
多くの企業が AI を効果的に使用できるように、特定の言語で AI テクノロジーを使用することが重要です。Gemma ファミリーのモデルには多言語機能がいくつかありますが、英語以外の言語で使用すると、理想的でない結果が得られることがあります。
幸い、その言語でタスクを完了するために、Gemma にその音声言語全体を教える必要はありません。さらに、Gemma モデルをチューニングして、想像以上に少ないデータと労力で、特定の言語で特定のタスクを完了できます。ターゲット言語で 20 件ほどのリクエストと想定される回答の例を使用して、Gemma を活用して、お客様とお客様の顧客に最適な言語でさまざまなビジネス問題を解決できます。
プロジェクトの概要と拡張方法、作成者からの分析情報については、音声 AI アシスタントの Google AI によるビルド動画をご覧ください。このプロジェクトのコードは、Gemma Cookbook コード リポジトリでも確認できます。それ以外の場合は、次の手順でプロジェクトの拡張を開始できます。
概要
このチュートリアルでは、Gemma と Python で構築された音声タスク アプリケーションの設定、実行、拡張について説明します。このアプリケーションは、ニーズに合わせて変更できる基本的なウェブ ユーザー インターフェースを備えています。このアプリケーションは、架空の韓国のベーカリーからの顧客メールへの返信を生成するように構築されており、すべての言語入力と出力は韓国語で処理されます。このアプリケーション パターンは、テキスト入力とテキスト出力を使用する任意の言語とビジネスタスクで使用できます。
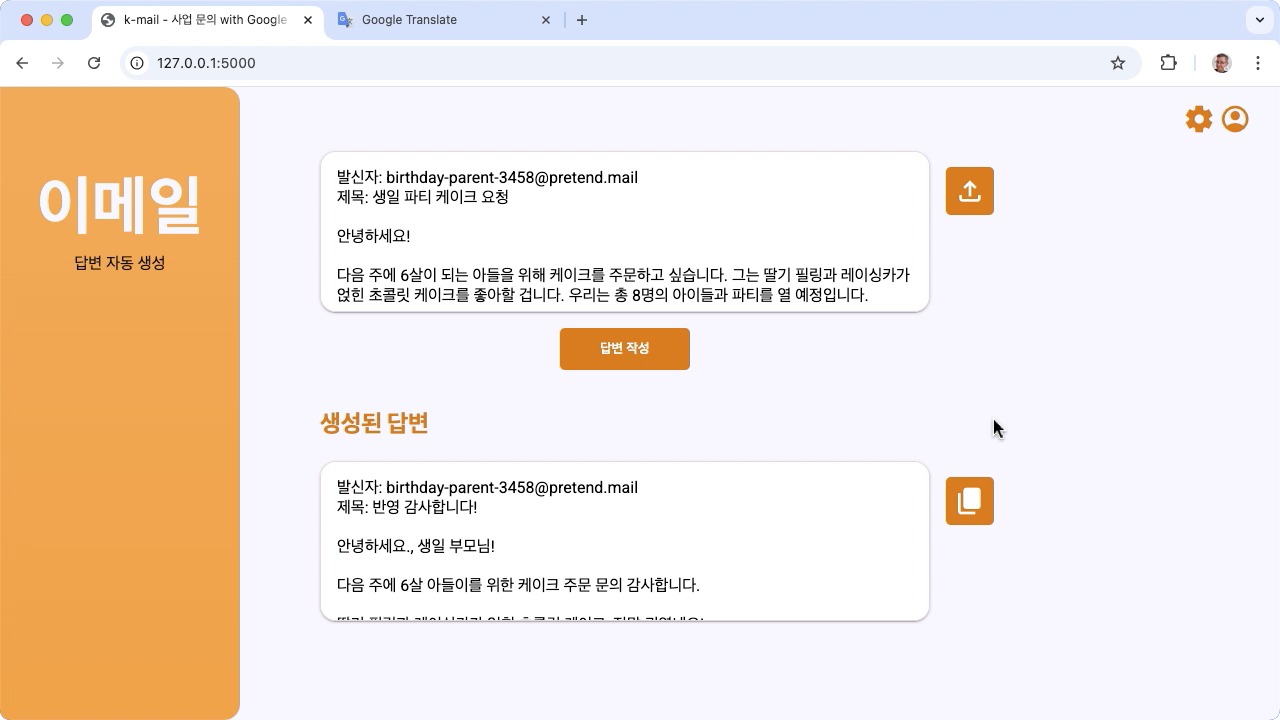
図 1. 韓国のベーカリーからのメール問い合わせに関するプロジェクトのユーザー インターフェース
ハードウェア要件
このチューニング プロセスは、グラフィック プロセッシング ユニット(GPU)または Tensor Processing Unit(TPU)を搭載し、既存のモデルとチューニング データを保持するのに十分なメモリがあるコンピュータで実行します。このプロジェクトでチューニング構成を実行するには、約 16 GB の GPU メモリ、約同じ量の通常の RAM、最小 50 GB のディスク容量が必要です。
このチュートリアルの Gemma モデル チューニング部分は、T4 GPU ランタイムで Colab 環境を使用して実行できます。このプロジェクトを Google Cloud VM インスタンスで構築する場合は、次の要件に沿ってインスタンスを構成します。
- GPU ハードウェア: このプロジェクトを実行するには NVIDIA T4 が必要です。NVIDIA L4 以上が推奨されます。
- オペレーティング システム: [Deep Learning on Linux] オプション(特に、GPU ソフトウェア ドライバがプリインストールされた [Deep Learning VM with CUDA 12.3 M124])を選択します。
- ブートディスク サイズ: データ、モデル、サポート ソフトウェア用に 50 GB 以上のディスク容量をプロビジョニングします。
プロジェクトの設定
ここでは、このプロジェクトを開発とテストの準備にします。一般的な設定手順には、前提条件となるソフトウェアのインストール、コード リポジトリからプロジェクトのクローンを作成する、いくつかの環境変数を設定する、Python ライブラリをインストールする、ウェブ アプリケーションをテストするなどがあります。
Velostrata ソリューションの
このプロジェクトでは、Python 3 と仮想環境(venv)を使用してパッケージを管理し、アプリケーションを実行します。次のインストール手順は、Linux ホストマシン用です。
必要なソフトウェアをインストールするには:
Python 3 と Python 用の
venv仮想環境パッケージをインストールします。sudo apt update sudo apt install git pip python3-venv
プロジェクトのクローンを作成する
プロジェクト コードを開発用コンピュータにダウンロードします。プロジェクトのソースコードを取得するには、git ソース管理ソフトウェアが必要です。
プロジェクト コードをダウンロードするには:
次のコマンドを使用して、Git リポジトリのクローンを作成します。
git clone https://github.com/google-gemini/gemma-cookbook.git必要に応じて、スパース チェックアウトを使用するようにローカル Git リポジトリを構成して、プロジェクトのファイルのみを取得します。
cd gemma-cookbook/ git sparse-checkout set Demos/spoken-language-tasks/ git sparse-checkout init --cone
Python ライブラリをインストールする
venv Python 仮想環境を有効にして Python ライブラリをインストールし、Python パッケージと依存関係を管理します。pip インストーラで Python ライブラリをインストールする前に、必ず Python 仮想環境を有効にしてください。Python 仮想環境の使用方法については、Python venv のドキュメントをご覧ください。
Python ライブラリをインストールするには:
ターミナル ウィンドウで
spoken-language-tasksディレクトリに移動します。cd Demos/spoken-language-tasks/このプロジェクトの Python 仮想環境(venv)を構成して有効にします。
python3 -m venv venv source venv/bin/activatesetup_pythonスクリプトを使用して、このプロジェクトに必要な Python ライブラリをインストールします。./setup_python.sh
環境変数を設定する
Kaggle ユーザー名や Kaggle トークンキーなど、このコード プロジェクトの実行に必要な環境変数をいくつか設定します。Gemma モデルをダウンロードするには、Kaggle アカウントを取得し、Gemma モデルへのアクセスをリクエストする必要があります。このプロジェクトでは、Kaggle ユーザー名と Kaggle トークンキーを 2 つの .env ファイルに追加します。これらのファイルは、ウェブ アプリケーションとチューニング プログラムによって読み取られます。
環境変数を設定するには:
- Kaggle のドキュメントの手順に沿って、Kaggle のユーザー名とトークンキーを取得します。
- Gemma の設定ページの Gemma にアクセスするの手順に沿って、Gemma モデルにアクセスします。
- プロジェクトの環境変数ファイルを作成します。プロジェクトのクローンの次の場所に
.envテキスト ファイルを作成します。k-mail-replier/k_mail_replier/.env k-gemma-it/.env
.envテキスト ファイルを作成したら、両方のファイルに次の設定を追加します。KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
アプリケーションを実行してテストする
プロジェクトのインストールと構成が完了したら、ウェブ アプリケーションを実行して、正しく構成されていることを確認します。これは、独自の用途にプロジェクトを編集する前に、ベースライン チェックとして行う必要があります。
プロジェクトを実行してテストするには:
ターミナル ウィンドウで
/k_mail_replier/ディレクトリに移動します。cd spoken-language-tasks/k-mail-replier/run_flask_app.shスクリプトを使用してアプリケーションを実行します。./run_flask_app.shウェブ アプリケーションを起動すると、プログラムコードに、ブラウジングとテストを行うことができる URL が一覧表示されます。通常、この住所は次のとおりです。
http://127.0.0.1:5000/ウェブ インターフェースで、最初の入力フィールドの下にある [답변 작선] ボタンを押して、モデルからレスポンスを生成します。
アプリケーションの実行後にモデルから返される最初のレスポンスは、最初の生成実行で初期化ステップを完了する必要があるため、時間がかかります。すでに実行中のウェブ アプリケーションで、その後のプロンプト リクエストと生成は短時間で完了します。
アプリケーションを拡張する
アプリケーションを実行したら、ユーザー インターフェースとビジネス ロジックを変更して、ユーザーまたはビジネスに関連するタスクで動作するように拡張できます。アプリが生成 AI モデルに送信するプロンプトのコンポーネントを変更することで、アプリケーション コードを使用して Gemma モデルの動作を変更することもできます。
アプリケーションは、ユーザーからの入力データとともに、モデルの完全なプロンプトとしてモデルに指示を提供します。これらの指示を変更して、モデルの動作を変更できます。たとえば、モデルがリクエストから情報を抽出して JSON などの構造化データ形式に格納するように指定できます。モデルの動作を変更する簡単な方法は、生成された返信を丁寧な口調で記述するように指定するなど、モデルのレスポンスに追加の指示やガイダンスを提供することです。
メッセージの指示を変更するには:
- 音声言語タスク プロジェクトで、
k-mail-replier/k_mail_replier/app.pyコードファイルを開きます。 app.pyコードで、get_prompt():関数に以下の命令を追加します。def get_prompt(): return "발신자에게 요청에 대한 감사를 전하고, 곧 자세한 내용을 알려드리겠다고 정중하게 답장해 주세요. 정중하게 답변해 주세요!:\n"
この例では、韓国語の指示に「Please write a polite response!」というフレーズを追加しています。
追加のプロンプト インストラクションを指定すると、生成される出力に大きな影響を与え、実装に必要な労力を大幅に軽減できます。まず、この方法を試して、モデルから目的の動作を取得できるかどうかを確認する必要があります。ただし、プロンプト インストラクションを使用して Gemma モデルの動作を変更する場合は、制限があります。特に、モデルの全体的な入力トークンの上限(Gemma 2 では 8,192 トークン)があるため、その上限を超えないように、詳細なプロンプト指示と提供する新しいデータのサイズのバランスを取る必要があります。
さらに、Gemma に英語以外の言語でタスクを実行させる場合、ベースモデルにプロンプトを出すだけでは、信頼性の高い有用な結果が得られるとは限りません。代わりに、ターゲット言語のサンプルを使用してモデルをチューニングし、その後、チューニング済みモデルの出力を微調整するためにプロンプト インストラクションの変更を検討してください。
モデルのチューニング
英語以外の音声言語で効果的に応答させるには、Gemma モデルのファインチューニングを行うことをおすすめします。ただし、モデルがターゲット言語でタスクを完了できるようにするために、ターゲット言語で完全に流暢さを持たせる必要はありません。20 個程度のサンプルがあれば、タスクのターゲット言語で基本的な機能を実現できます。このチュートリアルのセクションでは、特定の言語で特定のタスク用に Gemma モデルのファインチューニングを設定して実行する方法について説明します。
次の手順では、VM 環境でファインチューニング オペレーションを行う方法について説明します。このチューニング オペレーションは、このプロジェクトに関連付けられた Colab ノートブックを使用して行うこともできます。
ハードウェア要件
ファインチューニングのコンピューティング要件は、プロジェクトの他の部分のハードウェア要件と同じです。入力トークンを 256 に、バッチサイズを 1 に制限すると、T4 GPU ランタイムを使用して Colab 環境でチューニング オペレーションを実行できます。
データの準備
Gemma モデルのチューニングを開始する前に、チューニング用のデータを準備する必要があります。特定のタスクと言語のモデルをチューニングする場合は、そのターゲット言語のリクエストとレスポンスの例のセットが必須です。これらの例には、手順なしのリクエスト テキストと、想定されるレスポンス テキストが表示されます。まず、約 20 個のサンプルを含むデータセットを準備する必要があります。これらの例は、さまざまなリクエストと理想的なレスポンスを表す必要があります。リクエストとレスポンスが重複しないようにしてください。リクエストとレスポンスが重複すると、モデルのレスポンスが重複し、リクエストの変化に適切に調整されなくなる可能性があります。次の表に、このコード例のデータセットのサンプル レコードを示します。
| リクエスト | レスポンス |
|---|---|
| 싶이은데 한늤의 있의 도이 생セキュア特定 終ページ 케이크 3 개를 케이크 3 개를 세문하세 싶은데 한능할까요? | 영객님, 안요하세요。2주 뒤 아이 생일을 위한 3호 케이크 2개 주문 문의 감사합니다. 네, 3호 케이크 2개 주문 가능합니다. 아이 생일 케이크인 만큼 더욱 신경 써서 정성껏 준비하겠습니다. 혹시 원하시는 디자인이나 특별한 요청 사항이 있으시면 편하게 말씀해주세요. 픽업 날짜와 시간을 알려주시면 더욱 자세한 안내를 도와드리겠습니다. question 번 문의 감사선이며, 안이 생一般に إ심의 축하합요![영름] |
| 안녕하세요, 9월 15일에 있을 아들의 돌잔치를 위해 케이크를 주문하고 싶습니다. - 케이크 종류: 생크림 케이크 림 케이크 쁬季: 2libraries - 안문의크 안: 문자한 신선 세 - 문퉞하선: "첫 생に付与 춓하세, 사- 픽업 날짜 및 시간: 9월 14일 오후 3시 가격 및 주문 가능 여부를 알려주시면 감사하겠습니다. 감사합니다. | 안녕하세요, 김민지 님, 9월 15일 아드님의 돌잔치를 위한 케이크 주문 문의 감사합니다. - 생크림 케이크 2호, 아기자기한 동물 디자인, "첫 생일 축하해, 사랑하는 아들!" 문구, 9월 14 午後 3 時 픽업 모두 가능합니다. - 가격은 5만원입니다. 주문을 원하시면 연락 주세요 감사합니다. [가게 이름] 드림 |
表 1. 韓国のベーカリー メール レスポンダーのチューニング データセットの一部。
データ形式と読み込み
チューニング データは、Python コードでレコードを取得する手段があれば、データベース レコード、JSON ファイル、CSV、プレーンテキスト ファイルなど、任意の形式で保存できます。便宜上、チューニング プログラムの例では、オンライン リポジトリからレコードを取得します。この例では、prepare_tuning_dataset() 関数を使用して、チューニング用データセットが k-gemma-it/main.py モジュールに読み込まれます。
def prepare_tuning_dataset():
tokenizer = keras_nlp.models.GemmaTokenizer.from_preset(model_id)
# load data from repository (or local directory)
from datasets import load_dataset
ds = load_dataset(
# Dataset : https://huggingface.co/datasets/bebechien/korean_cake_boss
"bebechien/korean_cake_boss",
split="train",
)
...
前述のように、関連するレスポンスとともにリクエストを取得し、チューニング レコードとして使用されるテキスト文字列に組み立てることができる限り、データセットを便利な形式で保存できます。
チューニング レコードをアセンブルする
実際のチューニング プロセスでは、各リクエストとレスポンスが、プロンプト インストラクションとタグとともに 1 つの文字列に組み合わされ、リクエストの内容とレスポンスの内容が示されます。このチューニング プログラムは、モデルで使用するために文字列をトークン化します。チューニング レコードをアセンブルするコードは、k-gemma-it/main.py モジュールの prepare_tuning_dataset() 関数にあります。
def prepare_tuning_dataset():
...
prompt_instruction = "다음에 대한 이메일 답장을 작성해줘."
for x in data:
item = f"<start_of_turn>user\n{prompt_instruction}\n\"{x['input']}\"<end_of_turn>\n<start_of_turn>model\n{x['output']}<end_of_turn>"
length = len(tokenizer(item))
# skip data if the token length is longer than our limit
if length < token_limit:
tuning_dataset.append(item)
if(len(tuning_dataset)>=num_data_limit):
break
...
この関数は、データを読み取り、start_of_turn タグと end_of_turn タグを追加してフォーマットします。これは、Gemma モデルのチューニングにデータを提供する際の必須形式です。このコードでは、リクエストごとに prompt_instruction も挿入されます。これは、アプリに応じて編集する必要があります。
モデルの重みを生成する
チューニング データが配置され、読み込まれたら、チューニング プログラムを実行できます。このサンプル アプリケーションのチューニング プロセスでは、Keras NLP ライブラリを使用して、低ランク適応(LoRA)手法でモデルをチューニングし、新しいモデルの重みを生成します。LoRA を使用すると、モデル重みに対する変更を近似するため、完全な精度チューニングと比較してメモリ効率が大幅に向上します。これらの近似重みを既存のモデル重みに重ねて、モデルの動作を変更できます。
チューニング実行を行い、新しい重みを計算するには:
ターミナル ウィンドウで、
k-gemma-it/ディレクトリに移動します。cd spoken-language-tasks/k-gemma-it/tune_modelスクリプトを使用してチューニング プロセスを実行します。./tune_model.sh
チューニング プロセスは、使用可能なコンピューティング リソースに応じて数分間かかります。正常に完了すると、チューニング プログラムは、次の形式で新しい *.h5 重みファイルを k-gemma-it/weights ディレクトリに書き込みます。
gemma2-2b_k-tuned_4_epoch##.lora.h5
トラブルシューティング
チューニングが正常に完了しない場合は、次の 2 つの原因が考えられます。
- メモリ不足 / リソースの枯渇: これらのエラーは、チューニング プロセスが使用可能な GPU メモリまたは CPU メモリを超えるメモリをリクエストした場合に発生します。チューニング プロセスの実行中にウェブ アプリケーションを実行していないことを確認します。16 GB の GPU メモリを搭載したデバイスでチューニングする場合は、
token_limitを 256 に、batch_sizeを 1 に設定します。 - GPU ドライバがインストールされていないか、JAX と互換性がない: 変換プロセスでは、JAX ライブラリのバージョンと互換性のあるハードウェア ドライバがコンピューティング デバイスにインストールされている必要があります。詳細については、JAX のインストールのドキュメントをご覧ください。
チューニング済みモデルをデプロイする
チューニング プロセスでは、チューニング データとチューニング アプリケーションで設定されたエポックの合計数に基づいて複数の重みが生成されます。デフォルトでは、チューニング プログラムは 20 個のモデル重みファイルを生成します(チューニング エポックごとに 1 つ)。その後の各チューニング エポックでは、チューニング データの結果をより正確に再現する重みが生成されます。各エポックの精度率は、チューニング プロセスのターミナル出力で確認できます。
...
Epoch 14/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 567ms/step - loss: 0.4026 - sparse_categorical_accuracy: 0.8235
Epoch 15/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 569ms/step - loss: 0.3659 - sparse_categorical_accuracy: 0.8382
Epoch 16/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 571ms/step - loss: 0.3314 - sparse_categorical_accuracy: 0.8538
Epoch 17/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 572ms/step - loss: 0.2996 - sparse_categorical_accuracy: 0.8686
Epoch 18/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 574ms/step - loss: 0.2710 - sparse_categorical_accuracy: 0.8801
Epoch 19/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2451 - sparse_categorical_accuracy: 0.8903
Epoch 20/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2212 - sparse_categorical_accuracy: 0.9021
精度率は比較的高い(0.80~0.90 程度)にする必要がありますが、率が高すぎる(1.00 に非常に近い)と、重みがチューニング データの過学習に近づいていることを意味するため、注意が必要です。その場合、モデルは、チューニング例と大きく異なるリクエストに対して良好なパフォーマンスを発揮しません。デフォルトでは、デプロイ スクリプトはエポック 17 の重みを選択します。この重みは通常、精度が約 0.90 です。
生成された重みをウェブ アプリケーションにデプロイするには:
ターミナル ウィンドウで、
k-gemma-it/ディレクトリに移動します。cd spoken-language-tasks/k-gemma-it/deploy_weightsスクリプトを使用してチューニング プロセスを実行します。./deploy_weights.sh
このスクリプトを実行すると、k-mail-replier/k_mail_replier/weights/ ディレクトリに新しい *.h5 ファイルが表示されます。
新しいモデルをテストする
新しい重みをアプリケーションにデプロイしたら、新しくチューニングされたモデルを試します。これを行うには、ウェブ アプリケーションを再実行し、レスポンスを生成します。
プロジェクトを実行してテストするには:
ターミナル ウィンドウで、
/k_mail_replier/ディレクトリに移動します。cd spoken-language-tasks/k-mail-replier/run_flask_app.shスクリプトを使用してアプリケーションを実行します。./run_flask_app.shウェブ アプリケーションを起動すると、プログラムコードに、ブラウジングとテストを行うことができる URL がリストされます。通常、このアドレスは次のとおりです。
http://127.0.0.1:5000/ウェブ インターフェースで、最初の入力フィールドの下にある [답변 작성] ボタンを押して、モデルからレスポンスを生成します。
これで、アプリケーションで Gemma モデルのチューニングとデプロイが完了しました。アプリケーションをテストして、タスクに対するチューニング済みモデルの生成機能の制限を判断してみてください。モデルのパフォーマンスが低下するシナリオが見つかった場合は、リクエストを追加して理想的なレスポンスを提供することで、チューニング用サンプルデータのリストにこれらのリクエストの一部を追加することを検討してください。次に、チューニング プロセスを再実行し、新しい重みを再デプロイして、出力をテストします。
参考情報
このプロジェクトの詳細については、Gemma クックブック コード リポジトリをご覧ください。アプリケーションの構築についてサポートが必要な場合や、他のデベロッパーとコラボレーションしたい場合は、Google Developers Community Discord サーバーをご利用ください。Google AI を活用して構築するプロジェクトについては、動画の再生リストをご覧ください。