
การใช้เทคโนโลยีปัญญาประดิษฐ์ (AI) กับภาษาพูดบางอย่างเป็นสิ่งจำเป็นที่สำคัญอย่างยิ่งที่ธุรกิจจำนวนมากจำเป็นต้องใช้เทคโนโลยีดังกล่าวอย่างมีประสิทธิภาพ โมเดลตระกูล Gemma มีความสามารถในการทำงานหลายภาษา แต่การใช้โมเดลนี้ในภาษาอื่นที่ไม่ใช่ภาษาอังกฤษมักจะให้ผลลัพธ์ที่ไม่เป็นไปตามที่ต้องการ
แต่ไม่ต้องกังวล คุณไม่จำเป็นต้องสอน Gemma ให้พูดภาษานั้นๆ ทั้งหมดเพื่อให้ทำงานในภาษานั้นๆ ได้ ยิ่งไปกว่านั้น คุณยังสามารถปรับแต่งโมเดล Gemma เพื่อ ทำงานบางอย่างให้เสร็จในภาษาหนึ่งๆ โดยใช้ข้อมูลและความพยายามน้อยกว่าที่คุณคิด เมื่อใช้ตัวอย่างคำขอและการตอบกลับที่คาดหวังประมาณ 20 รายการในภาษาเป้าหมาย คุณจะทําให้ Gemma ช่วยแก้ปัญหาทางธุรกิจที่หลากหลายในภาษาที่เหมาะกับคุณและลูกค้ามากที่สุดได้
หากต้องการดูวิดีโอภาพรวมของโปรเจ็กต์และวิธีต่อยอดโปรเจ็กต์ รวมถึงข้อมูลเชิงลึกจากเพื่อนๆ ที่สร้างโปรเจ็กต์ โปรดดูวิดีโอตัวช่วย AI ภาษาพูด สร้างสรรค์ด้วย AI ของ Google นอกจากนี้ คุณยังตรวจสอบโค้ดของโปรเจ็กต์นี้ได้ในที่เก็บโค้ด Gemma Cookbook หรือจะเริ่มต้นขยายโปรเจ็กต์โดยใช้วิธีการต่อไปนี้ก็ได้
ภาพรวม
บทแนะนำนี้จะแนะนำการตั้งค่า การดำเนินการ และขยายแอปพลิเคชันงานภาษาพูดที่สร้างด้วย Gemma และ Python แอปพลิเคชันมีอินเทอร์เฟซผู้ใช้เว็บพื้นฐานที่คุณสามารถแก้ไขให้เหมาะกับความต้องการได้ แอปพลิเคชันสร้างขึ้นเพื่อสร้างการตอบกลับอีเมลของลูกค้าสำหรับร้านเบเกอรี่สมมติในเกาหลี และระบบจะจัดการอินพุตและเอาต์พุตภาษาทั้งหมดเป็นภาษาเกาหลี คุณสามารถใช้รูปแบบแอปพลิเคชันนี้กับภาษาใดก็ได้และงานทางธุรกิจใดก็ได้ที่ใช้การป้อนข้อมูลข้อความและเอาต์พุตข้อความ
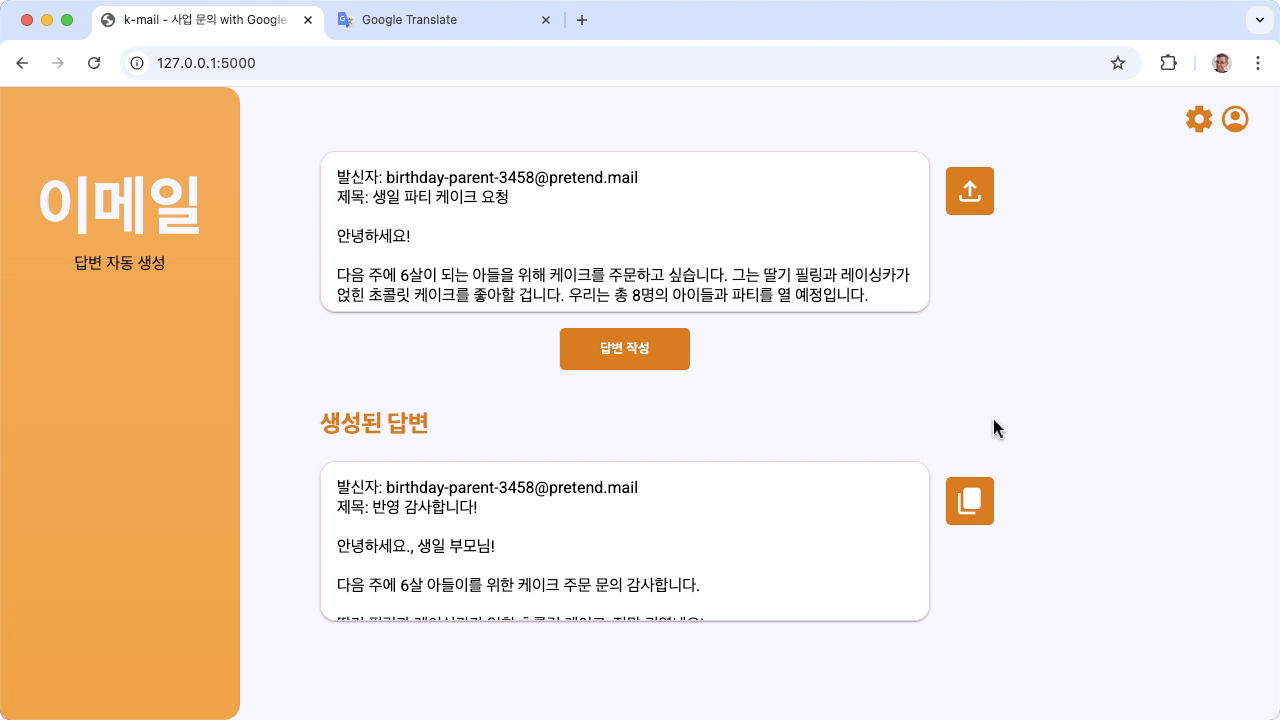
รูปที่ 1 อินเทอร์เฟซผู้ใช้ของโปรเจ็กต์สําหรับคําถามทางอีเมลเกี่ยวกับเบเกอรี่ในเกาหลี
ข้อกำหนดเกี่ยวกับฮาร์ดแวร์
เรียกใช้กระบวนการปรับแต่งนี้ในคอมพิวเตอร์ที่มีหน่วยประมวลผลกราฟิก (GPU) หรือ Tensor Processing Unit (TPU) และหน่วยความจําเพียงพอที่จะเก็บโมเดลที่มีอยู่ รวมถึงข้อมูลการปรับแต่ง หากต้องการเรียกใช้การกำหนดค่าการปรับแต่งในโปรเจ็กต์นี้ คุณต้องมีหน่วยความจำ GPU ประมาณ 16 GB, RAM ปกติประมาณเท่าๆ กัน และพื้นที่ว่างในดิสก์อย่างน้อย 50 GB
คุณเรียกใช้ส่วนการปรับแต่งโมเดล Gemma ของบทแนะนำนี้โดยใช้สภาพแวดล้อม Colab ที่มีรันไทม์ T4 GPU ได้ หากคุณสร้างโปรเจ็กต์นี้ในอินสแตนซ์ VM ของ Google Cloud ให้กําหนดค่าอินสแตนซ์ตามข้อกําหนดต่อไปนี้
- ฮาร์ดแวร์ GPU: ต้องใช้ NVIDIA T4 เพื่อใช้งานโปรเจ็กต์นี้ และเราขอแนะนำให้ใช้ NVIDIA L4 ขึ้นไป
- ระบบปฏิบัติการ: เลือกตัวเลือกการเรียนรู้เชิงลึกใน Linux โดยเฉพาะ VM สำหรับการเรียนรู้เชิงลึกที่มี CUDA 12.3 M124 ที่มีไดรเวอร์ซอฟต์แวร์ GPU ติดตั้งไว้ล่วงหน้า
- ขนาดดิสก์บูท: จัดสรรพื้นที่ดิสก์อย่างน้อย 50 GB สำหรับข้อมูล โมเดล และซอฟต์แวร์ที่รองรับ
การตั้งค่าโปรเจ็กต์
วิธีการเหล่านี้จะแนะนำคุณเกี่ยวกับการเตรียมโปรเจ็กต์นี้ให้พร้อมสําหรับการพัฒนาและการทดสอบ ขั้นตอนการตั้งค่าทั่วไป ได้แก่ การติดตั้งซอฟต์แวร์ที่จำเป็นก่อน การโคลนโปรเจ็กต์จากที่เก็บโค้ด การตั้งค่าตัวแปรสภาพแวดล้อมบางรายการ การติดตั้งไลบรารี Python และการทดสอบเว็บแอปพลิเคชัน
ติดตั้งและกำหนดค่า
โปรเจ็กต์นี้ใช้ Python 3 และสภาพแวดล้อมเสมือน (venv) เพื่อจัดการแพ็กเกจและเรียกใช้แอปพลิเคชัน วิธีการติดตั้งต่อไปนี้มีไว้สำหรับเครื่องโฮสต์ Linux
วิธีติดตั้งซอฟต์แวร์ที่จำเป็น
ติดตั้ง Python 3 และแพ็กเกจสภาพแวดล้อมเสมือน
venvสำหรับ Pythonsudo apt update sudo apt install git pip python3-venv
โคลนโปรเจ็กต์
ดาวน์โหลดรหัสโปรเจ็กต์ลงในคอมพิวเตอร์การพัฒนา คุณต้องมีซอฟต์แวร์ควบคุมแหล่งที่มา git เพื่อเรียกซอร์สโค้ดของโปรเจ็กต์
วิธีดาวน์โหลดรหัสโปรเจ็กต์
โคลนที่เก็บ Git โดยใช้คําสั่งต่อไปนี้
git clone https://github.com/google-gemini/gemma-cookbook.git(ไม่บังคับ) กำหนดค่าที่เก็บ Git ในพื้นที่ให้ใช้การตรวจสอบแบบเบาบางเพื่อให้คุณมีเฉพาะไฟล์สำหรับโปรเจ็กต์
cd gemma-cookbook/ git sparse-checkout set Demos/spoken-language-tasks/ git sparse-checkout init --cone
ติดตั้งไลบรารี Python
ติดตั้งไลบรารี Python ด้วยสภาพแวดล้อมเสมือนของ Python venv ซึ่งเปิดใช้งานเพื่อจัดการแพ็กเกจ Python และการอ้างอิง ตรวจสอบว่าคุณได้เปิดใช้งานสภาพแวดล้อมเสมือนของ Python ก่อนติดตั้งไลบรารี Python ด้วยโปรแกรมติดตั้ง pip ดูข้อมูลเพิ่มเติมเกี่ยวกับการใช้สภาพแวดล้อมเสมือนของ Python ได้ในเอกสารประกอบ Python venv
วิธีติดตั้งไลบรารี Python
ในหน้าต่างเทอร์มินัล ให้ไปที่ไดเรกทอรี
spoken-language-tasksโดยทำดังนี้cd Demos/spoken-language-tasks/กําหนดค่าและเปิดใช้งานสภาพแวดล้อมเสมือนของ Python (venv) สําหรับโปรเจ็กต์นี้
python3 -m venv venv source venv/bin/activateติดตั้งไลบรารี Python ที่จําเป็นสําหรับโปรเจ็กต์นี้โดยใช้สคริปต์
setup_python./setup_python.sh
ตั้งค่าตัวแปรสภาพแวดล้อม
ตั้งค่าตัวแปรสภาพแวดล้อม 2-3 รายการที่จําเป็นเพื่อให้โปรเจ็กต์โค้ดนี้ทํางานได้ ซึ่งรวมถึงชื่อผู้ใช้ Kaggle และคีย์โทเค็น Kaggle คุณต้องมีบัญชี Kaggle และขอสิทธิ์เข้าถึงโมเดล Gemma จึงจะดาวน์โหลดโมเดลได้ สําหรับโปรเจ็กต์นี้ คุณต้องเพิ่มชื่อผู้ใช้ Kaggle และคีย์โทเค็น Kaggle ลงใน.envไฟล์ 2 ไฟล์ ซึ่งเว็บแอปพลิเคชันและโปรแกรมการปรับแต่งจะอ่านตามลําดับ
วิธีตั้งค่าตัวแปรสภาพแวดล้อม
- รับชื่อผู้ใช้ Kaggle และคีย์โทเค็นโดยทําตามวิธีการในเอกสารประกอบของ Kaggle
- รับสิทธิ์เข้าถึงโมเดล Gemma โดยทําตามวิธีการรับสิทธิ์เข้าถึง Gemma ในหน้าการตั้งค่า Gemma
- สร้างไฟล์ตัวแปรสภาพแวดล้อมสำหรับโปรเจ็กต์ โดยสร้างไฟล์ข้อความ
.envที่แต่ละตำแหน่งในตำแหน่งต่อไปนี้ในโคลนของโปรเจ็กต์k-mail-replier/k_mail_replier/.env k-gemma-it/.env
หลังจากสร้างไฟล์ข้อความ
.envแล้ว ให้เพิ่มการตั้งค่าต่อไปนี้ลงในทั้งไฟล์KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
เรียกใช้และทดสอบแอปพลิเคชัน
เมื่อติดตั้งและกำหนดค่าโปรเจ็กต์เสร็จแล้ว ให้เรียกใช้เว็บแอปพลิเคชันเพื่อยืนยันว่าคุณได้กำหนดค่าอย่างถูกต้อง คุณควรดำเนินการนี้เพื่อตรวจสอบพื้นฐานก่อนแก้ไขโปรเจ็กต์เพื่อการใช้งานของคุณเอง
วิธีเรียกใช้และทดสอบโปรเจ็กต์
ในหน้าต่างเทอร์มินัล ให้ไปที่ไดเรกทอรี
/k_mail_replier/โดยทำดังนี้cd spoken-language-tasks/k-mail-replier/เรียกใช้แอปพลิเคชันโดยใช้สคริปต์
run_flask_app.sh./run_flask_app.shหลังจากเริ่มเว็บแอปพลิเคชันแล้ว โค้ดโปรแกรมจะแสดง URL ที่คุณเรียกดูและทดสอบได้ โดยปกติแล้วที่อยู่นี้จะมีลักษณะดังนี้
http://127.0.0.1:5000/ในเว็บอินเทอร์เฟซ ให้กดปุ่ม 답변 작성 ใต้ช่องป้อนข้อมูลแรกเพื่อสร้างคำตอบจากโมเดล
การตอบกลับครั้งแรกจากโมเดลหลังจากที่คุณเรียกใช้แอปพลิเคชันจะใช้เวลานานขึ้นเนื่องจากต้องทําตามขั้นตอนการเริ่มต้นในรุ่นที่ 1 ให้เสร็จสมบูรณ์ คำขอและการสร้างพรอมต์ในเว็บแอปพลิเคชันที่ทำงานอยู่จะเสร็จสมบูรณ์ได้เร็วขึ้น
ขยายเวลาการสมัคร
เมื่อแอปพลิเคชันทำงานแล้ว คุณสามารถขยายแอปพลิเคชันได้โดยแก้ไขอินเทอร์เฟซผู้ใช้และตรรกะทางธุรกิจเพื่อให้แอปพลิเคชันทำงานกับงานที่เกี่ยวข้องกับคุณหรือธุรกิจของคุณ นอกจากนี้ คุณยังแก้ไขลักษณะการทำงานของโมเดล Gemma ได้โดยใช้โค้ดแอปพลิเคชันด้วยการเปลี่ยนคอมโพเนนต์ของพรอมต์ที่แอปส่งไปยังโมเดล Generative AI
แอปพลิเคชันจะระบุวิธีการให้กับโมเดลพร้อมกับข้อมูลอินพุตจากผู้ใช้ ซึ่งเป็นพรอมต์ที่สมบูรณ์ของโมเดล คุณสามารถแก้ไขวิธีการเหล่านี้เพื่อเปลี่ยนลักษณะการทํางานของโมเดล เช่น ระบุว่าโมเดลควรดึงข้อมูลจากคําขอและใส่ไว้ในรูปแบบ Structured Data เช่น JSON วิธีเปลี่ยนลักษณะการทํางานของโมเดลที่ง่ายกว่านั้นคือการระบุวิธีการหรือคําแนะนําเพิ่มเติมสําหรับคําตอบของโมเดล เช่น ระบุว่าคําตอบที่สร้างขึ้นควรเขียนด้วยถ้อยคำที่สุภาพ
วิธีแก้ไขวิธีการของพรอมต์
- เปิดไฟล์โค้ด
k-mail-replier/k_mail_replier/app.pyในโปรเจ็กต์ภาษาที่พูด ในโค้ด
app.pyให้เพิ่มวิธีการเพิ่มเติมลงในฟังก์ชันget_prompt():ดังนี้def get_prompt(): return "발신자에게 요청에 대한 감사를 전하고, 곧 자세한 내용을 알려드리겠다고 정중하게 답장해 주세요. 정중하게 답변해 주세요!:\n"
ตัวอย่างนี้จะเพิ่มวลี "โปรดตอบกลับอย่างสุภาพ" ลงในวิธีการเป็นภาษาเกาหลี
การให้คำสั่งเพิ่มเติมแก่พรอมต์เพิ่มเติมอาจมีอิทธิพลต่อเอาต์พุตที่สร้างขึ้นได้อย่างมาก และใช้เวลาน้อยลงอย่างมากในการติดตั้งใช้งาน คุณควรลองใช้วิธีนี้ก่อนเพื่อดูว่าโมเดลให้ลักษณะการทำงานที่ต้องการได้หรือไม่ อย่างไรก็ตาม การใช้คำสั่งพรอมต์เพื่อแก้ไขลักษณะการทํางานของโมเดล Gemma มีข้อจํากัด โดยเฉพาะอย่างยิ่ง ขีดจํากัดโทเค็นอินพุตโดยรวมของโมเดล ซึ่งเท่ากับ 8,192 โทเค็นสําหรับ Gemma 2 กำหนดให้คุณต้องปรับสมดุลระหว่างวิธีการพรอมต์แบบละเอียดกับขนาดของข้อมูลใหม่ที่ให้ไว้เพื่อให้อยู่ภายใต้ขีดจํากัดดังกล่าว
นอกจากนี้ เมื่อคุณต้องการให้ Gemma ทํางานในภาษาอื่นที่ไม่ใช่ภาษาอังกฤษ เพียงแค่การแจ้งให้โมเดลพื้นฐานทํางานก็อาจให้ผลลัพธ์ที่มีประโยชน์และเชื่อถือไม่ได้ แต่คุณควรปรับแต่งโมเดลด้วยตัวอย่างในภาษาเป้าหมาย แล้วจากนั้นพิจารณาแก้ไขคำสั่งพรอมต์เพื่อทำการปรับเปลี่ยนเล็กน้อยกับเอาต์พุตของโมเดลที่ปรับแต่ง
ปรับแต่งโมเดล
การปรับแต่งโมเดล Gemma เป็นวิธีที่แนะนําเพื่อให้โมเดลตอบกลับได้อย่างมีประสิทธิภาพในภาษาพูดที่ไม่ใช่ภาษาอังกฤษ อย่างไรก็ตาม คุณไม่จำเป็นต้องภาษาเป้าหมายให้คล่องแคล่วเพื่อให้โมเดลทำงานในภาษานั้นได้ คุณสามารถบรรลุฟังก์ชันการทำงานพื้นฐานในภาษาเป้าหมาย สำหรับงานที่มีตัวอย่างประมาณ 20 รายการ ส่วนนี้ของบทแนะนำจะอธิบายวิธีตั้งค่าและเรียกใช้การปรับแต่งในโมเดล Gemma สำหรับงานหนึ่งๆ ในภาษาหนึ่งๆ
วิธีการต่อไปนี้อธิบายวิธีดำเนินการปรับแต่งในสภาพแวดล้อม VM แต่คุณยังทำการปรับแต่งนี้โดยใช้สมุดบันทึก Colab ที่เชื่อมโยงกับโปรเจ็กต์นี้ได้ด้วย
ข้อกำหนดเกี่ยวกับฮาร์ดแวร์
ข้อกำหนดด้านการคำนวณสำหรับการปรับแต่งจะเหมือนกับข้อกำหนดด้านฮาร์ดแวร์สำหรับโปรเจ็กต์ที่เหลือ คุณสามารถเรียกใช้การดำเนินการปรับแต่งในสภาพแวดล้อม Colab ด้วยรันไทม์ T4 GPU หากคุณจำกัดโทเค็นอินพุตไว้ที่ 256 และขนาดกลุ่มเป็น 1
เตรียมข้อมูล
ก่อนเริ่มปรับแต่งโมเดล Gemma คุณต้องเตรียมข้อมูลสำหรับการปรับแต่ง เมื่อปรับแต่งโมเดลสำหรับงานและภาษาที่เฉพาะเจาะจง คุณต้องมีชุดตัวอย่างคำขอและการตอบกลับในภาษาเป้าหมายนั้น ตัวอย่างเหล่านี้ควรแสดงข้อความคำขอโดยไม่มีวิธีการใดๆ และข้อความตอบกลับที่คาดหวัง ในการเริ่มต้น คุณควรเตรียมชุดข้อมูลที่มีตัวอย่างประมาณ 20 รายการ ตัวอย่างเหล่านี้ควรแสดงคำขอที่หลากหลายและคำตอบที่เหมาะสม ตรวจสอบว่าคำขอและการตอบกลับไม่ซ้ำกัน เนื่องจากอาจทําให้คำตอบของโมเดลซ้ำกันและไม่ได้ปรับให้เหมาะสมกับคำขอที่หลากหลาย ตารางต่อไปนี้แสดงตัวอย่างระเบียนตัวอย่างจากชุดข้อมูลของตัวอย่างโค้ดนี้
| ส่งคำขอ | คำตอบ |
|---|---|
| 안녕하세요, 2주 뒤에 있을 아이 생일을 위해 3호 케이크 3개를 주문하고 싶은데 가능할까요? | 고객님, 안녕하세요. 2주 뒤 아이 생일을 위한 3호 케이크 2개 주문 문의 감사합니다. 네, 3호 케이크 2개 주문 가능합니다. 아이 생일 케이크인 만큼 더욱 신경 써서 정성껏 준비하겠습니다. 혹시 원하시는 디자인이나 특별한 요청 사항이 있으시면 편하게 말씀해주세요. โปรดแจ้งวันที่และเวลาที่ต้องการรับพัสดุเพื่อให้เราช่วยเหลือคุณได้อย่างละเอียด 다시 한번 문의 감사드리며, 아이 생일 진심으로 축하합니다! [가게 이름] 드림 |
| ’ - 케이크 종류: 생크림 케이크 - 크ข้อผิดพลาดนี้: 2ได้รับคะแนน - 디종류: 생크림 케이크 - 크ข้อผิดพลาดนี้: 2ได้รับคะแนน - 디아: 아คำบรรยายภาพ 동물 디이 동묶 디사 동묶 디이 생아딄 แบบนี้ประสงค์ - 픽업 날짜 및 시간: 9월 14일 오후 3시 가격 및 주문 가능 여부를 알려주시면 감사하겠습니다. 감사합니다. 김민지 드림 | 안녕의세요, 김사 님, 9월 15การมองเห็น 아드님 돌잔치를 สำหรับคำสั่งซื้อ 케이크 🏡문 문의 감 사사니다. - 생크림 케이크 2นานา, 아ดูได้ว่า자이한 동물 디자ク, "첫 생사 축การผสานอย่างราบรื่น, 사랑한는 아들!" 문구, 9월 14ไม่ได้ระบุ 오후 3การทำเช่นนี้ 픽 모두 ق능사다. - 가격은 5만원입니다. 주문을 원하시면 연락 주세요 감사합니다. [TRUE게 이름] 드림 |
ตารางที่ 1 รายชื่อบางส่วนของการปรับแต่งชุดข้อมูลสำหรับการตอบอีเมลร้านเบเกอรี่เกาหลี
รูปแบบและโหลดข้อมูล
คุณสามารถจัดเก็บข้อมูลการปรับแต่งในรูปแบบใดก็ได้ที่สะดวก ซึ่งรวมถึงระเบียนฐานข้อมูล ไฟล์ JSON, CSV หรือไฟล์ข้อความล้วน ตราบใดที่คุณมีวิธีเรียกข้อมูลระเบียนด้วยโค้ด Python เพื่อความสะดวก โปรแกรมปรับแต่งตัวอย่างจะรับระเบียนจากที่เก็บออนไลน์
ในตัวอย่างนี้ โปรแกรมเปลี่ยนรูปแบบจะโหลดชุดข้อมูลการปรับแต่งในข้อบังคับ k-gemma-it/main.py โดยใช้ฟังก์ชัน prepare_tuning_dataset()
def prepare_tuning_dataset():
tokenizer = keras_nlp.models.GemmaTokenizer.from_preset(model_id)
# load data from repository (or local directory)
from datasets import load_dataset
ds = load_dataset(
# Dataset : https://huggingface.co/datasets/bebechien/korean_cake_boss
"bebechien/korean_cake_boss",
split="train",
)
...
ดังที่ได้กล่าวไว้ก่อนหน้านี้ คุณสามารถจัดเก็บชุดข้อมูลในรูปแบบที่สะดวกได้ ตราบใดที่คุณดึงคำขอที่มีคำตอบที่เกี่ยวข้องและรวบรวมเป็นสตริงข้อความที่จะใช้เป็นระเบียนการปรับแต่งได้
รวบรวมระเบียนการปรับแต่ง
สําหรับขั้นตอนการปรับแต่งจริง ระบบจะประกอบคําขอและการตอบกลับแต่ละรายการเป็นสตริงเดียวพร้อมคําแนะนําพรอมต์และแท็กเพื่อระบุเนื้อหาของคําขอและเนื้อหาของคําตอบ จากนั้นโปรแกรมการปรับแต่งนี้จะแบ่งสตริงออกเป็นโทเค็นเพื่อให้โมเดลนำไปใช้ คุณดูโค้ดสำหรับการสร้างไฟล์บันทึกการปรับแต่งได้ในฟังก์ชันk-gemma-it/main.pyโมดูล prepare_tuning_dataset() ดังนี้
def prepare_tuning_dataset():
...
prompt_instruction = "다음에 대한 이메일 답장을 작성해줘."
for x in data:
item = f"<start_of_turn>user\n{prompt_instruction}\n\"{x['input']}\"<end_of_turn>\n<start_of_turn>model\n{x['output']}<end_of_turn>"
length = len(tokenizer(item))
# skip data if the token length is longer than our limit
if length < token_limit:
tuning_dataset.append(item)
if(len(tuning_dataset)>=num_data_limit):
break
...
ฟังก์ชันนี้จะอ่านข้อมูลและจัดรูปแบบโดยเพิ่มแท็ก start_of_turn และ end_of_turn ซึ่งเป็นรูปแบบที่จำเป็นเมื่อให้ข้อมูลสำหรับการปรับแต่งโมเดล Gemma โค้ดนี้จะแทรก prompt_instruction สําหรับคําขอแต่ละรายการด้วย ซึ่งคุณควรแก้ไขให้เหมาะสมกับแอปพลิเคชัน
สร้างน้ำหนักโมเดล
เมื่อคุณมีข้อมูลการปรับแต่งและกำลังโหลด คุณจะเรียกใช้โปรแกรมการปรับแต่งได้ กระบวนการปรับแต่งสําหรับแอปพลิเคชันตัวอย่างนี้ใช้คลัง Keras NLP เพื่อปรับแต่งโมเดลด้วยการปรับให้เข้ากับลําดับชั้นต่ำหรือเทคนิค LoRA เพื่อสร้างน้ำหนักโมเดลใหม่ เมื่อเทียบกับการปรับแต่งแบบแม่นยำทั้งหมด การใช้ LoRA จะใช้หน่วยความจําได้มีประสิทธิภาพมากขึ้นอย่างเห็นได้ชัด เนื่องจากจะประมาณการเปลี่ยนแปลงของน้ำหนักโมเดล คุณสามารถวางน้ำหนักโดยประมาณเหล่านี้ซ้อนลงบนน้ำหนักโมเดลที่มีอยู่เพื่อเปลี่ยนลักษณะการทำงานของโมเดลได้
วิธีเรียกใช้การปรับแต่งและคำนวณน้ำหนักใหม่
ในหน้าต่างเทอร์มินัล ให้ไปยังไดเรกทอรี
k-gemma-it/cd spoken-language-tasks/k-gemma-it/เรียกใช้กระบวนการปรับโดยใช้สคริปต์
tune_model./tune_model.sh
กระบวนการปรับแต่งจะใช้เวลาหลายนาที ทั้งนี้ขึ้นอยู่กับทรัพยากรการประมวลผลที่คุณมี เมื่อดำเนินการเสร็จสมบูรณ์แล้ว โปรแกรมการปรับแต่งจะเขียนไฟล์ *.h5
weight ใหม่ในไดเรกทอรี k-gemma-it/weights โดยใช้รูปแบบต่อไปนี้
gemma2-2b_k-tuned_4_epoch##.lora.h5
การแก้ปัญหา
หากการปรับแต่งไม่เสร็จสมบูรณ์ สาเหตุที่เป็นไปได้มี 2 ประการดังนี้
- หน่วยความจําไม่เพียงพอ / ทรัพยากรหมด: ข้อผิดพลาดเหล่านี้เกิดขึ้นเมื่อกระบวนการปรับแต่งขอหน่วยความจําที่มากกว่าหน่วยความจํา GPU หรือหน่วยความจํา CPU ที่มีอยู่ ตรวจสอบว่าไม่ได้เรียกใช้เว็บแอปพลิเคชันในขณะที่กระบวนการปรับแต่งทำงานอยู่ หากคุณปรับแต่งในอุปกรณ์ที่มีหน่วยความจำ GPU 16 GB ให้ตรวจสอบว่าได้ตั้งค่า
token_limitเป็น 256 และตั้งค่าbatch_sizeเป็น 1 - ไม่ได้ติดตั้งไดรเวอร์ GPU หรือเข้ากันไม่ได้กับ JAX: กระบวนการเปิดใช้กำหนดให้อุปกรณ์ประมวลผลต้องติดตั้งไดรเวอร์ฮาร์ดแวร์ที่เข้ากันได้กับเวอร์ชันของไลบรารี JAX โปรดดูรายละเอียดเพิ่มเติมในเอกสารประกอบการติดตั้ง JAX
ทำให้โมเดลที่ปรับแต่งแล้วใช้งานได้
กระบวนการปรับแต่งจะสร้างน้ำหนักหลายรายการตามข้อมูลการปรับแต่งและจํานวนรอบทั้งหมดที่ตั้งไว้ในแอปพลิเคชันการปรับแต่ง โดยค่าเริ่มต้น โปรแกรมการปรับจะสร้างไฟล์น้ำหนักโมเดล 20 ไฟล์ โดยสร้าง 1 ไฟล์สำหรับการปรับแต่ละยุค แต่ละยุคการปรับแต่งที่ตามมาจะสร้างน้ำหนักที่จำลองผลลัพธ์ของข้อมูลการปรับแต่งได้แม่นยำยิ่งขึ้น คุณดูอัตราความแม่นยำของแต่ละยุคได้ในเอาต์พุตเทอร์มินัลของกระบวนการปรับแต่ง ดังนี้
...
Epoch 14/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 567ms/step - loss: 0.4026 - sparse_categorical_accuracy: 0.8235
Epoch 15/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 569ms/step - loss: 0.3659 - sparse_categorical_accuracy: 0.8382
Epoch 16/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 571ms/step - loss: 0.3314 - sparse_categorical_accuracy: 0.8538
Epoch 17/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 572ms/step - loss: 0.2996 - sparse_categorical_accuracy: 0.8686
Epoch 18/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 574ms/step - loss: 0.2710 - sparse_categorical_accuracy: 0.8801
Epoch 19/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2451 - sparse_categorical_accuracy: 0.8903
Epoch 20/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2212 - sparse_categorical_accuracy: 0.9021
แม้ว่าคุณต้องการให้อัตราความแม่นยำค่อนข้างสูงประมาณ 0.80 ถึง 0.90 แต่ก็ไม่ต้องการให้อัตรานี้สูงเกินไปหรือใกล้เคียงกับ 1.00 เนื่องจากหมายความว่าน้ำหนักเกือบจะพอดีกับข้อมูลการปรับแต่งแล้ว ในกรณีนี้ โมเดลจะทํางานได้ไม่ดีกับคําขอที่แตกต่างจากตัวอย่างการปรับแต่งอย่างมาก โดยค่าเริ่มต้น สคริปต์การทําให้ใช้งานได้จะเลือกน้ำหนักของยุค 17 ซึ่งโดยทั่วไปมีอัตราความแม่นยําประมาณ 0.90
หากต้องการติดตั้งใช้งานน้ำหนักที่สร้างขึ้นกับเว็บแอปพลิเคชัน ให้ทำดังนี้
ในหน้าต่างเทอร์มินัล ให้ไปยังไดเรกทอรี
k-gemma-it/cd spoken-language-tasks/k-gemma-it/เรียกใช้กระบวนการปรับโดยใช้สคริปต์
deploy_weights./deploy_weights.sh
หลังจากเรียกใช้สคริปต์นี้ คุณควรเห็นไฟล์ *.h5 ใหม่ในไดเรกทอรี k-mail-replier/k_mail_replier/weights/
ทดสอบรูปแบบใหม่
เมื่อติดตั้งใช้งานน้ำหนักใหม่ในแอปพลิเคชันแล้ว ก็ถึงเวลาลองใช้รูปแบบที่ปรับแต่งใหม่ ซึ่งทำได้โดยเรียกใช้เว็บแอปพลิเคชันอีกครั้งและสร้างการตอบกลับ
วิธีเรียกใช้และทดสอบโปรเจ็กต์
ในหน้าต่างเทอร์มินัล ให้ไปที่ไดเรกทอรี
/k_mail_replier/cd spoken-language-tasks/k-mail-replier/เรียกใช้แอปพลิเคชันโดยใช้สคริปต์
run_flask_app.sh./run_flask_app.shหลังจากเริ่มเว็บแอปพลิเคชันแล้ว โค้ดโปรแกรมจะแสดง URL ที่คุณเรียกดูและทดสอบได้ โดยปกติแล้วที่อยู่นี้จะเป็น
http://127.0.0.1:5000/ในเว็บอินเทอร์เฟซ ให้กดปุ่ม 답변 작성 ใต้ช่องป้อนข้อมูลแรกเพื่อสร้างคำตอบจากโมเดล
ตอนนี้คุณปรับแต่งและติดตั้งใช้งานโมเดล Gemma ในแอปพลิเคชันแล้ว ทดสอบแอปพลิเคชันและพยายามระบุขีดจำกัดของความสามารถในการสร้างของโมเดลที่ปรับแต่งสำหรับงานของคุณ หากพบสถานการณ์ที่โมเดลทำงานได้ไม่ดี ให้ลองเพิ่มคำขอดังกล่าวลงในรายการข้อมูลตัวอย่างการปรับแต่งโดยการเพิ่มคำขอนั้นและให้การตอบสนองที่ดีที่สุด จากนั้นเรียกใช้กระบวนการปรับแต่งอีกครั้ง ติดตั้งใช้งานน้ำหนักใหม่อีกครั้ง และทดสอบเอาต์พุต
แหล่งข้อมูลเพิ่มเติม
ดูข้อมูลเพิ่มเติมเกี่ยวกับโปรเจ็กต์นี้ได้ที่ที่เก็บโค้ด Gemma Cookbook หากต้องการความช่วยเหลือในการสร้างแอปพลิเคชันหรือต้องการทำงานร่วมกับนักพัฒนาแอปคนอื่นๆ โปรดไปที่เซิร์ฟเวอร์ Discord ของชุมชนนักพัฒนาแอป Google ดูโปรเจ็กต์อื่นๆ ที่สร้างด้วย AI ของ Google ได้ที่เพลย์ลิสต์วิดีโอ