ממשק Gemini API מספק הגדרות בטיחות שאפשר לשנות בשלב יצירת אב טיפוס, כדי לקבוע אם האפליקציה דורשת הגדרת בטיחות מגבילה יותר או פחות. אתם יכולים לשנות את ההגדרות האלה בארבע קטגוריות של מסננים כדי להגביל סוגים מסוימים של תוכן או לאפשר אותם.
במדריך הזה מוסבר איך Gemini API מטפל בהגדרות בטיחות ובסינון, ואיך אפשר לשנות את הגדרות הבטיחות של האפליקציה.
מסנני בטיחות
מסנני הבטיחות המתכווננים של Gemini API מכסים את הקטגוריות הבאות:
| קטגוריה | תיאור |
|---|---|
| הטרדה | תגובות שליליות או פוגעניות שמכוונות לזהות ו/או למאפיינים מוגנים. |
| דברי שטנה | תוכן גס, לא מכבד או חילול קודש. |
| תוכן מיני בוטה | מכיל התייחסויות למעשים מיניים או לתוכן מגונה אחר. |
| תוכן מסוכן | מקדם גרימת נזק, מעודד גרימת נזק או עוזר לבצע פעולות מזיקות. |
הקטגוריות האלה מוגדרות בHarmCategory. אפשר להשתמש במסננים האלה כדי להתאים את התוצאות למקרה השימוש שלכם. לדוגמה, אם אתם יוצרים דיאלוג למשחק וידאו, יכול להיות שתחליטו לאפשר יותר תוכן שסווג כמסוכן בגלל אופי המשחק.
בנוסף למסנני הבטיחות שניתנים להתאמה, ל-Gemini API יש אמצעי הגנה מובנים מפני נזקים מהותיים, כמו תוכן שמסכן את בטיחות הילדים. סוגי הנזק האלה תמיד נחסמים ואי אפשר לשנות את זה.
רמת הסינון של בטיחות התוכן
Gemini API מסווג את רמת ההסתברות לכך שהתוכן לא בטוח כ-HIGH, MEDIUM, LOW או NEGLIGIBLE.
Gemini API חוסם תוכן על סמך הסבירות שהתוכן לא בטוח, ולא על סמך חומרת הבעיה. חשוב לקחת את זה בחשבון כי יש תכנים שהסיכוי שהם לא בטוחים הוא נמוך, אבל חומרת הנזק שעלולה להיגרם מהם עדיין גבוהה. לדוגמה, אם משווים בין המשפטים:
- הרובוט נתן לי אגרוף.
- הרובוט חתך אותי.
המשפט הראשון עלול להוביל לסבירות גבוהה יותר של תוצאה לא בטוחה, אבל יכול להיות שהמשפט השני ייחשב לחמור יותר מבחינת אלימות. לכן, חשוב לבדוק בקפידה ולשקול מהי רמת החסימה המתאימה שנדרשת כדי לתמוך בתרחישי השימוש העיקריים שלכם, תוך מזעור הפגיעה במשתמשי הקצה.
סינון בטיחות לכל בקשה
אתם יכולים לשנות את הגדרות הבטיחות לכל בקשה שאתם שולחים ל-API. כששולחים בקשה, התוכן נותח ומוקצה לו סיווג בטיחות. דירוג הבטיחות כולל את הקטגוריה ואת הסיווג של הסבירות לפגיעה. לדוגמה, אם התוכן נחסם כי הסבירות שהוא משתייך לקטגוריית ההטרדה גבוהה, דירוג הבטיחות שיוחזר יהיה עם קטגוריה ששווה ל-HARASSMENT וסבירות לפגיעה שמוגדרת כ-HIGH.
בגלל הבטיחות המובנית של המודל, מסננים נוספים מושבתים כברירת מחדל. אם תבחרו להפעיל אותן, תוכלו להגדיר את המערכת לחסימת תוכן על סמך הסבירות שהוא לא בטוח. התנהגות ברירת המחדל של המודל מתאימה לרוב תרחישי השימוש, ולכן כדאי לשנות את ההגדרות האלה רק אם נדרשת עקביות באפליקציה.
בטבלה הבאה מתוארות הגדרות החסימה שאפשר לשנות לכל קטגוריה. לדוגמה, אם מגדירים את הגדרת החסימה לחסימה של חלק מהתוכן בקטגוריה דברי שטנה, כל מה שיש לו סיכוי גבוה להיות תוכן של דברי שטנה ייחסם. אבל מותר להשתמש בכל ערך עם הסתברות נמוכה יותר.
| סף (Google AI Studio) | סף (API) | תיאור |
|---|---|---|
| מושבת | OFF |
השבתת מסנן הבטיחות |
| לא לחסום אף אחד | BLOCK_NONE |
הצגה תמיד, ללא קשר להסתברות של תוכן לא בטוח |
| חסימה של כמה אנשים | BLOCK_ONLY_HIGH |
חסימה כשיש סבירות גבוהה לתוכן לא בטוח |
| חסימת חלק מהמשתמשים | BLOCK_MEDIUM_AND_ABOVE |
חסימה כשיש הסתברות בינונית או גבוהה לתוכן לא בטוח |
| חסימה של רוב האנשים | BLOCK_LOW_AND_ABOVE |
חסימה כשההסתברות לתוכן לא בטוח נמוכה, בינונית או גבוהה |
| לא רלוונטי | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
לא צוין סף, חסימה באמצעות סף ברירת המחדל |
אם לא מגדירים את הסף, ברירת המחדל של סף החסימה היא מושבת למודלים של Gemini 2.5 ו-3.
אפשר להגדיר את ההגדרות האלה לכל בקשה ששולחים לשירות הגנרטיבי.
פרטים נוספים זמינים במאמר בנושא HarmBlockThreshold API.
משוב בנושא בטיחות
generateContent
מחזירה את
GenerateContentResponse שכוללת משוב בנושא בטיחות.
המשוב על ההנחיות כלול ב-promptFeedback. אם הערך של promptFeedback.blockReason מוגדר, סימן שהתוכן של ההנחיה נחסם.
המשוב על המועמדים לתשובה נכלל ב-Candidate.finishReason וב-Candidate.safetyRatings. אם תוכן התשובה נחסם והערך של finishReason היה SAFETY, אפשר לבדוק את safetyRatings כדי לקבל פרטים נוספים. התוכן שנחסם לא יוחזר.
שינוי הגדרות הבטיחות
בקטע הזה מוסבר איך לשנות את הגדרות הבטיחות ב-Google AI Studio ובקוד.
Google AI Studio
אתם יכולים לשנות את הגדרות הבטיחות ב-Google AI Studio.
לוחצים על הגדרות בטיחות בקטע הגדרות מתקדמות בחלונית הגדרות ההרצה כדי לפתוח את תיבת הדו-שיח הגדרות בטיחות של ההרצה. בחלון הקופץ, אפשר להשתמש בפסי ההזזה כדי לשנות את רמת סינון התוכן לפי קטגוריית בטיחות:
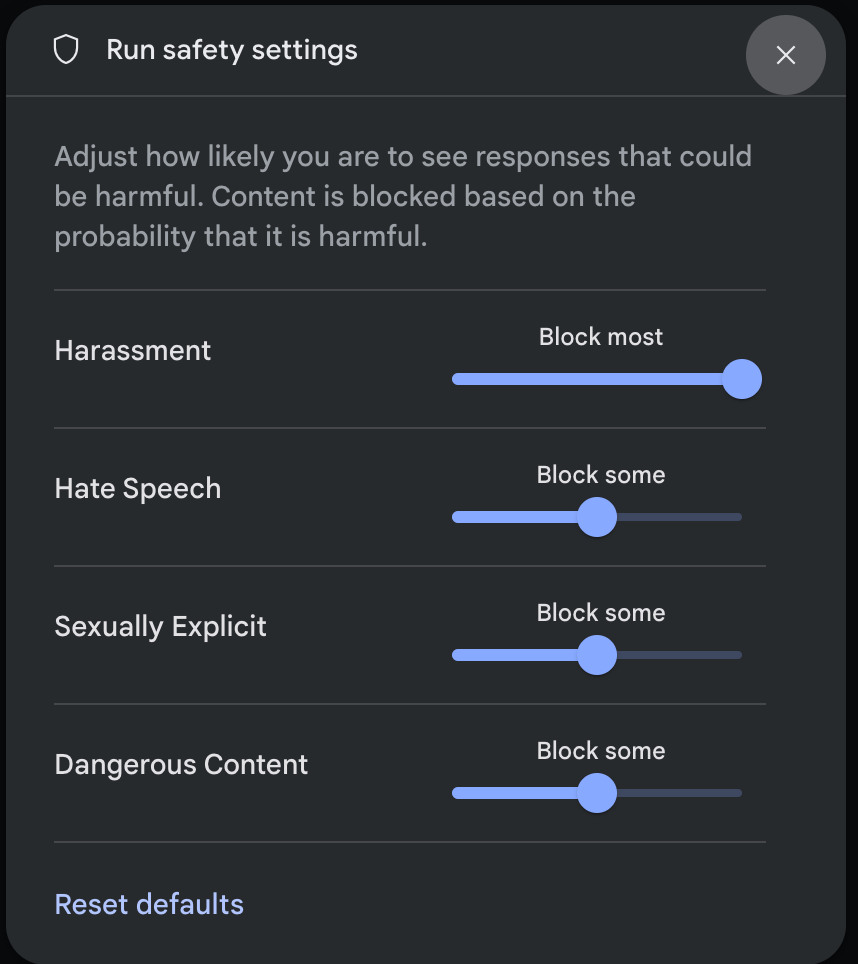
כששולחים בקשה (למשל, שואלים את המודל שאלה), מופיעה ההודעה התוכן חסום אם התוכן של הבקשה חסום. כדי לראות פרטים נוספים, מעבירים את מצביע העכבר מעל הטקסט התוכן נחסם כדי לראות את הקטגוריה ואת הסבירות לסיווג הנזק.
דוגמאות לקוד
בקטע הקוד הבא מוצג איך מגדירים הגדרות בטיחות בקריאה ל-GenerateContent. הפעולה הזו מגדירה את ערך הסף לקטגוריה 'דברי שטנה' (HARM_CATEGORY_HATE_SPEECH). אם מגדירים את הקטגוריה הזו לערך
BLOCK_LOW_AND_ABOVE, כל תוכן שיש לו סבירות נמוכה או גבוהה יותר להיות דברי שטנה ייחסם. כדי להבין את הגדרות הסף, אפשר לעיין במאמר סינון בטיחותי לכל בקשה.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
השלבים הבאים
- מידע נוסף על ה-API המלא מופיע בהפניית ה-API.
- כדאי לעיין בהנחיות הבטיחות כדי לקבל סקירה כללית של שיקולי הבטיחות כשמפתחים באמצעות מודלים של שפה גדולה (LLM).
- מידע נוסף על הערכת ההסתברות לעומת חומרת הבעיה זמין בצוות Jigsaw
- מידע נוסף על המוצרים שמשמשים לפתרונות בטיחות כמו Perspective API. * אפשר להשתמש בהגדרות הבטיחות האלה כדי ליצור מסווג רעילות. כדי להתחיל, אפשר לעיין בדוגמה של סיווג.