Gemini API cung cấp các chế độ cài đặt an toàn mà bạn có thể điều chỉnh trong giai đoạn tạo mẫu để xác định xem ứng dụng của bạn có cần cấu hình an toàn hạn chế hơn hay ít hạn chế hơn hay không. Bạn có thể điều chỉnh các chế độ cài đặt này trên 4 danh mục bộ lọc để hạn chế hoặc cho phép một số loại nội dung.
Hướng dẫn này trình bày cách Gemini API xử lý chế độ cài đặt an toàn và tính năng lọc, cũng như cách bạn có thể thay đổi chế độ cài đặt an toàn cho ứng dụng của mình.
Bộ lọc an toàn
Các bộ lọc an toàn có thể điều chỉnh của Gemini API bao gồm những danh mục sau:
| Danh mục | Mô tả |
|---|---|
| Quấy rối | Bình luận tiêu cực hoặc gây hại nhắm đến danh tính và/hoặc các thuộc tính được bảo vệ. |
| Lời nói hận thù | Nội dung thô lỗ, khiếm nhã hoặc tục tĩu. |
| Nội dung khiêu dâm | Chứa nội dung đề cập đến hành vi tình dục hoặc nội dung khiêu dâm khác. |
| Nguy hiểm | Cổ xuý, tạo điều kiện hoặc khuyến khích hành động gây hại. |
Các danh mục này được xác định trong HarmCategory. Bạn có thể sử dụng các bộ lọc này để điều chỉnh những nội dung phù hợp với trường hợp sử dụng của mình. Ví dụ: nếu đang xây dựng đoạn hội thoại trong trò chơi điện tử, bạn có thể cho phép nhiều nội dung hơn được xếp hạng là Nguy hiểm do tính chất của trò chơi.
Ngoài các bộ lọc an toàn có thể điều chỉnh, Gemini API còn có các biện pháp bảo vệ tích hợp sẵn để ngăn chặn những tác hại cốt lõi, chẳng hạn như nội dung gây nguy hiểm cho sự an toàn của trẻ em. Những loại nội dung gây hại này luôn bị chặn và không thể điều chỉnh.
Mức độ lọc an toàn về nội dung
Gemini API phân loại mức độ xác suất của nội dung không an toàn là HIGH, MEDIUM, LOW hoặc NEGLIGIBLE.
Gemini API chặn nội dung dựa trên xác suất nội dung đó không an toàn chứ không phải mức độ nghiêm trọng. Bạn cần cân nhắc điều này vì một số nội dung có thể có xác suất thấp là không an toàn, mặc dù mức độ nghiêm trọng của tác hại vẫn có thể cao. Ví dụ: so sánh các câu sau:
- Người máy đã đấm tôi.
- Rô-bốt đã chém tôi.
Câu đầu tiên có thể có khả năng gây nguy hiểm cao hơn, nhưng bạn có thể coi câu thứ hai là có mức độ nghiêm trọng cao hơn về bạo lực. Do đó, bạn cần kiểm thử cẩn thận và cân nhắc mức độ chặn phù hợp để hỗ trợ các trường hợp sử dụng chính của bạn, đồng thời giảm thiểu tác hại cho người dùng cuối.
Lọc mức độ an toàn theo yêu cầu
Bạn có thể điều chỉnh chế độ cài đặt an toàn cho từng yêu cầu mà bạn gửi đến API. Khi bạn đưa ra yêu cầu, nội dung sẽ được phân tích và chỉ định một mức độ an toàn. Mức độ an toàn bao gồm danh mục và xác suất phân loại mức độ gây hại. Ví dụ: nếu nội dung bị chặn do danh mục quấy rối có xác suất cao, thì điểm an toàn được trả về sẽ có danh mục bằng HARASSMENT và xác suất gây hại được đặt thành HIGH.
Do tính an toàn vốn có của mô hình, các bộ lọc bổ sung sẽ ở trạng thái Tắt theo mặc định. Nếu chọn bật các chế độ này, bạn có thể định cấu hình hệ thống để chặn nội dung dựa trên xác suất nội dung đó không an toàn. Hành vi mặc định của mô hình bao gồm hầu hết các trường hợp sử dụng, vì vậy, bạn chỉ nên điều chỉnh các chế độ cài đặt này nếu cần tính nhất quán cho ứng dụng của mình.
Bảng sau đây mô tả các chế độ chặn mà bạn có thể điều chỉnh cho từng danh mục. Ví dụ: nếu bạn đặt chế độ chặn thành Chặn một số nội dung cho danh mục Lời nói hận thù, thì mọi nội dung có khả năng cao là lời nói hận thù đều sẽ bị chặn. Tuy nhiên, bạn có thể sử dụng mọi thứ có xác suất thấp hơn.
| Ngưỡng (Google AI Studio) | Ngưỡng (API) | Mô tả |
|---|---|---|
| Tắt | OFF |
Tắt bộ lọc an toàn |
| Không chặn thành phần nào | BLOCK_NONE |
Luôn hiển thị bất kể xác suất nội dung không an toàn |
| Chặn một số | BLOCK_ONLY_HIGH |
Chặn khi có khả năng cao là nội dung không an toàn |
| Chặn một số | BLOCK_MEDIUM_AND_ABOVE |
Chặn khi có khả năng trung bình hoặc cao về nội dung không an toàn |
| Chặn hầu hết | BLOCK_LOW_AND_ABOVE |
Chặn khi có xác suất thấp, trung bình hoặc cao về nội dung không an toàn |
| Không áp dụng | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
Ngưỡng không được chỉ định, chặn bằng ngưỡng mặc định |
Nếu bạn không đặt ngưỡng này, thì ngưỡng chặn mặc định sẽ là Tắt đối với các mô hình Gemini 2.5 và 3.
Bạn có thể đặt các chế độ cài đặt này cho từng yêu cầu mà bạn gửi đến dịch vụ tạo sinh.
Hãy xem tài liệu tham khảo về API HarmBlockThreshold để biết thông tin chi tiết.
Phản hồi về an toàn
generateContent trả về GenerateContentResponse bao gồm ý kiến phản hồi về độ an toàn.
Ý kiến phản hồi về câu lệnh được đưa vào promptFeedback. Nếu promptFeedback.blockReason được đặt, thì nội dung của lời nhắc đã bị chặn.
Ý kiến phản hồi về đề xuất phản hồi được đưa vào Candidate.finishReason và Candidate.safetyRatings. Nếu nội dung phản hồi bị chặn và finishReason là SAFETY, bạn có thể kiểm tra safetyRatings để biết thêm thông tin chi tiết. Nội dung bị chặn sẽ không được trả lại.
Điều chỉnh chế độ cài đặt an toàn
Phần này trình bày cách điều chỉnh chế độ cài đặt an toàn trong cả Google AI Studio và trong mã của bạn.
Google AI Studio
Bạn có thể điều chỉnh chế độ cài đặt an toàn trong Google AI Studio.
Nhấp vào Chế độ cài đặt an toàn trong phần Chế độ cài đặt nâng cao trong bảng điều khiển Chế độ cài đặt khi chạy để mở phương thức Chế độ cài đặt an toàn khi chạy. Trong cửa sổ phương thức, bạn có thể dùng thanh trượt để điều chỉnh mức lọc nội dung theo từng danh mục an toàn:
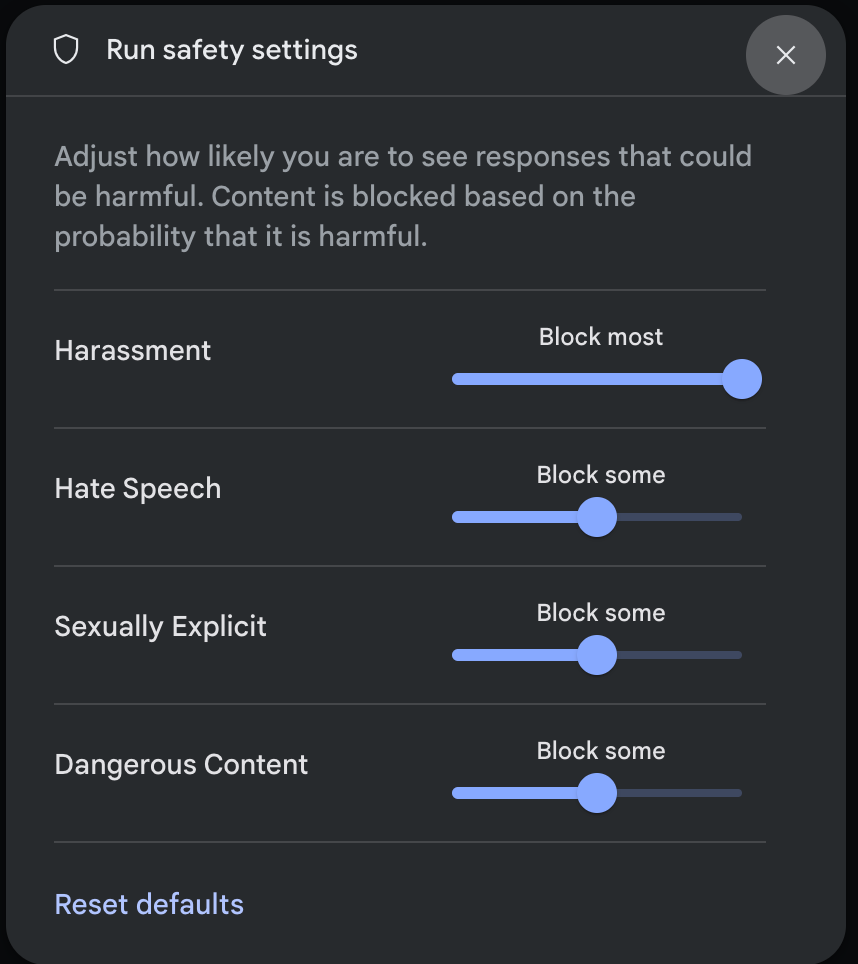
Khi bạn gửi yêu cầu (ví dụ: đặt câu hỏi cho mô hình), thông báo Nội dung bị chặn sẽ xuất hiện nếu nội dung trong yêu cầu bị chặn. Để xem thêm thông tin chi tiết, hãy giữ con trỏ trên văn bản Nội dung bị chặn để xem danh mục và xác suất phân loại nội dung gây hại.
Ví dụ về mã
Đoạn mã sau đây cho biết cách đặt chế độ cài đặt an toàn trong lệnh gọi GenerateContent. Thao tác này đặt ngưỡng cho danh mục lời nói hận thù (HARM_CATEGORY_HATE_SPEECH). Khi bạn đặt danh mục này thành BLOCK_LOW_AND_ABOVE, mọi nội dung có xác suất thấp hoặc cao hơn là lời nói hận thù đều sẽ bị chặn. Để tìm hiểu chế độ cài đặt ngưỡng, hãy xem phần Lọc nội dung không an toàn theo yêu cầu.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
Các bước tiếp theo
- Hãy xem Tài liệu tham khảo API để tìm hiểu thêm về toàn bộ API.
- Xem hướng dẫn an toàn để biết thông tin tổng quan về các yếu tố cần cân nhắc về sự an toàn khi phát triển bằng các LLM.
- Tìm hiểu thêm về cách đánh giá xác suất so với mức độ nghiêm trọng của nhóm Jigsaw
- Tìm hiểu thêm về các sản phẩm góp phần tạo nên các giải pháp an toàn như Perspective API. * Bạn có thể sử dụng các chế độ cài đặt an toàn này để tạo một trình phân loại nội dung độc hại. Hãy xem ví dụ về việc phân loại để bắt đầu.