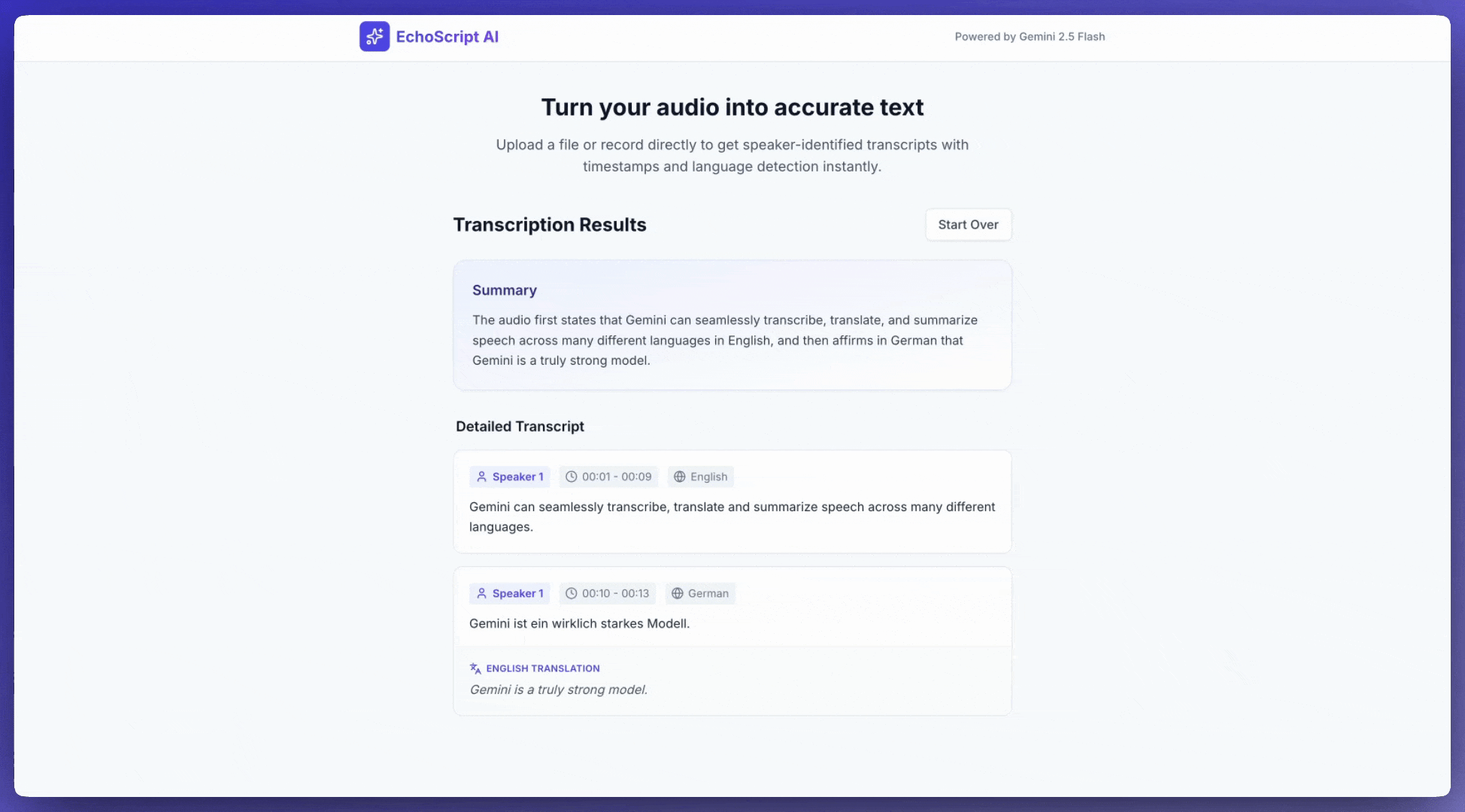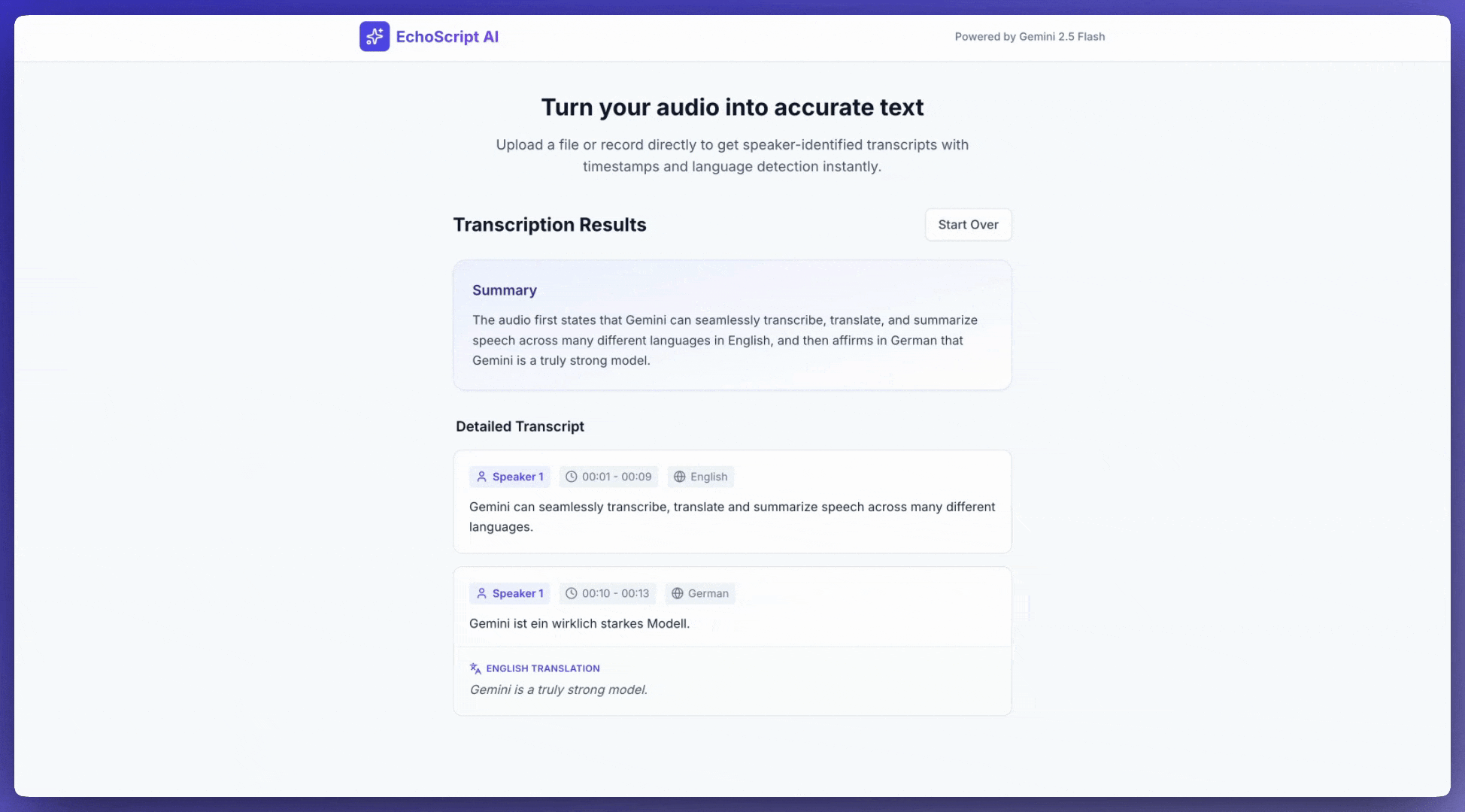
Transkripto të folurit në tekst
Ky shembull tregon se si të transkriptohet, përkthehet dhe përmblidhet fjalimi me vula kohore, ditarizim të folësit dhe zbulim të emocioneve duke përdorur rezultate të strukturuara .
Python
from google import genai
client = genai.Client()
YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM"
prompt = """
Process the audio file and generate a detailed transcription.
Requirements:
1. Identify distinct speakers (e.g., Speaker 1, Speaker 2).
2. Provide accurate timestamps for each segment (Format: MM:SS).
3. Detect the primary language of each segment.
4. If not English, provide the English translation.
5. Identify the primary emotion: Happy, Sad, Angry, or Neutral.
6. Provide a brief summary at the beginning.
"""
response_schema = {
"type": "object",
"properties": {
"summary": {"type": "string"},
"segments": {
"type": "array",
"items": {
"type": "object",
"properties": {
"speaker": {"type": "string"},
"timestamp": {"type": "string"},
"content": {"type": "string"},
"language": {"type": "string"},
"emotion": {
"type": "string",
"enum": ["happy", "sad", "angry", "neutral"]
}
},
"required": ["speaker", "timestamp", "content", "emotion"]
}
}
},
"required": ["summary", "segments"]
}
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "video", "uri": YOUTUBE_URL, "mime_type": "video/mp4"},
{"type": "text", "text": prompt}
],
response_format=response_schema,
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM";
const prompt = `
Process the audio file and generate a detailed transcription.
Requirements:
1. Identify distinct speakers (e.g., Speaker 1, Speaker 2).
2. Provide accurate timestamps for each segment (Format: MM:SS).
3. Detect the primary language of each segment.
4. If not English, provide the English translation.
5. Identify the primary emotion: Happy, Sad, Angry, or Neutral.
6. Provide a brief summary at the beginning.
`;
const responseSchema = {
type: "object",
properties: {
summary: { type: "string" },
segments: {
type: "array",
items: {
type: "object",
properties: {
speaker: { type: "string" },
timestamp: { type: "string" },
content: { type: "string" },
language: { type: "string" },
emotion: {
type: "string",
enum: ["happy", "sad", "angry", "neutral"]
}
},
required: ["speaker", "timestamp", "content", "emotion"]
}
}
},
required: ["summary", "segments"]
};
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "video", uri: YOUTUBE_URL, mime_type: "video/mp4" },
{ type: "text", text: prompt }
],
response_format: responseSchema,
});
console.log(JSON.parse(interaction.output_text));
PUSHTIM
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=ku-N-eS1lgM",
"mime_type": "video/mp4"
},
{
"type": "text",
"text": "Transcribe with speaker diarization and emotion detection."
}
],
"response_format": {
"type": "object",
"properties": {
"summary": {"type": "string"},
"segments": {
"type": "array",
"items": {
"type": "object",
"properties": {
"speaker": {"type": "string"},
"timestamp": {"type": "string"},
"content": {"type": "string"},
"emotion": {"type": "string", "enum": ["happy", "sad", "angry", "neutral"]}
}
}
}
}
}
}'
Hyrje audioje
Ju mund të jepni të dhëna audio në mënyrat e mëposhtme:
- Ngarko një skedar audio përpara se të bësh një kërkesë.
- Kaloni të dhënat audio të integruara me kërkesën.
Ngarko një skedar audio
Përdorni API-n e Skedarëve për skedarë më të mëdhenj se 20 MB.
Python
from google import genai
client = genai.Client()
uploaded_file = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const uploadedFile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mp3" }
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
PUSHTIM
# First upload the file using the Files API, then use the URI:
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": "YOUR_FILE_URI",
"mime_type": "audio/mp3"
}
]
}'
Kaloni të dhënat audio në linjë
Për skedarë të vegjël audio nën madhësinë totale të kërkesës 20MB:
Python
from google import genai
import base64
client = genai.Client()
with open('path/to/small-sample.mp3', 'rb') as f:
audio_bytes = f.read()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"data": base64.b64encode(audio_bytes).decode('utf-8'),
"mime_type": "audio/mp3"
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const client = new GoogleGenAI({});
const audioData = fs.readFileSync("path/to/small-sample.mp3", {
encoding: "base64"
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
data: audioData,
mime_type: "audio/mp3"
}
]
});
console.log(interaction.output_text);
PUSHTIM
AUDIO_PATH="path/to/sample.mp3"
if [[ "$(base64 --version 2>&1)" = *"FreeBSD"* ]]; then
B64FLAGS="--input"
else
B64FLAGS="-w0"
fi
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"data": "'$(base64 $B64FLAGS $AUDIO_PATH)'",
"mime_type": "audio/mp3"
}
]
}'
Shënime mbi të dhënat audio të integruara: * Madhësia maksimale e kërkesës është gjithsej 20 MB (duke përfshirë kërkesat dhe të gjitha skedarët) * Për ripërdorim, ngarkoni skedarin në vend të tij
Merr një transkript
Për të marrë një transkript, kërkojeni atë në njoftim:
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Generate a transcript of the speech."},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "text", text: "Generate a transcript of the speech." },
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
Referojuni vulave kohore
Përdorni formatin MM:SS për t'iu referuar seksioneve specifike:
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Provide a transcript from 02:30 to 03:29."},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
JavaScript
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "text", text: "Provide a transcript from 02:30 to 03:29." },
{ type: "audio", uri: uploadedFile.uri, mime_type: "audio/mp3" }
]
});
Numëroni shenjat
Numëroni tokenët në një skedar audio:
Python
response = client.models.count_tokens(
model="gemini-3.5-flash",
contents=[uploaded_file]
)
print(response)
JavaScript
const response = await client.models.countTokens({
model: "gemini-3.5-flash",
contents: [
{ fileData: { fileUri: uploadedFile.uri, mimeType: uploadedFile.mimeType } }
]
});
console.log(response.totalTokens);
Formatet audio të mbështetura
- WAV -
audio/wav - MP3 -
audio/mp3 - AIFF -
audio/aiff - AAC -
audio/aac - OGG Vorbis -
audio/ogg - FLAC -
audio/flac
Detajet teknike rreth audios
- Tokenat : 32 tokena për sekondë audio (1 minutë = 1,920 tokena)
- Jo-folës : Binjakët i kuptojnë tingujt jo-folës (kënga e zogjve, sirenat, etj.)
- Gjatësia maksimale : 9.5 orë audio për çdo mesazh
- Rezolucioni : I reduktuar në 16 Kbps
- Kanalet : Audio shumëkanalëshe e kombinuar në një kanal të vetëm
Çfarë vjen më pas
- API-të e skedarëve : Ngarkoni dhe menaxhoni skedarët audio
- Udhëzime për sistemin : Personalizoni sjelljen e modelit
- Prodhim i strukturuar : Merrni rezultatet e transkriptimit në formatin JSON