
این راهنما دستورالعملهایی برای تبدیل مدلهای Gemma با فرمت Hugging Face Safetensors ( .safetensors ) به فرمت فایل MediaPipe Task ( .task ) ارائه میدهد. این تبدیل برای استقرار مدلهای Gemma از پیش آموزشدیده یا تنظیمشده برای استنتاج روی دستگاه در اندروید و iOS با استفاده از MediaPipe LLM Inference API و LiteRT runtime ضروری است.
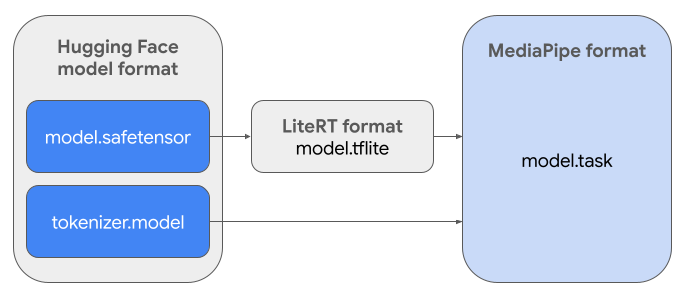
برای ایجاد Task Bundle مورد نیاز ( .task )، از LiteRT Torch استفاده خواهید کرد. این ابزار مدلهای PyTorch را به مدلهای LiteRT چند امضایی ( .tflite ) تبدیل میکند که با API استنتاج MediaPipe LLM سازگار هستند و برای اجرا روی CPU backend در برنامههای تلفن همراه مناسب میباشند.
فایل .task نهایی یک بستهی مستقل مورد نیاز MediaPipe است که مدل LiteRT، مدل توکنساز و فرادادههای ضروری را در خود جای میدهد. این بسته ضروری است زیرا توکنساز (که اعلانهای متنی را به جاسازیهای توکن برای مدل تبدیل میکند) باید همراه با مدل LiteRT بستهبندی شود تا استنتاج سرتاسری امکانپذیر شود.
در اینجا تجزیه و تحلیل گام به گام فرآیند آمده است:
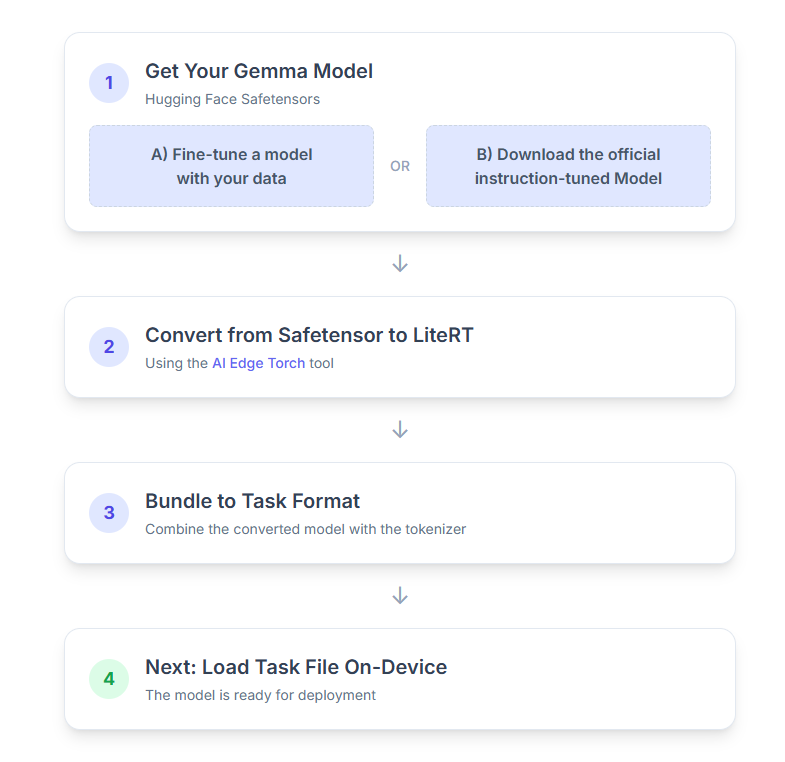
۱. مدل جما (Gemma) خود را تهیه کنید
برای شروع دو گزینه دارید.
گزینه الف. استفاده از یک مدل موجودِ تنظیمشدهی دقیق
اگر یک مدل Gemma تنظیمشده آماده دارید، کافیست به مرحله بعدی بروید.
گزینه ب. دانلود مدل رسمی تنظیمشده با دستورالعمل
اگر به یک مدل نیاز دارید، میتوانید یک Gemma با تنظیمات دستورالعمل را از Hugging Face Hub دانلود کنید.
ابزارهای لازم را تنظیم کنید:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
مدل را دانلود کنید:
مدلهای موجود در Hugging Face Hub با یک شناسه مدل، معمولاً در قالب <organization_or_username>/<model_name> ، شناسایی میشوند. به عنوان مثال، برای دانلود مدل رسمی تنظیمشده با دستورالعمل Google Gemma 3 270M، از دستور زیر استفاده کنید:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
۲. مدل را به LiteRT تبدیل و کوانتیزه کنید
یک محیط مجازی پایتون راهاندازی کنید و آخرین نسخه پایدار بسته LiteRT Torch را نصب کنید:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
از اسکریپت زیر برای تبدیل Safetensor به مدل LiteRT استفاده کنید.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
توجه داشته باشید که این فرآیند زمانبر است و به سرعت پردازش رایانه شما بستگی دارد. برای مرجع، در یک پردازنده ۸ هستهای ۲۰۲۵، یک مدل ۲۷۰M بیش از ۵ تا ۱۰ دقیقه طول میکشد، در حالی که یک مدل ۱B میتواند تقریباً ۱۰ تا ۳۰ دقیقه طول بکشد.
خروجی نهایی، یک مدل LiteRT، در OUTPUT_DIR_PATH مشخص شده شما ذخیره خواهد شد.
مقادیر زیر را بر اساس محدودیتهای حافظه و عملکرد دستگاه هدف خود تنظیم کنید.
-
kv_cache_max_len: کل اندازه اختصاص داده شده به حافظه کاری مدل (حافظه نهان KV) را تعریف میکند. این ظرفیت یک محدودیت قطعی است و باید برای ذخیره مجموع توکنهای اعلان (پیشپر کردن) و تمام توکنهای تولید شده بعدی (رمزگشایی) کافی باشد. -
prefill_seq_len: تعداد توکنهای ورودی برای قطعهبندی پیش از پر کردن را مشخص میکند. هنگام پردازش ورودی با استفاده از قطعهبندی پیش از پر کردن، کل توالی (مثلاً ۵۰،۰۰۰ توکن) به طور همزمان محاسبه نمیشود؛ در عوض، به بخشهای قابل مدیریت (مثلاً تکههایی از ۲۰۴۸ توکن) تقسیم میشود که به صورت متوالی در حافظه پنهان بارگذاری میشوند تا از خطای کمبود حافظه جلوگیری شود. -
quantize: رشتهای برای طرحهای کوانتیزاسیون انتخاب شده. در زیر لیست دستور العملهای کوانتیزاسیون موجود برای Gemma 3 آمده است.-
none: بدون کوانتیزاسیون -
fp16: وزنهای FP16، فعالسازیهای FP32 و محاسبات ممیز شناور برای همه عملیاتها -
dynamic_int8: فعالسازیهای FP32، وزنهای INT8 و محاسبه اعداد صحیح -
weight_only_int8: فعالسازیهای FP32، وزنهای INT8 و محاسبات ممیز شناور
-
۳. ایجاد یک بسته وظیفه از LiteRT و توکنایزر
یک محیط مجازی پایتون راهاندازی کنید و بسته پایتون mediapipe را نصب کنید:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
از کتابخانه genai.bundler برای بستهبندی مدل استفاده کنید:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
تابع bundler.create_bundle یک فایل .task ایجاد میکند که شامل تمام اطلاعات لازم برای اجرای مدل است.
۴. استنتاج با Mediapipe در اندروید
وظیفه را با گزینههای پیکربندی اولیه راهاندازی کنید:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
برای تولید یک پاسخ متنی از متد generateResponse() استفاده کنید.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
برای پخش جریانی پاسخ، از متد generateResponseAsync() استفاده کنید.
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
برای اطلاعات بیشتر به راهنمای استنتاج LLM برای اندروید مراجعه کنید.
مراحل بعدی
با مدلهای Gemma بیشتر بسازید و کاوش کنید: