
Ten przewodnik zawiera instrukcje konwertowania modeli Gemma w formacie Safetensors Hugging Face (.safetensors) na format pliku zadań MediaPipe (.task). Ta konwersja jest niezbędna do wdrażania wstępnie wytrenowanych lub dostrojonych modeli Gemma na potrzeby wnioskowania na urządzeniu z Androidem i iOS przy użyciu interfejsu MediaPipe LLM Inference API i środowiska wykonawczego LiteRT.
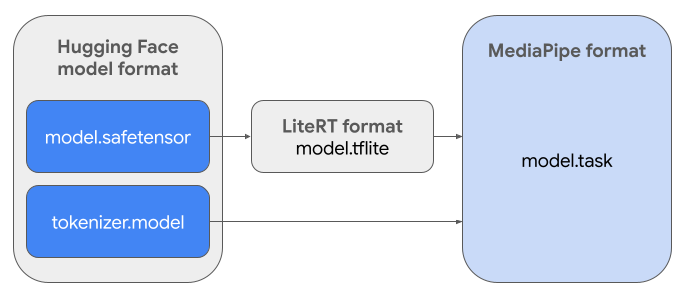
Aby utworzyć wymagany pakiet zadań (.task), użyjesz LiteRT Torch. To narzędzie eksportuje modele PyTorch do modeli LiteRT z wieloma sygnaturami (.tflite), które są zgodne z interfejsem MediaPipe LLM Inference API i nadają się do uruchamiania na backendach CPU w aplikacjach mobilnych.
Ostateczny plik .task to samodzielny pakiet wymagany przez MediaPipe, zawierający model LiteRT, model tokenizera i niezbędne metadane. Ten pakiet jest niezbędny, ponieważ tokenizator (który przekształca prompty tekstowe w wektory tokenów dla modelu) musi być spakowany z modelem LiteRT, aby umożliwić wnioskowanie od początku do końca.
Oto szczegółowy opis tego procesu:
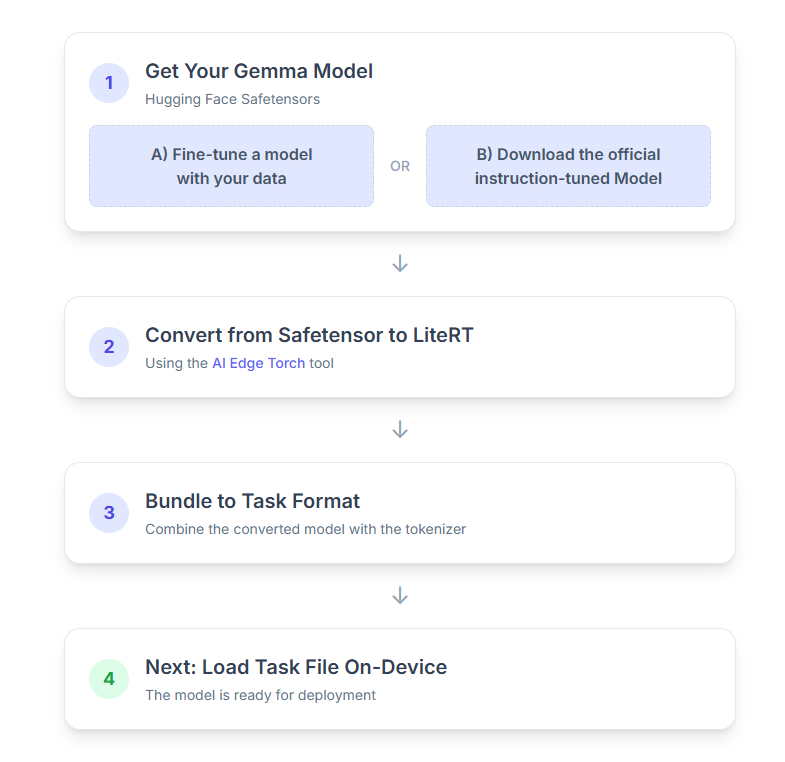
1. Pobieranie modelu Gemma
Możesz zacząć na 2 sposoby.
Opcja A. Korzystanie z istniejącego modelu dostrojonego
Jeśli masz przygotowany dostrojony model Gemma, przejdź do następnego kroku.
Opcja B. Pobieranie oficjalnego modelu dostosowanego do instrukcji
Jeśli potrzebujesz modelu, możesz pobrać model Gemma dostosowany do instrukcji z centrum Hugging Face.
Skonfiguruj niezbędne narzędzia:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
Pobierz model:
Modele w centrum Hugging Face są identyfikowane za pomocą identyfikatora modelu, zwykle w formacie <organization_or_username>/<model_name>. Aby na przykład pobrać oficjalny model Google Gemma 3 270M dostosowany do instrukcji, użyj tego polecenia:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. Konwertowanie i kwantyzowanie modelu do formatu LiteRT
Skonfiguruj środowisko wirtualne Pythona i zainstaluj najnowszą stabilną wersję pakietu LiteRT Torch:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
Aby przekonwertować model Safetensor na model LiteRT, użyj tego skryptu:
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
Pamiętaj, że ten proces jest czasochłonny i zależy od szybkości przetwarzania danych na komputerze. Na przykład na 8-rdzeniowym procesorze z 2025 r. model o wielkości 270 M zajmuje ponad 5–10 minut, a model o wielkości 1 B może zająć około 10–30 minut.
Wynikowy model LiteRT zostanie zapisany w określonym przez Ciebie OUTPUT_DIR_PATH.
Dostosuj poniższe wartości do ograniczeń pamięci i wydajności urządzenia docelowego.
kv_cache_max_len: określa łączny przydzielony rozmiar pamięci roboczej modelu (pamięci podręcznej KV). Ta pojemność jest sztywnym limitem i musi wystarczyć do przechowywania łącznej sumy tokenów prompta (wypełnienie wstępne) i wszystkich kolejno wygenerowanych tokenów (dekodowanie).prefill_seq_len: określa liczbę tokenów w prompcie wejściowym na potrzeby wstępnego wypełniania fragmentów. Podczas przetwarzania promptu wejściowego za pomocą dzielenia na fragmenty wstępnego wypełniania cała sekwencja (np. 50 tys.tokenów) nie jest obliczana od razu, ale dzielona na mniejsze segmenty (np. bloki po 2048 tokenów), które są kolejno wczytywane do pamięci podręcznej, aby zapobiec błędowi braku pamięci.quantize: ciąg tekstowy wybranych schematów kwantyzacji. Poniżej znajdziesz listę dostępnych przepisów na kwantyzację dla modelu Gemma 3.none: brak kwantyzacjifp16: wagi FP16, aktywacje FP32 i obliczenia zmiennoprzecinkowe dla wszystkich operacjidynamic_int8: aktywacje FP32, wagi INT8 i obliczenia całkowitoliczboweweight_only_int8: aktywacje FP32, wagi INT8 i obliczenia zmiennoprzecinkowe
3. Tworzenie pakietu zadań na podstawie LiteRT i tokenizatora
Skonfiguruj środowisko wirtualne Pythona i zainstaluj pakiet Pythona mediapipe:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
Użyj biblioteki genai.bundler, aby spakować model:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
Funkcja bundler.create_bundle tworzy plik .task, który zawiera wszystkie informacje niezbędne do uruchomienia modelu.
4. Wnioskowanie za pomocą MediaPipe na Androidzie
Zainicjuj zadanie za pomocą podstawowych opcji konfiguracji:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
Użyj metody generateResponse(), aby wygenerować odpowiedź tekstową.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
Aby przesyłać odpowiedź strumieniowo, użyj metody generateResponseAsync().
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
Więcej informacji znajdziesz w przewodniku po wnioskowaniu LLM na Androidzie.
Dalsze kroki
Twórz i odkrywaj więcej dzięki modelom Gemma:
- Wdrażanie Gemma na urządzeniach mobilnych
- Dostrajanie modelu Gemma do zadań tekstowych za pomocą biblioteki Transformers na platformie Hugging Face
- Dostrajanie modelu Gemma do zadań związanych z widzeniem za pomocą biblioteki Transformers na platformie Hugging Face
- Dostrajanie pełnego modelu za pomocą biblioteki Transformers na platformie Hugging Face