
Per comprendere DiffusionGemma, è utile esaminare i limiti principali dei modelli linguistici standard e le differenze rispetto alla diffusione basata sul testo.
Il problema con i modelli autoregressivi
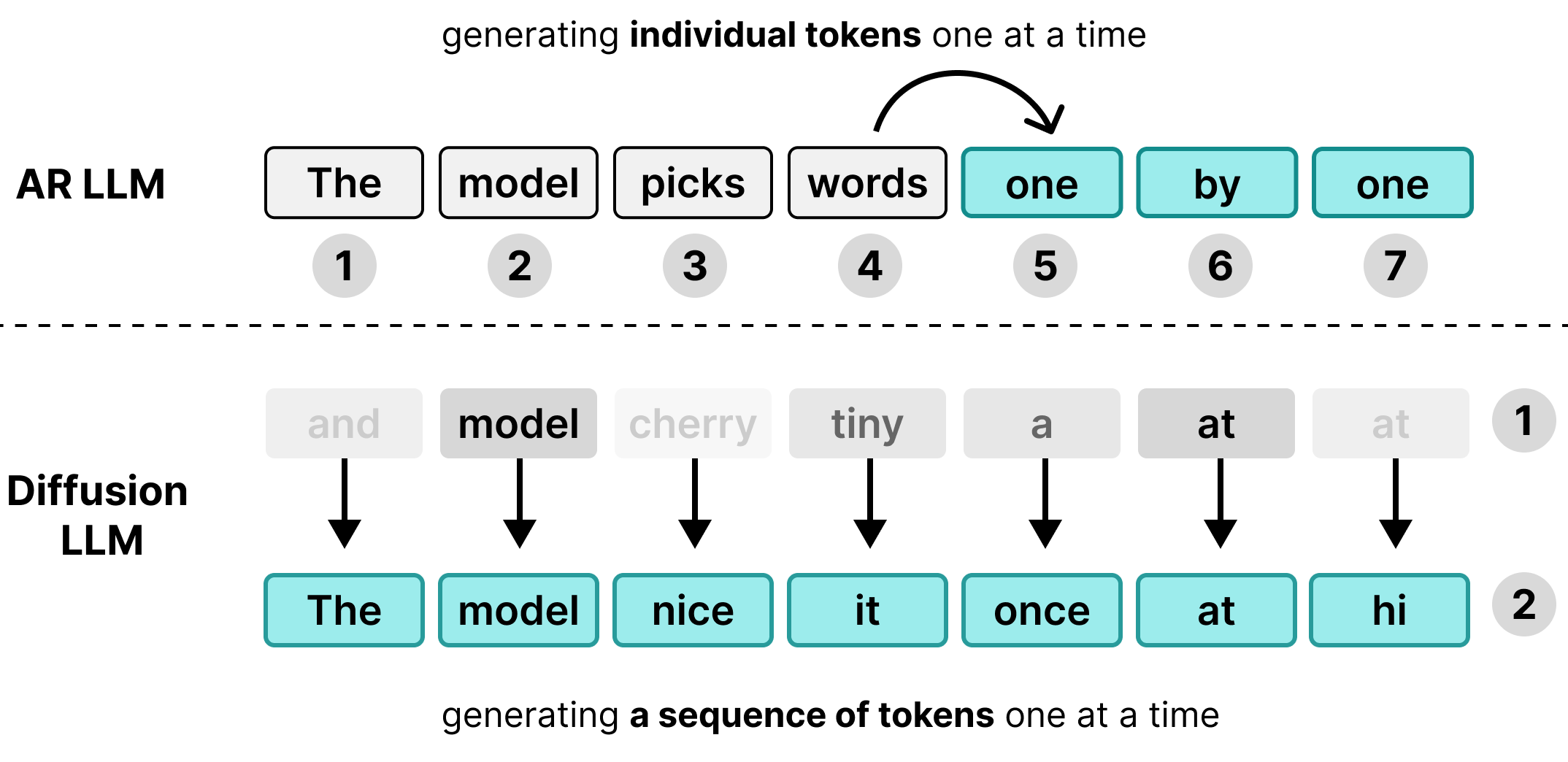
Molti modelli linguistici di grandi dimensioni (LLM) sono autoregressivi, il che significa che generano il testo un token alla volta. Sebbene questo approccio funzioni bene per servire molti utenti contemporaneamente tramite il batching, crea un collo di bottiglia di latenza per i singoli utenti.
Durante la fase di decodifica, i modelli Transformer standard sono vincolati alla memoria anziché al calcolo. La maggior parte del tempo di generazione viene spesa per caricare i pesi del modello dalla memoria hardware nelle unità di elaborazione, anziché per eseguire i calcoli matematici effettivi. Poiché i pesi devono essere caricati una sola volta per passaggio, indipendentemente dalla dimensione del batch, la generazione di un token richiede quasi la stessa quantità di tempo per 1 utente e per 256 utenti raggruppati.
Di conseguenza, un singolo utente non vede alcun vantaggio in termini di latenza; la capacità di calcolo dell'hardware rimane inattiva durante l'attesa dei trasferimenti di memoria.
DiffusionGemma utilizza questo tempo di calcolo inattivo per il singolo utente. Anziché generare 1 token per 256 utenti separati, genera 256 token contemporaneamente per un singolo utente.
Il modello inizializza una sequenza vuota di 256 token casuali, chiamata canvas, e valuta e perfeziona iterativamente l'intero canvas contemporaneamente. In questo modo, il modello passa da essere vincolato alla memoria a vincolato al calcolo, il che gli consente di scalare in modo efficiente le velocità di elaborazione man mano che aumenta la potenza di calcolo.
| Aspetto | Autoregressione del testo | Diffusione del testo |
|---|---|---|
| Generazione di token | Un token alla volta | Un canvas completo di token contemporaneamente |
| Passi | Un passaggio per ogni token | Un passaggio per più token |
| Ordine di generazione | Da sinistra a destra | Tutte le posizioni in parallelo |
| Punto iniziale | Sequenza vuota | Token casuali campionati dal vocabolario |
| Correzione degli errori | Statica; non è possibile rivedere i token precedenti | Dinamica; è possibile rivedere qualsiasi posizione del canvas |
| Collo di bottiglia hardware | Vincolato alla memoria | Vincolato al calcolo |
| Focus sul throughput | Throughput multiutente elevato | Latenza molto bassa per un singolo utente |
Comprendere le meccaniche di diffusione del testo
Nella generazione di immagini, i modelli di diffusione iniziano con un rumore gaussiano casuale al 100% e lo rimuovono progressivamente (denoising) in più passaggi guidati da un prompt di testo. La traduzione di questa logica in testo è più complessa perché i token di testo sono entità discrete, a differenza dei valori dei pixel continui.
DiffusionGemma ottiene la diffusione basata sul testo attraverso una progressione di metodologie specializzate:
1. Diffusione mascherata
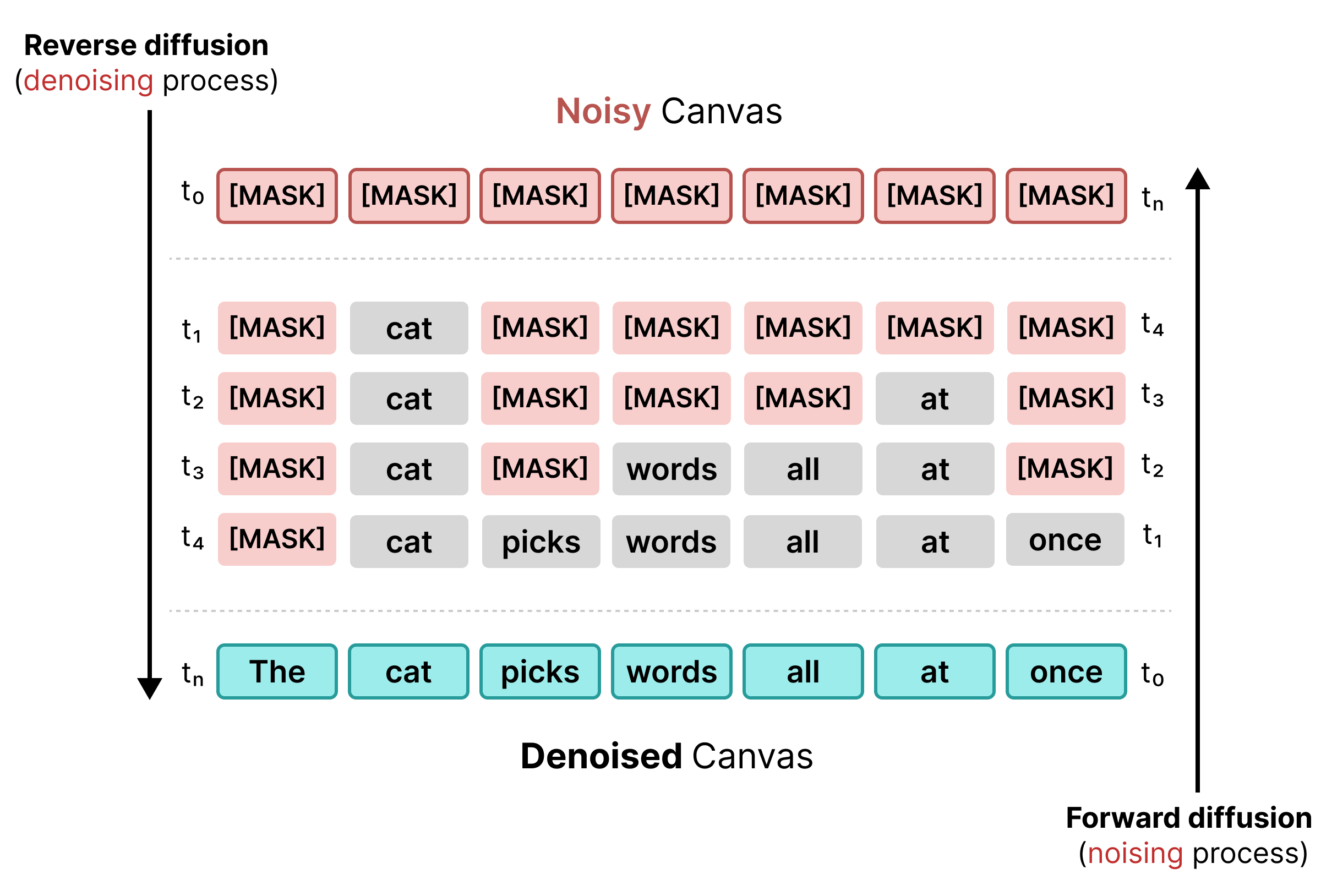
La diffusione del testo iniziale si basava sulla maschera, simile all'addestramento BERT. I token casuali in una sequenza vengono sostituiti con un token [MASK] (che rappresenta il rumore). Durante la diffusione inversa, il modello prevede il token corretto dietro la maschera, sostituendo i token in cui l'affidabilità soddisfa una soglia specifica.
Tuttavia, la diffusione mascherata soffre di rigidità: una volta che un token [MASK] viene sostituito con una parola, viene bloccato. Non può essere corretto nei passaggi successivi se il contesto circostante cambia.
2. Diffusione dello stato uniforme
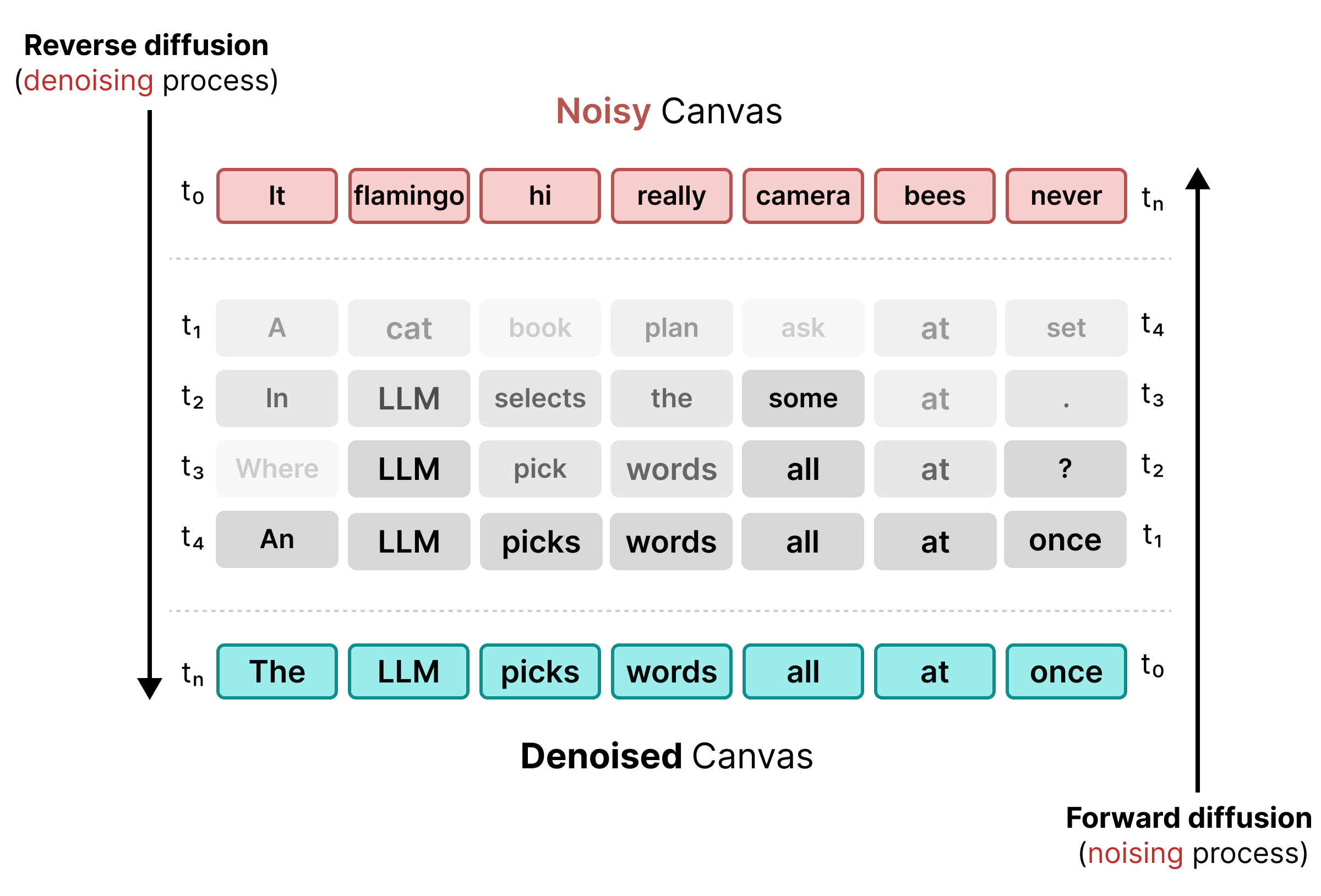
Per risolvere i limiti della maschera, DiffusionGemma utilizza la diffusione dello stato uniforme. Anziché un token [MASK] esplicito, il rumore viene introdotto sostituendo le parole originali con token casuali dal vocabolario.
Durante il processo di denoising, il modello analizza l'intero canvas per determinare quali token sono rumore contestuale e li aggiorna. Se un token è corretto, mantiene una probabilità elevata. Se la probabilità di un token scende al di sotto di una soglia a causa del nuovo contesto che emerge nei passaggi successivi, viene ri-rumorizzato con un nuovo token casuale. Questo ciclo consente la correzione continua degli errori e il perfezionamento parallelo del canvas.
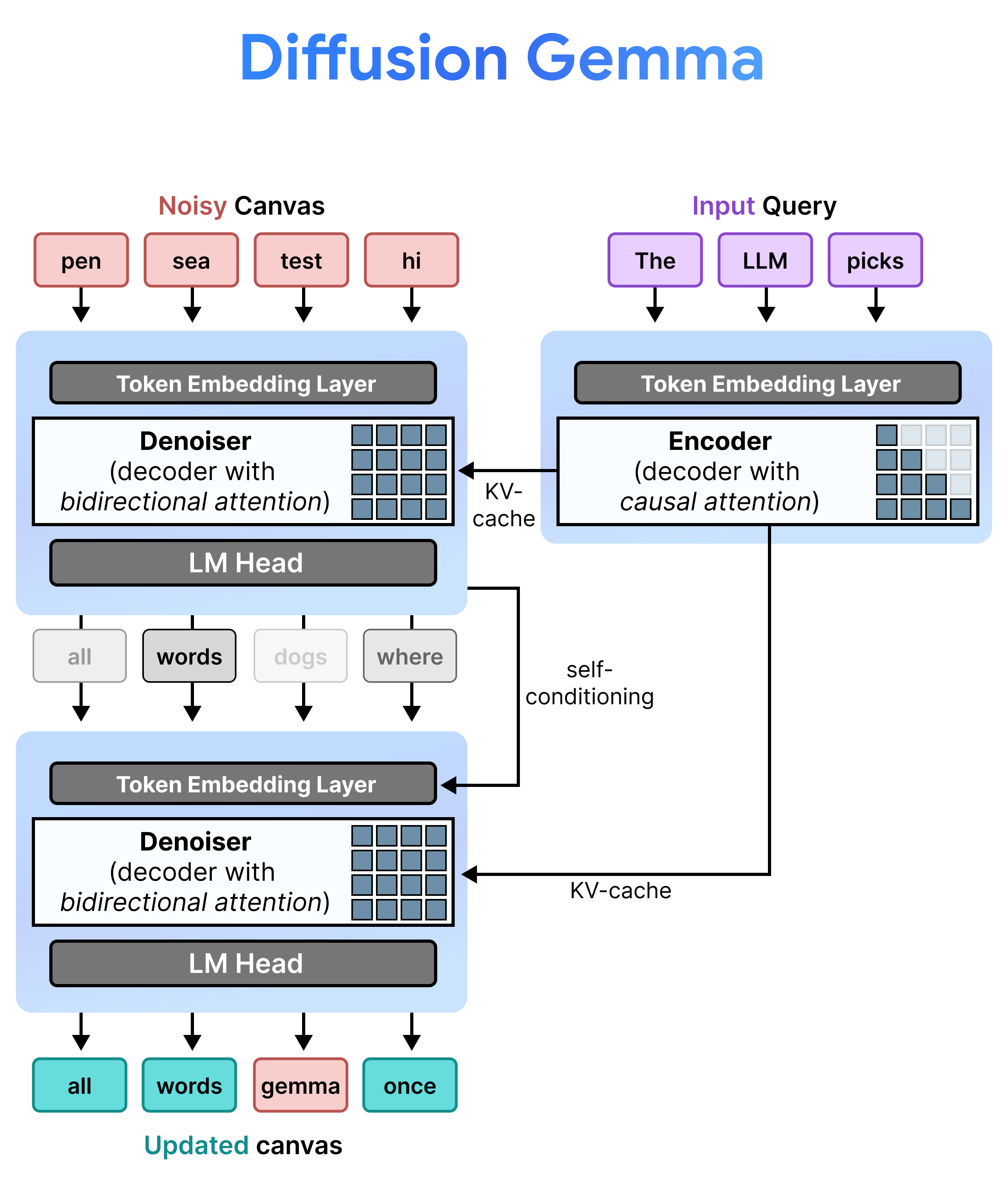
Architettura: il prefill incrementale e il denoising
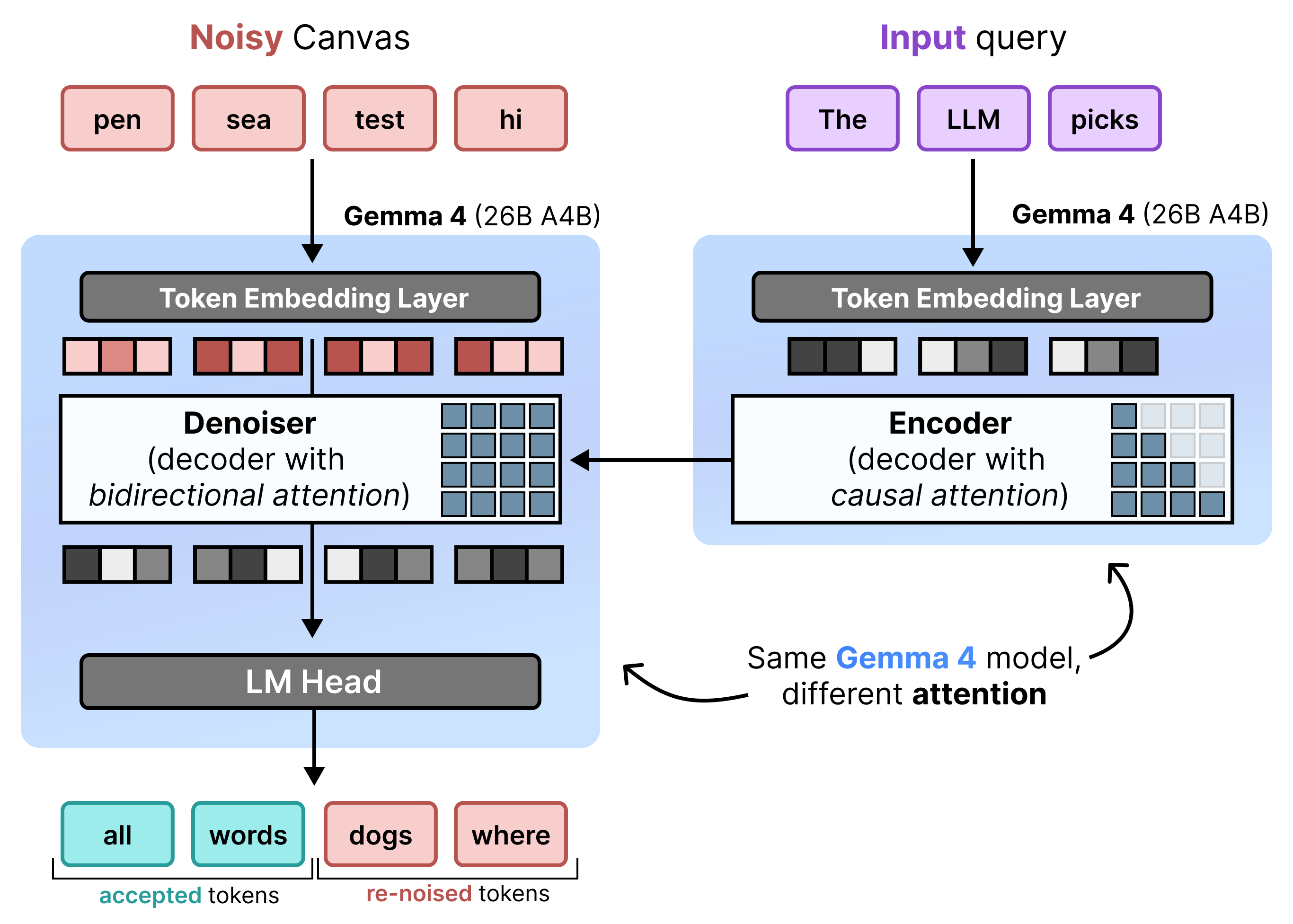
DiffusionGemma implementa in modo efficiente la diffusione dello stato uniforme alternando prefill incrementale e denoising. Il modello Gemma 4 26B A4B non viene utilizzato in modo nativo, ma viene ottimizzato per supportare le diverse attività di denoising e codifica. Anziché utilizzare modelli separati, un singolo backbone passa dinamicamente da una modalità all'altra:
- Prefill / prefill incrementale (causale): utilizza l'attenzione causale per inserire il contesto del prompt e scrivere nella cache KV. Viene eseguito una volta per precompilare il contesto iniziale e poi una volta per blocco per aggiungere ogni canvas di 256 token finalizzato alla cache KV prima di procedere al denoising del canvas successivo.
- Denoising (bidirezionale): utilizza l'attenzione bidirezionale per eseguire iterativamente il denoising del canvas. I token di query in qualsiasi posizione del canvas possono accedere a tutti gli altri token del canvas (nonché alla cache KV), consentendo al modello di elaborare il contesto in modo bidirezionale.
Framework di inferenza avanzati
Per spostare un canvas dal rumore puro al testo finalizzato, DiffusionGemma utilizza una raccolta di sistemi di decodifica sottostanti:
Autocondizionamento
Durante l'inferenza, il decoder (noto anche come denoiser) mantiene il suo stato precedente. Dopo aver completato un passaggio di denoising, moltiplica la matrice di distribuzione della probabilità generata per la tabella di incorporamento dei token. In questo modo viene prodotta una rappresentazione vettoriale localizzata che contiene una memoria delle previsioni precedenti e delle metriche di affidabilità, che viene passata direttamente al passaggio successivo.
Campionamento multi-canvas (diffusione a blocchi)
Poiché un singolo canvas è fisso a 256 token, DiffusionGemma concatena la diffusione e l'autoregressione per il testo in formato lungo. Esegue cicli di diffusione per generare un blocco completo di 256 token, aggiunge il blocco completato al contesto del prompt, aggiorna la cache KV dell'encoder e avvia un nuovo ciclo di diffusione del canvas di 256 token.
Riepilogo
I modelli linguistici autoregressivi standard generano il testo in sequenza (un token alla volta), il che li rende vincolati alla memoria e crea un collo di bottiglia di latenza per i singoli utenti. DiffusionGemma risolve questo problema passando a un modello vincolato al calcolo che genera contemporaneamente un "canvas" completo di 256 token.
Utilizzando la diffusione dello stato uniforme, il modello sostituisce il testo con rumore del vocabolario casuale e perfeziona iterativamente l'intero canvas in parallelo. Utilizza un modello Gemma 4 26B A4B ottimizzato per supportare le diverse attività di denoising e codifica. I framework avanzati come l'autocondizionamento e il campionamento a blocchi multi-canvas consentono al modello di correggere dinamicamente gli errori, gestire la generazione in formato lungo e ottenere una latenza molto bassa per un singolo utente.