
برای درک DiffusionGemma، بررسی محدودیتهای اصلی مدلهای زبان استاندارد و تفاوتهای انتشار مبتنی بر متن مفید است.
مشکل مدلهای خودرگرسیون
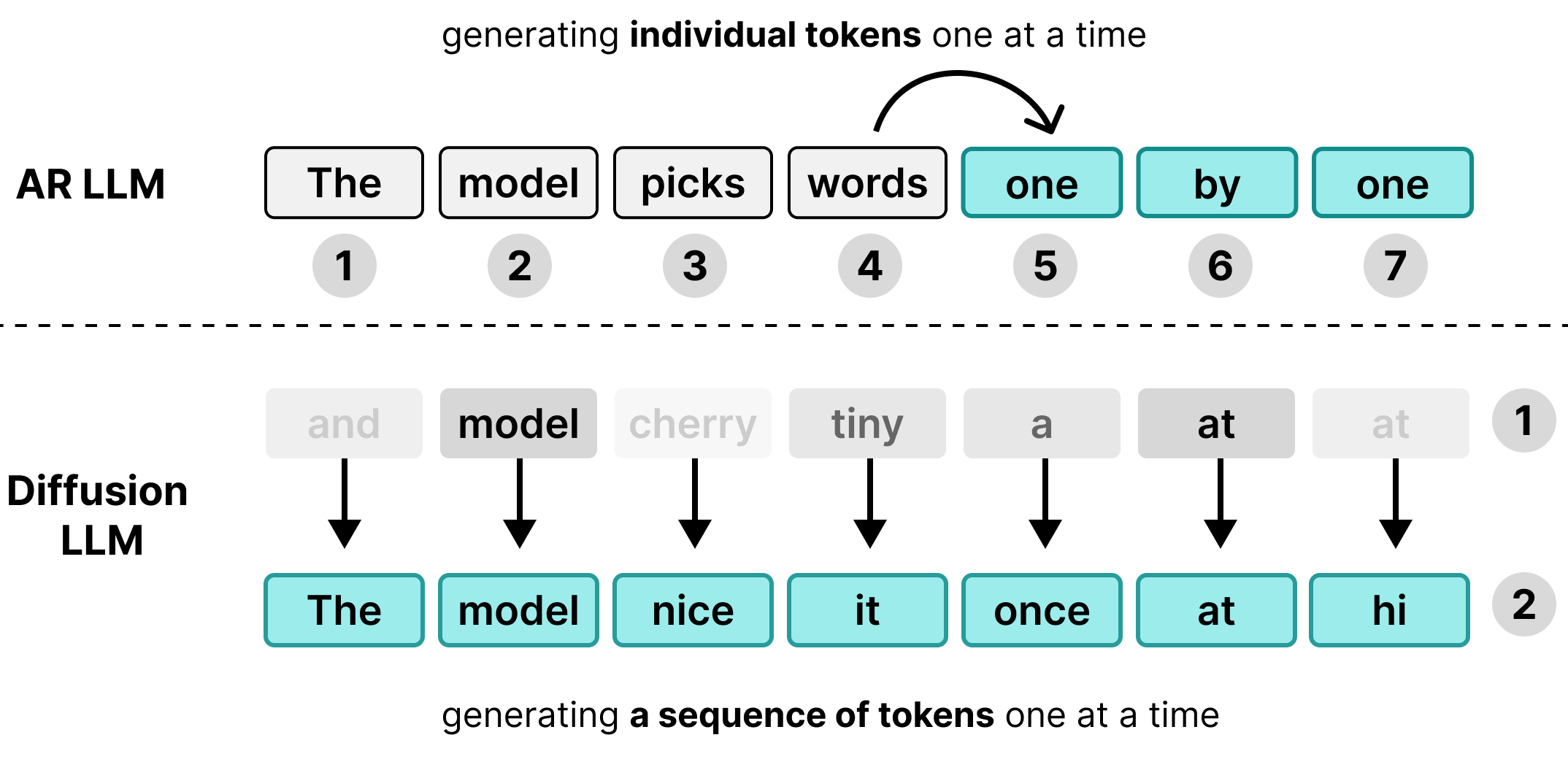
بسیاری از مدلهای زبان بزرگ (LLM) خودهمبسته هستند، به این معنی که متن را در هر زمان با یک توکن واحد تولید میکنند. اگرچه این رویکرد برای خدمترسانی همزمان به بسیاری از کاربران از طریق دستهبندی به خوبی کار میکند، اما برای کاربران منفرد، یک گلوگاه تأخیر ایجاد میکند.
در طول مرحله رمزگشایی، مدلهای استاندارد Transformer به جای اینکه به محاسبات وابسته باشند، به حافظه وابسته هستند. بیشتر زمان تولید صرف بارگذاری وزنهای مدل از حافظه سختافزار به واحدهای پردازش میشود، نه انجام محاسبات ریاضی واقعی. از آنجا که وزنها صرف نظر از اندازه دسته، فقط یک بار در هر مرحله نیاز به بارگذاری دارند، تولید یک توکن تقریباً به همان اندازه برای ۱ کاربر زمان میبرد که برای ۲۵۶ کاربر گروهبندی شده با هم.
در نتیجه، یک کاربر هیچ مزیتی در تأخیر نمیبیند؛ ظرفیت محاسباتی سختافزار در حالی که منتظر انتقال حافظه است، بیکار میماند.
DiffusionGemma از این زمان محاسباتی بیکار برای هر کاربر استفاده میکند. به جای تولید ۱ توکن برای ۲۵۶ کاربر جداگانه، ۲۵۶ توکن را به طور همزمان برای یک کاربر تولید میکند.
این مدل یک توالی خالی از ۲۵۶ توکن تصادفی - که بوم نامیده میشود - را مقداردهی اولیه میکند و به طور تکراری کل بوم را به طور همزمان ارزیابی و اصلاح میکند. این امر مدل را از حالت وابسته به حافظه به حالت وابسته به محاسبه تغییر میدهد و به آن اجازه میدهد تا با افزایش قدرت محاسباتی، سرعت پردازش را به طور مؤثر افزایش دهد.
| جنبه | خودرگرسیون متن | انتشار متن |
|---|---|---|
| تولید توکن | یک توکن در یک زمان | یک بوم کامل از توکنها به طور همزمان |
| مراحل | یک مرحله برای هر توکن | یک مرحله برای چندین توکن |
| ترتیب تولید | چپ به راست | همه موقعیتها به صورت موازی |
| نقطه شروع | دنباله خالی | توکنهای تصادفی از واژگان نمونهبرداری شدهاند |
| تصحیح خطا | ایستا؛ نمیتواند توکنهای گذشته را اصلاح کند | پویا؛ میتواند هر موقعیت بوم را اصلاح کند |
| تنگنای سختافزاری | مقید به حافظه | محدود به محاسبات |
| تمرکز بر توان عملیاتی | توان عملیاتی بالای چند کاربره | تأخیر بسیار کم تک کاربره |
درک مکانیک انتشار متن
در تولید تصویر، مدلهای انتشار با نویز گاوسی ۱۰۰٪ تصادفی شروع میشوند و به تدریج آن را طی چندین مرحله که توسط یک متن هدایت میشوند، حذف میکنند (نویززدایی). ترجمه این منطق به متن چالش برانگیزتر است زیرا توکنهای متنی، برخلاف مقادیر پیکسلی پیوسته، موجودیتهای گسستهای هستند.
DiffusionGemma از طریق پیشرفت روشهای تخصصی، به انتشار مبتنی بر متن دست مییابد:
۱. انتشار ماسکشده
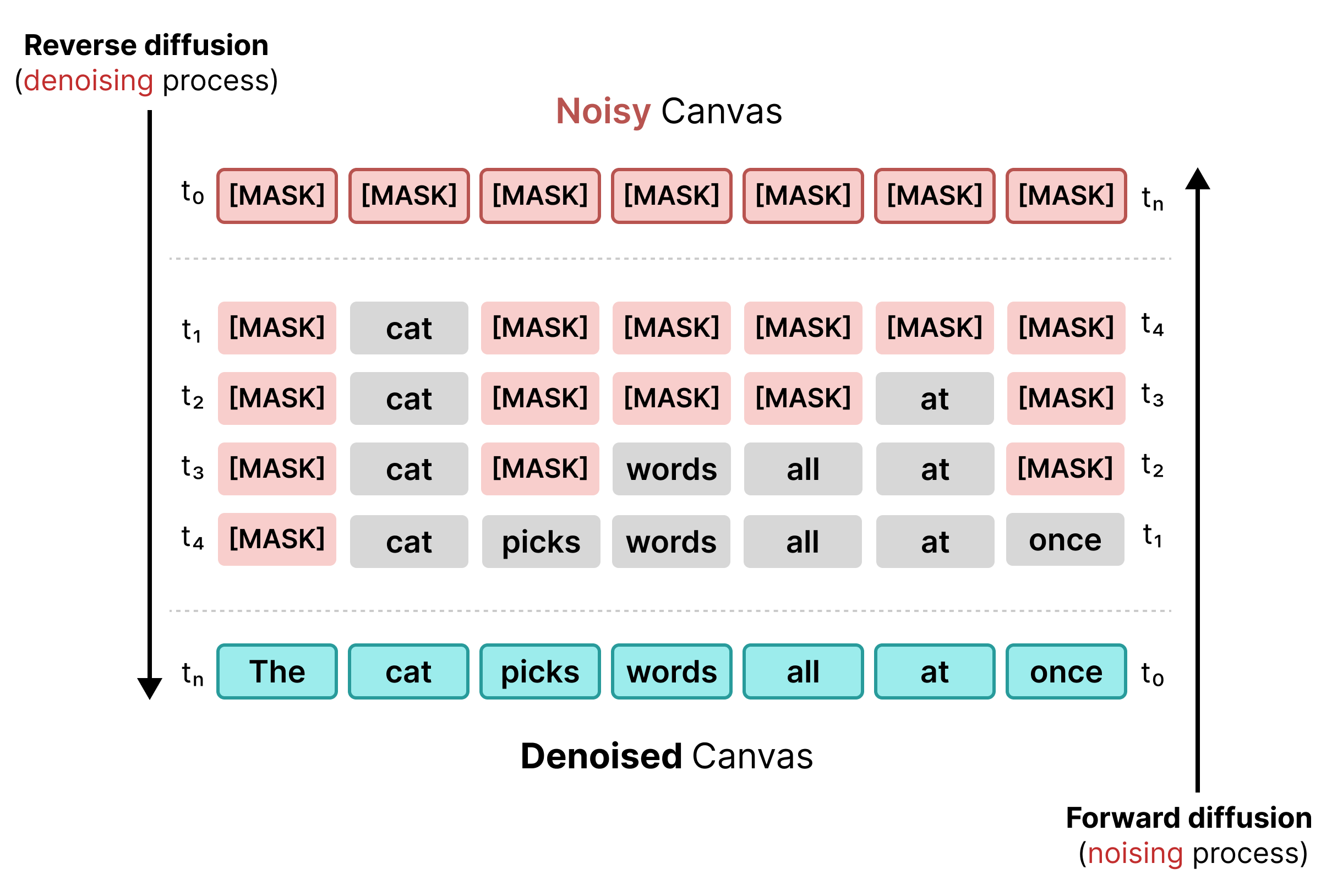
انتشار متن اولیه، مشابه آموزش BERT، بر ماسک کردن متکی بود. توکنهای تصادفی در یک دنباله با یک توکن [MASK] (که نشاندهنده نویز است) جایگزین میشوند. در طول انتشار معکوس، مدل توکن صحیح پشت ماسک را پیشبینی میکند و توکنها را در جایی که اطمینان به یک آستانه خاص میرسد، جایگزین میکند.
با این حال، انتشار پنهان از سختی رنج میبرد: به محض اینکه یک توکن [MASK] با یک کلمه جایگزین شود، قفل میشود. اگر زمینه اطراف تغییر کند، نمیتوان آن را در مراحل بعدی اصلاح کرد.
۲. نفوذ حالت یکنواخت
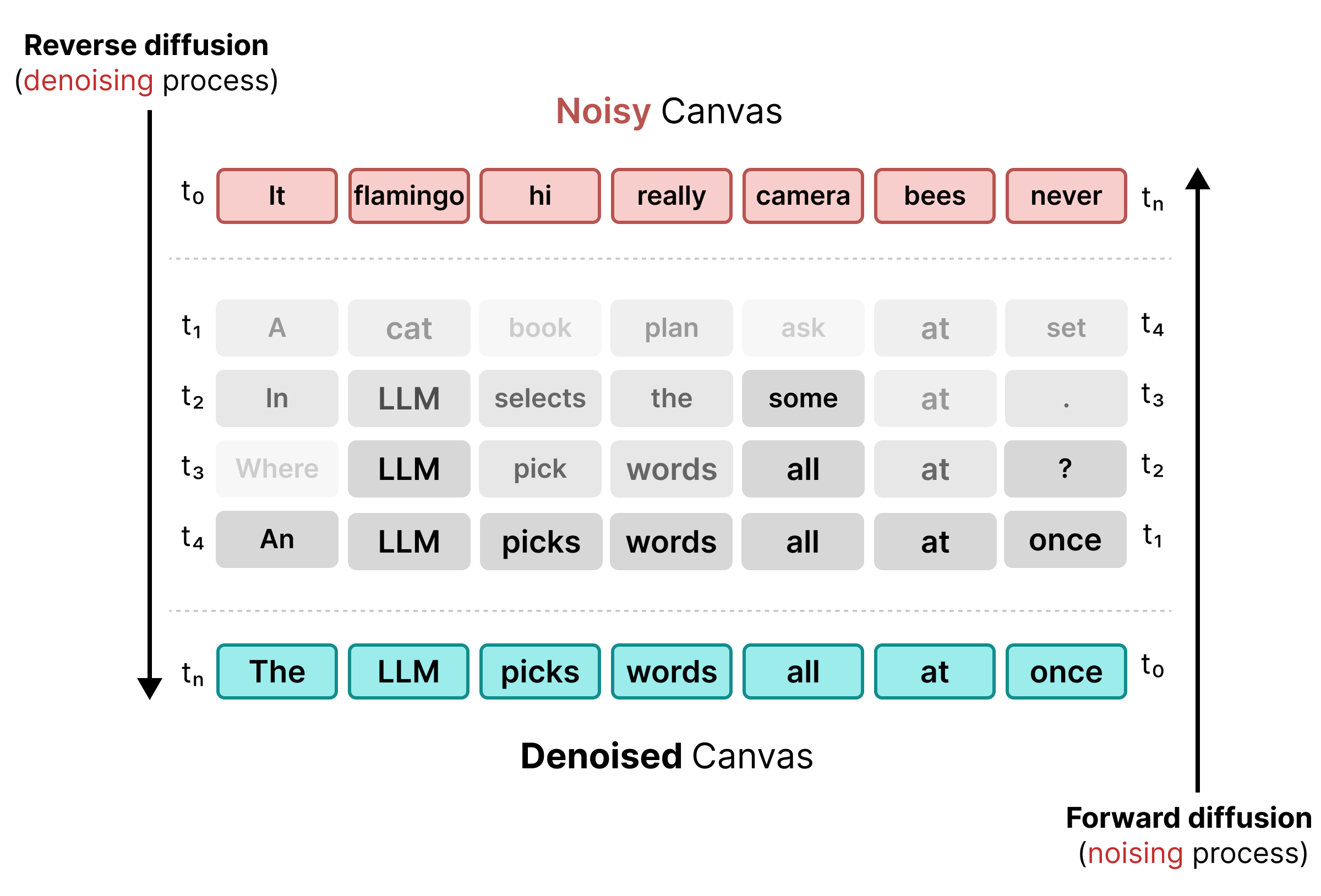
برای رفع محدودیتهای ماسکینگ، DiffusionGemma از Uniform State Diffusion استفاده میکند. به جای یک توکن صریح [MASK] ، نویز با جایگزینی کلمات اصلی با توکنهای کاملاً تصادفی از واژگان ایجاد میشود.
در طول فرآیند حذف نویز، مدل کل بوم را تجزیه و تحلیل میکند تا مشخص کند کدام توکنها نویز زمینهای هستند و آنها را بهروزرسانی میکند. اگر یک توکن صحیح باشد، احتمال بالایی را حفظ میکند. اگر احتمال یک توکن به دلیل ظهور زمینه جدید در مراحل بعدی از یک آستانه پایینتر بیاید، با یک توکن تصادفی جدید دوباره نویزدار میشود. این چرخه امکان اصلاح خطای مداوم و اصلاح موازی بوم را فراهم میکند.
معماری: پیشپرسازی افزایشی و حذف نویز
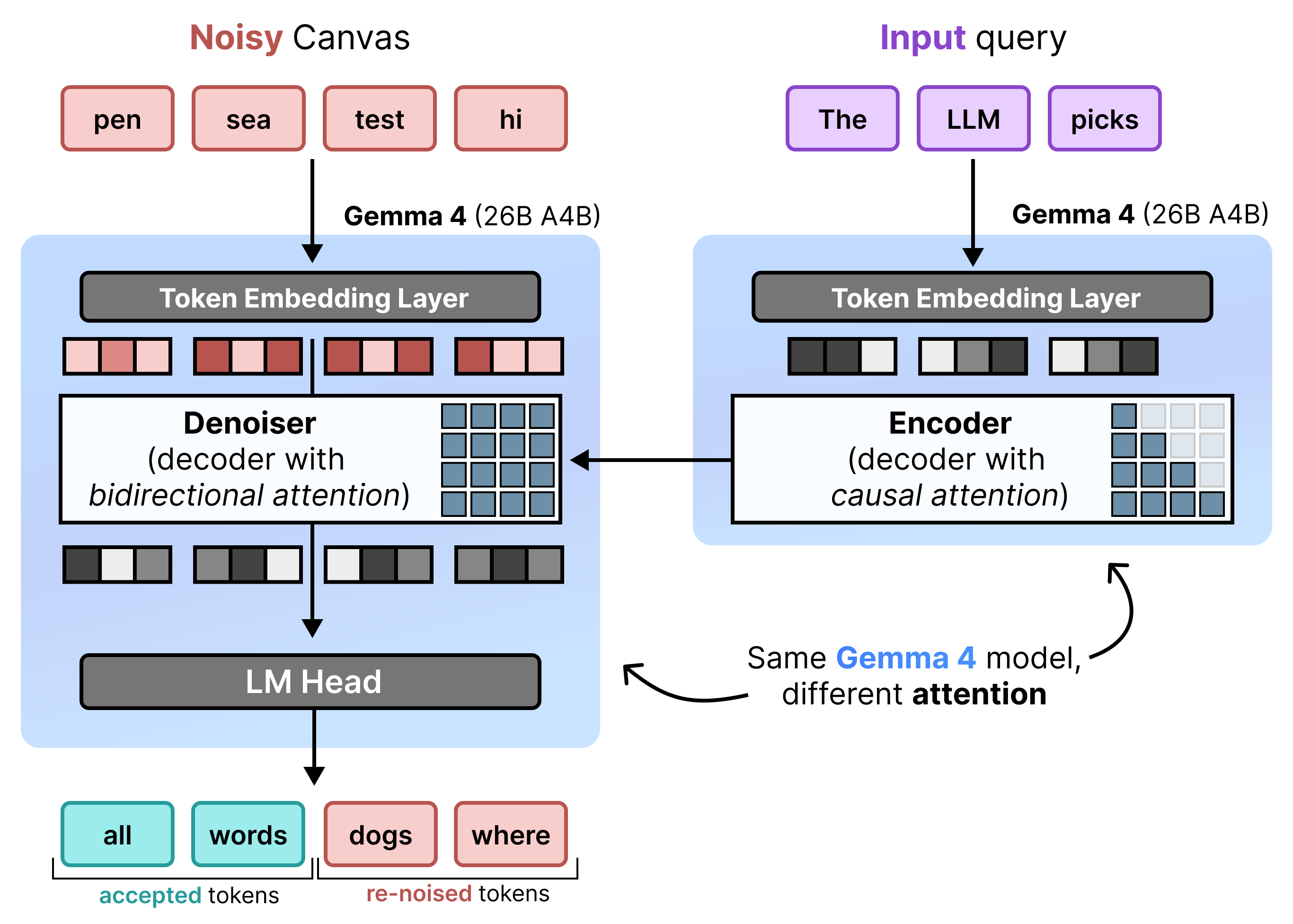
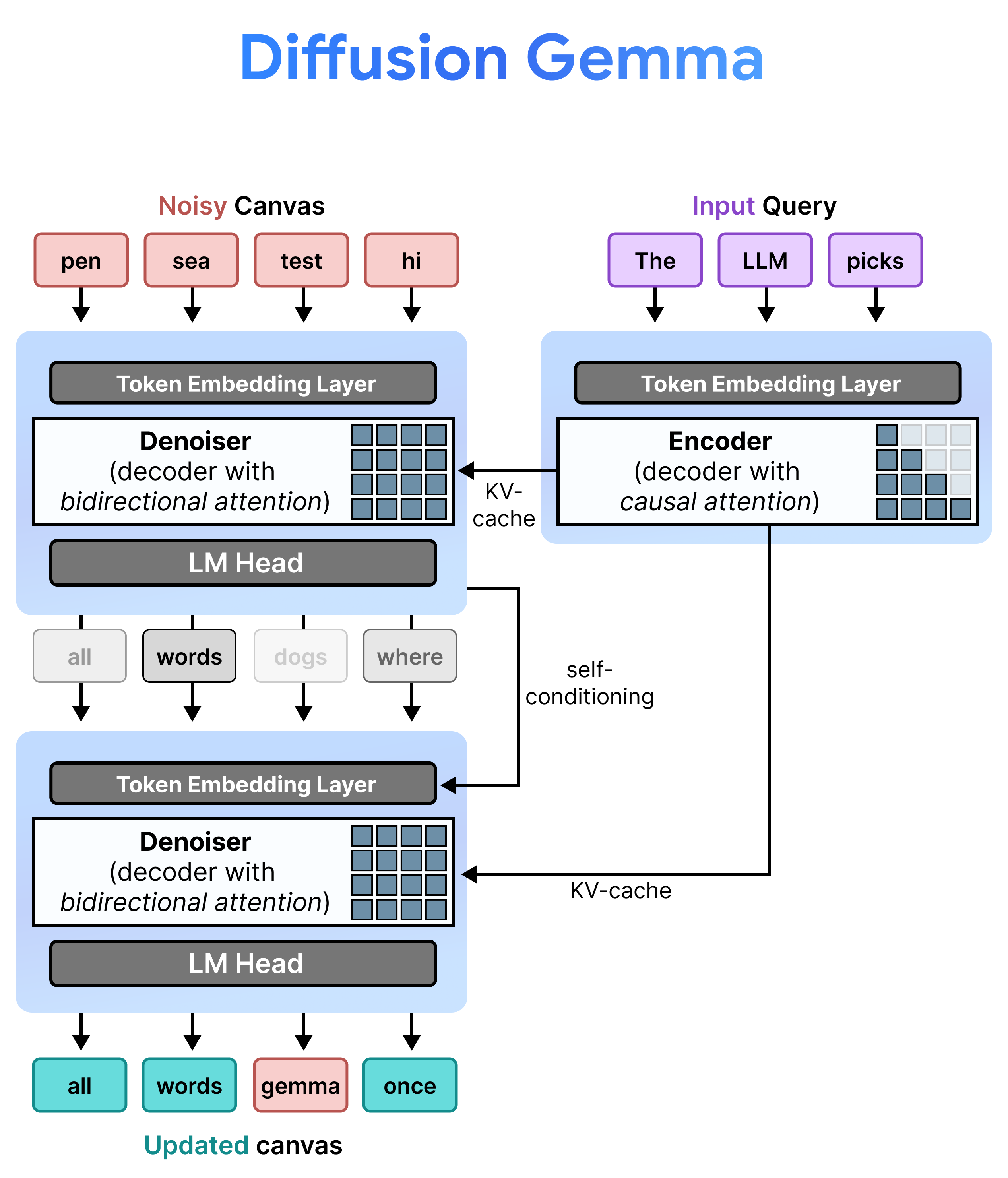
DiffusionGemma با تغییر متناوب بین Incremental Prefill و Denoising ، Uniform State Diffusion را به طور موثر پیادهسازی میکند. مدل Gemma 4 26B A4B به صورت بومی استفاده نمیشود، بلکه برای پشتیبانی از وظایف مختلف denoising و encoding به خوبی تنظیم شده است. به جای استفاده از مدلهای جداگانه، یک backbone واحد به صورت پویا بین دو حالت تغییر میکند:
- پیشپر کردن / پیشپر کردن افزایشی (علّی): از توجه سببی برای دریافت متن اعلان و نوشتن در حافظه پنهان KV استفاده میکند. این یک بار برای پیشپر کردن متن اولیه و سپس یک بار در هر بلوک برای افزودن هر بوم ۲۵۶ توکنی نهایی به حافظه پنهان KV قبل از ادامه حذف نویز بوم بعدی اجرا میشود.
- نویززدایی (دوطرفه): از توجه دوطرفه برای نویززدایی مکرر بوم استفاده میکند. توکنهای پرسوجو در هر موقعیتی روی بوم میتوانند به تمام توکنهای بوم دیگر (و همچنین حافظه پنهان KV) توجه کنند و به مدل اجازه دهند زمینه را به صورت دوطرفه پردازش کند.
چارچوبهای استنتاج پیشرفته
برای انتقال یک بوم از نویز خالص به متن نهایی، DiffusionGemma از مجموعهای از سیستمهای رمزگشایی اساسی استفاده میکند:
خود-تهویه
در طول استنتاج، رمزگشا (که با نام حذف نویز نیز شناخته میشود) حالت قبلی خود را حفظ میکند. پس از تکمیل مرحله حذف نویز، ماتریس توزیع احتمال تولید شده خود را در جدول جاسازی توکن ضرب میکند. این یک نمایش برداری محلی تولید میکند که حافظهای از پیشبینیهای قبلی و معیارهای اطمینان خود را در خود جای داده است و مستقیماً به مرحله بعدی منتقل میشود.
نمونهبرداری چند بوم (انتشار بلوکی)
از آنجا که یک canvas واحد به ۲۵۶ توکن محدود شده است، DiffusionGemma برای متنهای طولانی، انتشار و خودرگرسیون را به هم زنجیر میکند. این ابزار چرخههای انتشار را برای تولید یک بلوک کامل ۲۵۶ توکنی اجرا میکند، آن بلوک تکمیلشده را به متن اعلان اضافه میکند، حافظه پنهان KV رمزگذار را بهروزرسانی میکند و یک چرخه انتشار بوم ۲۵۶ توکنی کاملاً جدید را آغاز میکند.
خلاصه
مدلهای استاندارد زبان خودهمبسته متن را به صورت متوالی (یک توکن در هر زمان) تولید میکنند، که آنها را به حافظه وابسته میکند و باعث ایجاد گلوگاه تأخیر برای کاربران میشود. DiffusionGemma این مشکل را با تغییر به یک مدل وابسته به محاسبات که به طور همزمان یک "بوم" کامل با ۲۵۶ توکن تولید میکند، حل میکند.
با استفاده از انتشار حالت یکنواخت ، این مدل متن را با نویز واژگان تصادفی جایگزین میکند و به طور تکراری کل بوم را به صورت موازی اصلاح میکند. این مدل از یک Gemma 4 26B A4B تنظیمشده دقیق برای پشتیبانی از وظایف مختلف حذف نویز و رمزگذاری استفاده میکند. چارچوبهای پیشرفتهای مانند خودتنظیمی، نمونهبرداری بلوکی چند بوم به مدل اجازه میدهد تا خطاها را به صورت پویا اصلاح کند، تولید فرمهای طولانی را مدیریت کند و به تأخیر تککاربره بسیار کمی دست یابد.