Gemini API 提供了安全设置,您可以在原型设计阶段调整这些设置,以确定您的应用需要更严格还是更宽松的安全配置。您可以在四个过滤器类别中调整这些设置,以限制或允许某些类型的内容。
本指南介绍了 Gemini API 如何处理安全设置和过滤,以及如何更改应用的安全设置。
安全过滤器
Gemini API 的可调整安全过滤条件涵盖以下类别:
| 类别 | 说明 |
|---|---|
| 骚扰 | 针对身份和/或受保护属性的负面或有害评论。 |
| 仇恨言论 | 粗鲁、无礼或亵渎性的内容。 |
| 露骨色情内容 | 包含对性行为或其他淫秽内容的引用。 |
| 危险内容 | 宣扬、助长或鼓励有害行为。 |
这些类别在 HarmCategory 中定义。您可以使用这些过滤器,针对您的应用场景进行适当的调整。例如,如果您要制作视频游戏对话,可能会认为鉴于游戏的性质,较多地使用评级为危险的内容是可以接受的。
除了可调整的安全过滤条件外,Gemini API 还针对危害儿童安全的内容等核心危害提供内置防护措施。这些类型的有害内容始终会被屏蔽,无法调整。
内容安全过滤等级
Gemini API 将内容不安全的概率级别分为 HIGH、MEDIUM、LOW 或 NEGLIGIBLE。
Gemini API 会根据内容不安全的概率(而非严重程度)来屏蔽内容。考虑这一点很重要,因为某些内容不安全的可能性很小,即使危害的严重程度可能仍然很高。例如,比较以下句子:
- 机器人打了我一拳。
- 机器人把我砍伤了。
第 1 句可能导致不安全的可能性更高,但您可能认为第 2 句在暴力方面的严重性更高。考虑到这一点,您必须仔细测试并考虑需要哪些级别的屏蔽来支持您的关键应用场景,同时最大限度地减少对最终用户的影响。
按请求进行安全过滤
您可以针对向 API 发出的每个请求调整安全设置。当您发出请求时,系统会对内容进行分析并进行安全评级。安全评级会说明内容的类别以及内容属于危害分类的概率。例如,如果内容因“骚扰内容”类别下不安全的概率较高而被屏蔽,则返回的安全评级将包含类别 HARASSMENT,并将危害概率设置为 HIGH。
由于模型本身具有安全性,因此默认情况下,其他过滤条件处于关闭状态。 如果您选择启用这些功能,则可以配置系统根据内容的不安全概率来屏蔽内容。默认模型行为可满足大多数应用场景的需求,因此,只有当您的应用确实需要时才应调整这些设置。
下表介绍了您可以针对每种类别调整的屏蔽设置。例如,如果您将仇恨言论类别的屏蔽设置设为屏蔽少部分,则系统会屏蔽包含仇恨言论内容概率较高的所有部分。但允许任何包含危险内容概率较低的部分。
| 阈值 (Google AI Studio) | 阈值 (API) | 说明 |
|---|---|---|
| 关闭 | OFF |
关闭安全过滤条件 |
| 全部不屏蔽 | BLOCK_NONE |
无论不安全内容的可能性如何,一律显示 |
| 屏蔽少部分 | BLOCK_ONLY_HIGH |
在出现不安全内容的概率较高时屏蔽 |
| 屏蔽一部分 | BLOCK_MEDIUM_AND_ABOVE |
当不安全内容的可能性为中等或较高时屏蔽 |
| 屏蔽大部分 | BLOCK_LOW_AND_ABOVE |
当不安全内容的可能性为低、中或高时屏蔽 |
| 不适用 | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
阈值未指定,使用默认阈值屏蔽 |
如果未设置阈值,则 Gemini 2.5 和 3 模型的默认屏蔽阈值为关闭。
您可以针对向生成式服务发出的每个请求进行设置。
如需了解详情,请参阅 HarmBlockThreshold API 参考文档。
安全反馈
generateContent 返回包含安全反馈的 GenerateContentResponse。
提示反馈包含在 promptFeedback 中。如果设置了 promptFeedback.blockReason,则表示相应提示的内容已被屏蔽。
响应候选反馈包含在 Candidate.finishReason 和 Candidate.safetyRatings 中。如果响应内容被屏蔽,且 finishReason 为 SAFETY,您可以检查 safetyRatings 以了解更多详情。系统不会返回被屏蔽的内容。
调整安全设置
本部分介绍了如何在 Google AI Studio 和代码中调整安全设置。
Google AI Studio
您可以在 Google AI Studio 中调整安全设置。
在运行设置面板中,点击高级设置下的安全设置,打开运行安全设置模态。在模态框中,您可以使用滑块按安全类别调整内容过滤级别:
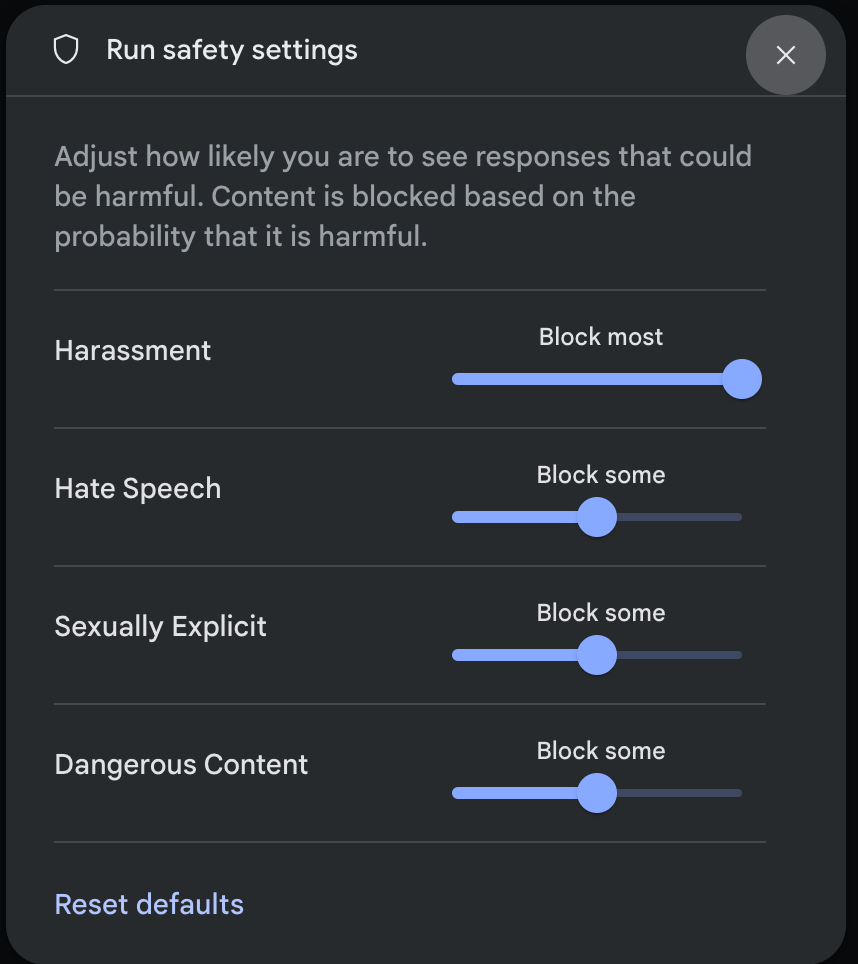
当您发送请求(例如,向模型提问)时,如果请求的内容被屏蔽,系统会显示 内容被屏蔽消息。如需查看更多详细信息,请将指针悬停在内容已屏蔽文本上,以查看类别和危害分类的概率。
代码示例
以下代码段展示了如何在 GenerateContent 调用中设置安全设置。这会设置“仇恨言论”(HARM_CATEGORY_HATE_SPEECH) 类别的阈值。将此类别设置为 BLOCK_LOW_AND_ABOVE 会屏蔽包含仇恨言论概率较低或更高的所有内容。如需了解阈值设置,请参阅按请求进行安全过滤。
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
后续步骤
- 如需详细了解完整的 API,请参阅 API 参考文档。
- 如需大致了解在使用 LLM 进行开发时应考虑的安全事项,请查看安全指南。
- 详细了解 Jigsaw 团队如何评估概率与严重程度
- 详细了解有助于打造安全解决方案的产品,例如 Perspective API。 * 您可以使用这些安全设置来创建毒性分类器。如需开始使用,请参阅分类示例。