Interfejs Gemini API udostępnia ustawienia bezpieczeństwa, które można dostosować na etapie prototypowania, aby określić, czy aplikacja wymaga bardziej czy mniej restrykcyjnej konfiguracji bezpieczeństwa. Możesz dostosować te ustawienia w 4 kategoriach filtrów, aby ograniczyć lub zezwolić na określone typy treści.
Ten przewodnik zawiera informacje o tym, jak interfejs Gemini API obsługuje ustawienia bezpieczeństwa i filtrowanie oraz jak możesz zmienić ustawienia bezpieczeństwa w swojej aplikacji.
Filtry bezpieczeństwa
Dostosowywane filtry bezpieczeństwa Gemini API obejmują te kategorie:
| Kategoria | Opis |
|---|---|
| Nękanie | Negatywne lub szkodliwe komentarze dotyczące tożsamości innej osoby lub cech chronionych. |
| Szerzenie nienawiści | Treści, które są nieuprzejme, obraźliwe lub wulgarne. |
| Treści o charakterze jednoznacznie seksualnym | Treści zawierające odniesienia do aktów seksualnych lub innych lubieżnych treści. |
| Treści niebezpieczne | promują, wspierają lub ułatwiają podejmowanie szkodliwych działań; |
Kategorie te są zdefiniowane w HarmCategory. Możesz użyć tych filtrów, aby dostosować wyniki do swoich potrzeb. Jeśli na przykład tworzysz dialogi do gry wideo, możesz zezwolić na więcej treści ocenionych jako niebezpieczne, ponieważ taki jest charakter gry.
Oprócz dostosowywanych filtrów bezpieczeństwa interfejs Gemini API ma wbudowane zabezpieczenia przed podstawowymi szkodami, takimi jak treści zagrażające bezpieczeństwu dzieci. Te rodzaje szkodliwych treści są zawsze blokowane i nie można ich dostosować.
Poziom filtrowania pod kątem bezpieczeństwa treści
Interfejs Gemini API kategoryzuje poziom prawdopodobieństwa, że treść jest niebezpieczna, jako HIGH, MEDIUM, LOW lub NEGLIGIBLE.
Interfejs Gemini API blokuje treści na podstawie prawdopodobieństwa, że są one niebezpieczne, a nie na podstawie ich szkodliwości. Warto o tym pamiętać, ponieważ niektóre treści mogą mieć niskie prawdopodobieństwo bycia niebezpiecznymi, mimo że stopień szkodliwości może być wysoki. Na przykład porównując zdania:
- Robot mnie uderzył.
- Robot mnie pociął.
Pierwsze zdanie może mieć większe prawdopodobieństwo bycia niebezpiecznym, ale drugie zdanie może być bardziej poważne pod względem przemocy. Dlatego ważne jest, aby dokładnie przetestować i rozważyć, jaki poziom blokowania jest odpowiedni do obsługi kluczowych przypadków użycia przy jednoczesnym zminimalizowaniu szkód dla użytkowników.
Filtrowanie treści pod kątem bezpieczeństwa w przypadku każdego żądania
Ustawienia bezpieczeństwa możesz dostosowywać w przypadku każdego żądania wysyłanego do interfejsu API. Gdy wyślesz prośbę, treść zostanie przeanalizowana i otrzyma ocenę bezpieczeństwa. Ocena bezpieczeństwa obejmuje kategorię i prawdopodobieństwo klasyfikacji szkody. Jeśli na przykład treść została zablokowana, ponieważ system stwierdził wysokie prawdopodobieństwo wystąpienia treści nękających, zwrócona ocena bezpieczeństwa będzie miała kategorię równą HARASSMENT i prawdopodobieństwo szkody ustawione na HIGH.
Ze względu na wbudowane zabezpieczenia modelu dodatkowe filtry są domyślnie wyłączone. Jeśli zdecydujesz się je włączyć, możesz skonfigurować system tak, aby blokował treści na podstawie prawdopodobieństwa, że są one niebezpieczne. Domyślne działanie modelu obejmuje większość przypadków użycia, więc te ustawienia należy dostosowywać tylko wtedy, gdy jest to na dłuższą metę niezbędne w danej aplikacji.
W tabeli poniżej opisujemy ustawienia blokowania, które możesz dostosować w przypadku każdej kategorii. Jeśli na przykład w przypadku kategorii Wypowiedzi szerzące nienawiść ustawisz blokowanie na Blokuj niewiele, zablokowane zostaną wszystkie treści, które z dużym prawdopodobieństwem są wypowiedziami szerzącymi nienawiść. Dozwolone są jednak wszystkie treści o niższym prawdopodobieństwie.
| Próg (Google AI Studio) | Próg (interfejs API) | Opis |
|---|---|---|
| Wył. | OFF |
Wyłącz filtr bezpieczeństwa |
| Nie blokuj niczego | BLOCK_NONE |
Zawsze wyświetlaj treści niezależnie od prawdopodobieństwa wystąpienia treści niebezpiecznych |
| Blokuj niektóre | BLOCK_ONLY_HIGH |
Blokuj, gdy prawdopodobieństwo wystąpienia treści niebezpiecznych jest wysokie |
| Blokuj część | BLOCK_MEDIUM_AND_ABOVE |
Blokuj, gdy prawdopodobieństwo wystąpienia treści niebezpiecznych jest średnie lub wysokie |
| Blokuj większość | BLOCK_LOW_AND_ABOVE |
Blokuj, gdy prawdopodobieństwo wystąpienia treści niebezpiecznych jest niskie, średnie lub wysokie |
| Nie dotyczy | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
Próg nie został określony, blokuj przy użyciu domyślnego progu |
Jeśli próg nie jest ustawiony, domyślny próg blokowania jest wyłączony w przypadku modeli Gemini 2.5 i 3.
Możesz określić te ustawienia dla każdego żądania wysyłanego do usługi generatywnej.
Szczegółowe informacje znajdziesz w dokumentacji interfejsu HarmBlockThreshold API.
Opinie dotyczące bezpieczeństwa
generateContent
zwraca
GenerateContentResponse, który
zawiera informacje o bezpieczeństwie.
Informacje o prompcie są uwzględnione w promptFeedback. Jeśli ustawiona jest wartość
promptFeedback.blockReason, oznacza to, że treść promptu została zablokowana.
Opinie o proponowanych odpowiedziach są uwzględniane w przypadku Candidate.finishReason i Candidate.safetyRatings. Jeśli treść odpowiedzi została zablokowana, a finishReason było SAFETY, możesz sprawdzić safetyRatings, aby dowiedzieć się więcej. Zablokowane treści nie są zwracane.
Dostosowywanie ustawień bezpieczeństwa
Z tej sekcji dowiesz się, jak dostosować ustawienia bezpieczeństwa w Google AI Studio i w kodzie.
Google AI Studio
Ustawienia bezpieczeństwa możesz dostosować w Google AI Studio.
W panelu Ustawienia uruchamiania w sekcji Ustawienia zaawansowane kliknij Ustawienia bezpieczeństwa, aby otworzyć okno modalne Ustawienia bezpieczeństwa uruchamiania. W oknie możesz użyć suwaków, aby dostosować poziom filtrowania treści w poszczególnych kategoriach bezpieczeństwa:
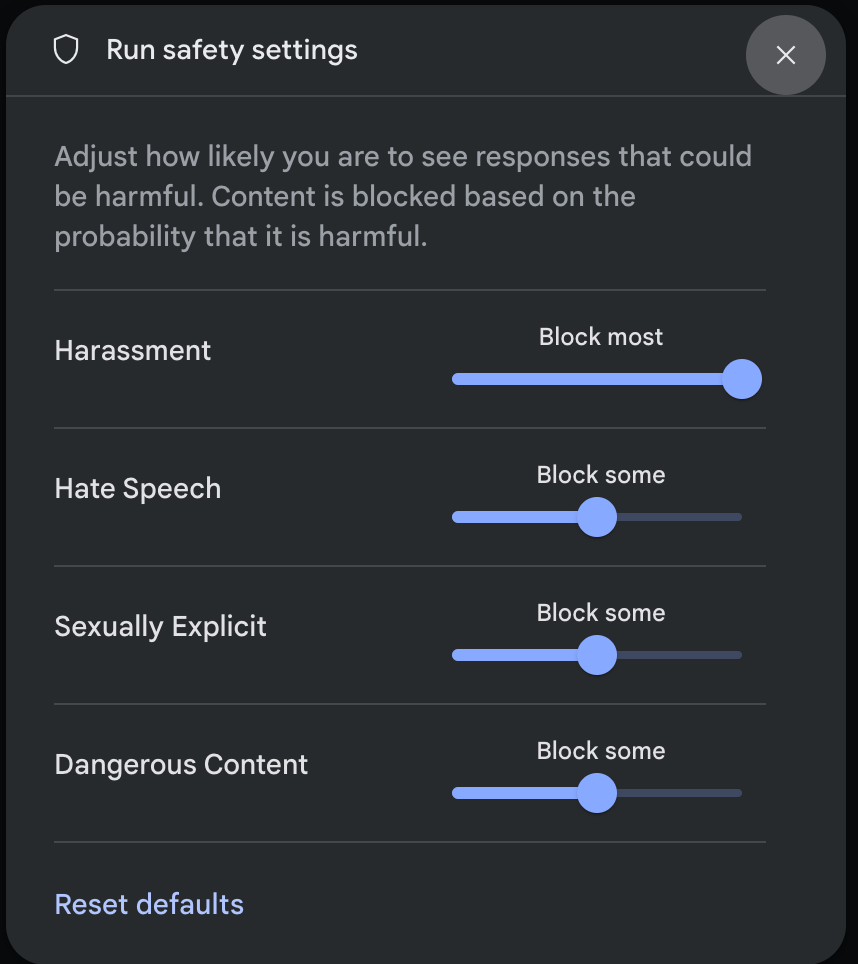
Gdy wyślesz żądanie (np. zadając modelowi pytanie), pojawi się komunikat Treści zablokowane, jeśli treści żądania są zablokowane. Aby zobaczyć więcej szczegółów, najedź wskaźnikiem na tekst Treści zablokowane, aby wyświetlić kategorię i prawdopodobieństwo klasyfikacji szkodliwości.
Przykłady kodu
Poniższy fragment kodu pokazuje, jak ustawić ustawienia bezpieczeństwa w wywołaniu GenerateContent. Ustawia to próg dla kategorii szerzenia nienawiści (HARM_CATEGORY_HATE_SPEECH). Ustawienie tej kategorii na BLOCK_LOW_AND_ABOVE blokuje wszystkie treści, które z niskim lub wyższym prawdopodobieństwem zawierają szerzenie nienawiści. Więcej informacji o ustawieniach progowych znajdziesz w sekcji Filtrowanie treści pod kątem bezpieczeństwa
w przypadku każdego żądania.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
Dalsze kroki
- Więcej informacji o pełnej wersji interfejsu API znajdziesz w dokumentacji API.
- Zapoznaj się z wytycznymi dotyczącymi bezpieczeństwa, aby poznać ogólne kwestie związane z bezpieczeństwem podczas tworzenia aplikacji z użyciem dużych modeli językowych.
- Więcej informacji o ocenianiu prawdopodobieństwa i poziomu ważności znajdziesz na blogu zespołu Jigsaw.
- Dowiedz się więcej o usługach, które przyczyniają się do tworzenia rozwiązań w zakresie bezpieczeństwa, takich jak Perspective API. * Za pomocą tych ustawień bezpieczeństwa możesz utworzyć klasyfikator toksyczności. Aby rozpocząć, zapoznaj się z przykładem klasyfikacji.