
|
|
|
|
|
 Wyświetl źródło w GitHubie Wyświetl źródło w GitHubie
|
Ten przewodnik pokazuje, jak dostroić model Gemma na zbiorze danych NPC z gry mobilnej za pomocą bibliotek Hugging Face Transformers i TRL. Dowiesz się:
- Konfigurowanie środowiska programistycznego
- Przygotowywanie zbioru danych do dostrajania
- Dostrajanie pełnego modelu Gemma za pomocą biblioteki TRL i klasy SFTTrainer
- Testowanie wnioskowania modelu i sprawdzanie jego działania
Konfigurowanie środowiska programistycznego
Pierwszym krokiem jest zainstalowanie bibliotek Hugging Face, w tym TRL i zbiorów danych, aby dostroić otwarty model, w tym różne techniki RLHF i dopasowywania.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
Uwaga: jeśli używasz procesora GPU z architekturą Ampere (np. NVIDIA L4) lub nowszą, możesz używać funkcji Flash Attention. Flash Attention to metoda, która znacznie przyspiesza obliczenia i zmniejsza zużycie pamięci z kwadratowego do liniowego w przypadku długości sekwencji, co przyspiesza trenowanie nawet 3-krotnie. Więcej informacji znajdziesz w artykule FlashAttention.
Zanim rozpoczniesz trenowanie, musisz zaakceptować warunki korzystania z Gemma. Możesz zaakceptować licencję na Hugging Face, klikając przycisk Agree and access repository (Zgadzam się i uzyskuję dostęp do repozytorium) na stronie modelu: http://huggingface.co/google/gemma-3-270m-it
Po zaakceptowaniu licencji musisz mieć ważny token Hugging Face, aby uzyskać dostęp do modelu. Jeśli korzystasz z Google Colab, możesz bezpiecznie używać tokena Hugging Face za pomocą sekretów Colab. W przeciwnym razie możesz ustawić token bezpośrednio w metodzie login. Upewnij się, że token ma też uprawnienia do zapisu, ponieważ podczas trenowania modelu będziesz przesyłać go do Hub.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
Możesz przechowywać wyniki na lokalnej maszynie wirtualnej Colab. Zdecydowanie zalecamy jednak zapisywanie wyników pośrednich na Dysku Google. Dzięki temu wyniki trenowania są bezpieczne, a Ty możesz łatwo porównywać i wybierać najlepszy model.
from google.colab import drive
drive.mount('/content/drive')
Wybierz model podstawowy do dostrojenia, dostosuj katalog punktów kontrolnych i szybkość uczenia się.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
Tworzenie i przygotowywanie zbioru danych do dostrajania
Zbiór danych bebechien/MobileGameNPC zawiera niewielką próbkę rozmów między graczem a 2 obcymi postaciami niezależnymi (Marsjaninem i Wenusjaninem), z których każda ma unikalny styl mówienia. Na przykład postać NPC z Marsa mówi z akcentem, w którym dźwięki „s” są zastępowane przez „z”, „da” oznacza „the”, „diz” oznacza „this”, a w wypowiedziach pojawiają się od czasu do czasu kliknięcia, np. *k'tak*.
Ten zbiór danych pokazuje kluczową zasadę dostrajania: wymagany rozmiar zbioru danych zależy od oczekiwanego wyniku.
- Aby nauczyć model wariantu stylistycznego języka, który już zna, np. akcentu Marsjanina, wystarczy niewielki zbiór danych zawierający od 10 do 20 przykładów.
- Aby jednak nauczyć model zupełnie nowego lub mieszanego języka obcego, potrzebny byłby znacznie większy zbiór danych.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
Dostrajanie modelu Gemma za pomocą biblioteki TRL i klasy SFTTrainer
Możesz teraz dostroić model. Biblioteka Hugging Face TRL SFTTrainer ułatwia nadzorowane dostrajanie otwartych modeli LLM. SFTTrainer jest podklasą Trainer z biblioteki transformers i obsługuje wszystkie te same funkcje.
Poniższy kod wczytuje model Gemma i tokenizator z Hugging Face.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
Przed dostrajaniem
Dane wyjściowe poniżej pokazują, że gotowe funkcje mogą nie być wystarczające w tym przypadku.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
W przykładzie powyżej sprawdzana jest podstawowa funkcja modelu, czyli generowanie dialogów w grze. Kolejny przykład ma na celu sprawdzenie spójności postaci. Testujemy model za pomocą prompta niezwiązanego z tematem. Na przykład Sorry, you are a game NPC., który wykracza poza bazę wiedzy postaci.
Celem jest sprawdzenie, czy model potrafi zachować swój charakter, zamiast odpowiadać na pytanie wyjęte z kontekstu. Będzie to punkt odniesienia do oceny, jak skutecznie proces dostrajania wpoił pożądaną osobowość.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
Możemy używać inżynierii promptów, aby sterować tonem odpowiedzi, ale wyniki mogą być nieprzewidywalne i nie zawsze zgodne z pożądaną przez nas osobowością.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
Szkolenia
Zanim rozpoczniesz trenowanie, musisz zdefiniować hiperparametry, których chcesz użyć w instancji SFTConfig.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
Masz już wszystkie elementy potrzebne do utworzenia SFTTrainer, aby rozpocząć trenowanie modelu.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
Rozpocznij trenowanie, wywołując metodę train().
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
Aby wykreślić straty trenowania i walidacji, zwykle wyodrębnia się te wartości z obiektu TrainerState lub z dzienników wygenerowanych podczas trenowania.
Biblioteki takie jak Matplotlib mogą być następnie używane do wizualizacji tych wartości w kolejnych krokach lub epokach trenowania. Oś X będzie przedstawiać kroki lub epoki trenowania, a oś Y – odpowiednie wartości funkcji straty.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
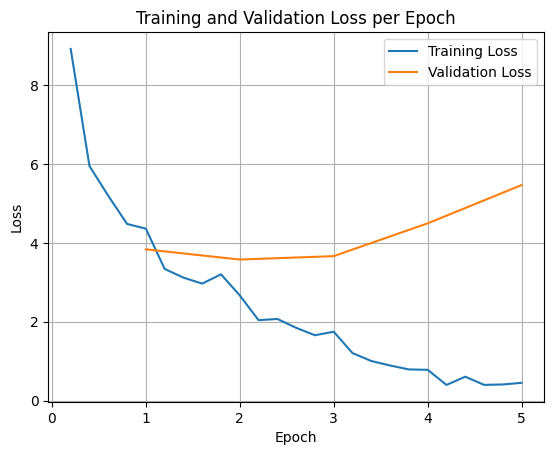
Ta wizualizacja pomaga monitorować proces trenowania i podejmować świadome decyzje dotyczące dostrajania hiperparametrów lub wczesnego zatrzymania.
Strata trenowania mierzy błąd na danych, na których trenowano model, a strata weryfikacji mierzy błąd na osobnym zbiorze danych, którego model wcześniej nie widział. Monitorowanie obu tych wartości pomaga wykrywać nadmierne dopasowanie (gdy model dobrze radzi sobie z danymi treningowymi, ale słabo z danymi, których wcześniej nie widział).
- strata weryfikacji >> strata trenowania: przetrenowanie
- strata weryfikacyjna > strata trenowania: pewne przetrenowanie
- strata walidacyjna < strata trenowania: pewne niedopasowanie
- strata weryfikacji << strata trenowania: niedopasowanie
Testowanie wnioskowania modelu
Po zakończeniu trenowania warto ocenić i przetestować model. Możesz wczytać różne próbki ze zbioru danych testowych i ocenić na nich model.
W tym konkretnym przypadku użycia wybór najlepszego modelu zależy od preferencji. Co ciekawe, to, co zwykle nazywamy „przetrenowaniem”, może być bardzo przydatne w przypadku postaci niezależnej w grze. Wymusza to na modelu zapomnienie ogólnych informacji i skupienie się na konkretnej osobie i cechach, na których został wytrenowany, dzięki czemu zachowuje spójny charakter.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Załadujmy wszystkie pytania z testowego zbioru danych i wygenerujmy dane wyjściowe.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
Jeśli wypróbujesz nasz oryginalny prompt ogólny, zobaczysz, że model nadal próbuje odpowiedzieć w wytrenowanym stylu. W tym przykładzie nadmierne dopasowanie i katastrofalne zapominanie są w rzeczywistości korzystne dla postaci niezależnej w grze, ponieważ zacznie ona zapominać ogólną wiedzę, która może nie mieć zastosowania. Dotyczy to też innych typów pełnego dostrajania, w których celem jest ograniczenie danych wyjściowych do określonych formatów.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
Podsumowanie i dalsze kroki
Z tego samouczka dowiesz się, jak w pełni dostroić model za pomocą biblioteki TRL. Zapoznaj się z tymi dokumentami:
- Dowiedz się, jak dostosować model Gemma do zadań tekstowych za pomocą biblioteki Hugging Face Transformers.
- Dowiedz się, jak dostosować model Gemma do zadań związanych z widzeniem za pomocą Hugging Face Transformers.
- Dowiedz się, jak wdrażać w Cloud Run