
| | | | |  مشاهده منبع در GitHub مشاهده منبع در GitHub |
این راهنما به شما آموزش میدهد که چگونه Gemma را روی مجموعه دادههای NPC بازی موبایل با استفاده از Hugging Face Transformers و TRL تنظیم کنید. یاد خواهید گرفت:
- راه اندازی محیط توسعه
- مجموعه داده تنظیم دقیق را آماده کنید
- مدل کامل Gemma را با استفاده از TRL و SFTTrainer تنظیم کنید
- تست استنتاج مدل و بررسی ویبر
راه اندازی محیط توسعه
اولین قدم نصب کتابخانههای Hugging Face، از جمله TRL، و مجموعه دادهها برای تنظیم دقیق مدل باز، از جمله تکنیکهای مختلف RLHF و تراز است.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
توجه: اگر از یک پردازنده گرافیکی با معماری Ampere (مانند NVIDIA L4) یا جدیدتر استفاده می کنید، می توانید از توجه Flash استفاده کنید. توجه فلش روشی است که به طور قابل توجهی سرعت محاسبات را افزایش می دهد و استفاده از حافظه را از درجه دوم به خطی در طول دنباله کاهش می دهد و منجر به تسریع تمرین تا 3 برابر می شود. در FlashAttention بیشتر بیاموزید.
قبل از شروع آموزش، باید مطمئن شوید که شرایط استفاده از Gemma را پذیرفته اید. میتوانید با کلیک بر روی دکمه Agree and Access Repository در صفحه مدل در آدرس: http://huggingface.co/google/gemma-3-270m-it مجوز را در Hugging Face بپذیرید.
بعد از اینکه مجوز را پذیرفتید، برای دسترسی به مدل به یک نشانه معتبر Hugging Face نیاز دارید. اگر در داخل یک Google Colab در حال اجرا هستید، میتوانید با استفاده از رمزهای Colab به طور ایمن از نشانه Hugging Face خود استفاده کنید، در غیر این صورت میتوانید توکن را مستقیماً در روش login تنظیم کنید. مطمئن شوید که توکن شما نیز دسترسی نوشتن دارد، زیرا در طول آموزش مدل خود را به هاب فشار می دهید.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
می توانید نتایج را در ماشین مجازی محلی Colab نگه دارید. با این حال، ما به شدت توصیه می کنیم نتایج میانی خود را در Google Drive خود ذخیره کنید. این تضمین می کند که نتایج آموزشی شما ایمن است و به شما امکان می دهد به راحتی بهترین مدل را مقایسه و انتخاب کنید.
from google.colab import drive
drive.mount('/content/drive')
مدل پایه را برای تنظیم دقیق انتخاب کنید، دایرکتوری ایست بازرسی و نرخ یادگیری را تنظیم کنید.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
مجموعه داده تنظیم دقیق را ایجاد و آماده کنید
مجموعه داده bebechien/MobileGameNPC نمونه کوچکی از مکالمات بین یک بازیکن و دو NPC بیگانه (مریخی و ونوسی) را ارائه می دهد که هر کدام دارای یک سبک صحبت منحصر به فرد هستند. به عنوان مثال، NPC مریخی با لهجه ای صحبت می کند که صداهای 's' را با 'z' جایگزین می کند، از 'da' برای 'the'، 'diz' برای 'this' استفاده می کند، و شامل کلیک های گاه به گاه مانند *k'tak* می شود.
این مجموعه داده یک اصل کلیدی را برای تنظیم دقیق نشان می دهد: اندازه داده مورد نیاز به خروجی مورد نظر بستگی دارد.
- برای آموزش مدل یک تغییر سبک از زبانی که قبلاً میداند، مانند لهجه مریخی، یک مجموعه داده کوچک با 10 تا 20 مثال میتواند کافی باشد.
- با این حال، برای آموزش مدل یک زبان بیگانه کاملاً جدید یا ترکیبی، یک مجموعه داده بسیار بزرگتر مورد نیاز است.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
Gemma را با استفاده از TRL و SFTTrainer تنظیم کنید
اکنون آماده تنظیم دقیق مدل خود هستید. Hugging Face TRL SFTTrainer نظارت بر تنظیم دقیق LLM های باز را آسان می کند. SFTTrainer یک زیر کلاس از Trainer از کتابخانه transformers است و از همه ویژگی های مشابه پشتیبانی می کند.
کد زیر مدل Gemma و توکنایزر را از Hugging Face بارگیری می کند.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
قبل از تنظیم دقیق
خروجی زیر نشان می دهد که قابلیت های خارج از جعبه ممکن است برای این مورد به اندازه کافی خوب نباشد.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
مثال بالا عملکرد اصلی مدل در تولید گفتگوی درون بازی را بررسی می کند، مثال بعدی برای آزمایش سازگاری کاراکتر طراحی شده است. ما مدل را با یک اعلان خارج از موضوع به چالش می کشیم. به عنوان مثال، Sorry, you are a game NPC. ، که خارج از پایگاه دانش شخصیت قرار می گیرد.
هدف این است که ببینیم آیا مدل می تواند به جای پاسخ دادن به سؤال خارج از زمینه، در شخصیت باقی بماند یا خیر. این به عنوان مبنایی برای ارزیابی تأثیرگذاری فرآیند تنظیم دقیق به شخصیت مورد نظر خواهد بود.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
و در حالی که میتوانیم از مهندسی سریع برای هدایت لحن آن استفاده کنیم، نتایج میتوانند غیرقابل پیشبینی باشند و ممکن است همیشه با شخصیت مورد نظر ما هماهنگ نباشند.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
آموزش
قبل از اینکه بتوانید آموزش خود را شروع کنید، باید هایپرپارامترهایی را که می خواهید در یک نمونه SFTConfig استفاده کنید، تعریف کنید.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
شما اکنون هر بلوک ساختمانی را که برای ایجاد SFTTrainer برای شروع آموزش مدل خود نیاز دارید، در اختیار دارید.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
آموزش را با فراخوانی متد train() شروع کنید.
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
برای ترسیم تلفات آموزشی و اعتبارسنجی، معمولاً این مقادیر را از شی TrainerState یا گزارشهای تولید شده در طول آموزش استخراج میکنید.
کتابخانههایی مانند Matplotlib میتوانند برای تجسم این ارزشها در مراحل یا دورههای آموزشی استفاده شوند. x-asis مراحل یا دوره های آموزشی را نشان می دهد و محور y مقادیر تلفات مربوطه را نشان می دهد.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
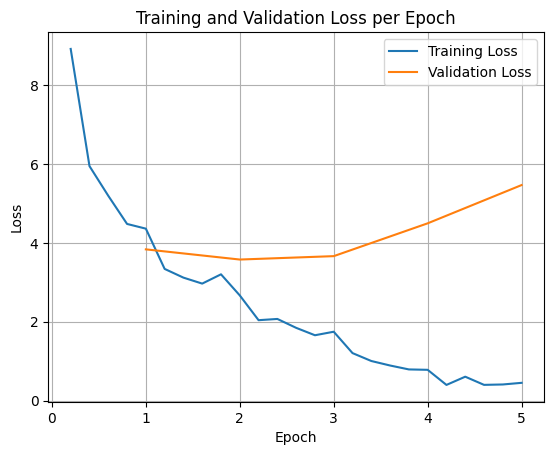
این تجسم به نظارت بر روند آموزش و تصمیم گیری آگاهانه در مورد تنظیم هایپرپارامترها یا توقف اولیه کمک می کند.
از دست دادن آموزش، خطا را در دادههایی که مدل روی آن آموزش داده شده است، اندازهگیری میکند، در حالی که از دست دادن اعتبارسنجی، خطا را در یک مجموعه داده جداگانه اندازهگیری میکند که مدل قبلاً ندیده است. نظارت هر دو به تشخیص بیش از حد برازش کمک می کند (زمانی که مدل در داده های آموزشی خوب عمل می کند اما در داده های دیده نشده ضعیف است).
- از دست دادن اعتبار >> از دست دادن آموزش: بیش از حد برازش
- از دست دادن اعتبار > از دست دادن آموزش: مقداری بیش از حد برازش
- اعتبار زیان < آموزش زیان: مقداری کم تناسب
- از دست دادن اعتبار << از دست دادن آموزش: عدم تناسب
استنتاج مدل تست
پس از پایان آموزش، می خواهید مدل خود را ارزیابی و آزمایش کنید. میتوانید نمونههای مختلف را از مجموعه داده آزمایشی بارگیری کنید و مدل را روی آن نمونهها ارزیابی کنید.
برای این مورد خاص، بهترین مدل یک اولویت است. جالب اینجاست که چیزی که ما معمولا آن را "overfitting" می نامیم می تواند برای یک NPC بازی بسیار مفید باشد. این مدل را مجبور میکند اطلاعات کلی را فراموش کند و در عوض روی شخصیتها و ویژگیهای خاصی که در آن آموزش داده شده، قفل کند، و تضمین میکند که به طور مداوم در شخصیت باقی میماند.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
بیایید همه سؤالات را از مجموعه داده آزمایشی بارگذاری کنیم و خروجی تولید کنیم.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
اگر دستور عمومی اصلی ما را امتحان کنید، می بینید که مدل همچنان سعی می کند به سبک آموزش دیده پاسخ دهد. در این مثال استفاده بیش از حد و فراموشی فاجعه بار در واقع برای بازی NPC مفید است زیرا دانش عمومی را که ممکن است قابل اجرا نباشد فراموش می کند. این همچنین برای سایر انواع تنظیم دقیق کامل که هدف آن محدود کردن خروجی به فرمتهای داده خاص است نیز صادق است.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
خلاصه و مراحل بعدی
این آموزش نحوه تنظیم کامل مدل با استفاده از TRL را شرح می دهد. در ادامه اسناد زیر را بررسی کنید:
- با نحوه تنظیم دقیق Gemma برای کارهای متنی با استفاده از Transformers Hugging Face آشنا شوید.
- با نحوه تنظیم دقیق Gemma برای کارهای بینایی با استفاده از Transformers Hugging Face آشنا شوید.
- نحوه استقرار در Cloud Run را بیاموزید