
El uso de la tecnología de inteligencia artificial (IA) en un idioma hablado específico es una necesidad fundamental para que muchas empresas puedan usarla de manera eficaz. La familia de modelos Gemma tiene algunas capacidades multilingües, pero usarlo en idiomas distintos del inglés suele producir resultados poco ideales.
Por suerte, no necesitas enseñarle a Gemma un idioma hablado completo para poder completar tareas en ese idioma. Además, puedes ajustar los modelos de Gemma para completar tareas específicas en un lenguaje con muchos menos datos y esfuerzo de lo que crees. Con unos 20 ejemplos de solicitudes y respuestas esperadas en tu idioma de destino, puedes hacer que Gemma te ayude a resolver muchos problemas comerciales diferentes en el idioma que mejor te sirva a ti y a tus clientes.
Para obtener una descripción general en video del proyecto y cómo ampliarlo, incluidas las estadísticas de las personas que lo compilan, mira el video de Compilar con Google AI: Asistente de IA de lenguaje hablado. También puedes revisar el código de este proyecto en el repositorio de código de Gemma Cookbook. De lo contrario, puedes comenzar a extender el proyecto con las siguientes instrucciones.
Descripción general
En este instructivo, se explica cómo configurar, ejecutar y extender una aplicación de tareas de lenguaje hablado compilada con Gemma y Python. La aplicación proporciona una interfaz de usuario web básica que puedes modificar para adaptarla a tus necesidades. La aplicación se creó para generar respuestas a los correos electrónicos de los clientes de una panadería coreana ficticia, y toda la entrada y salida de lenguaje se maneja completamente en coreano. Puedes usar este patrón de aplicación con cualquier lenguaje y cualquier tarea empresarial que use entrada de texto y salida de texto.
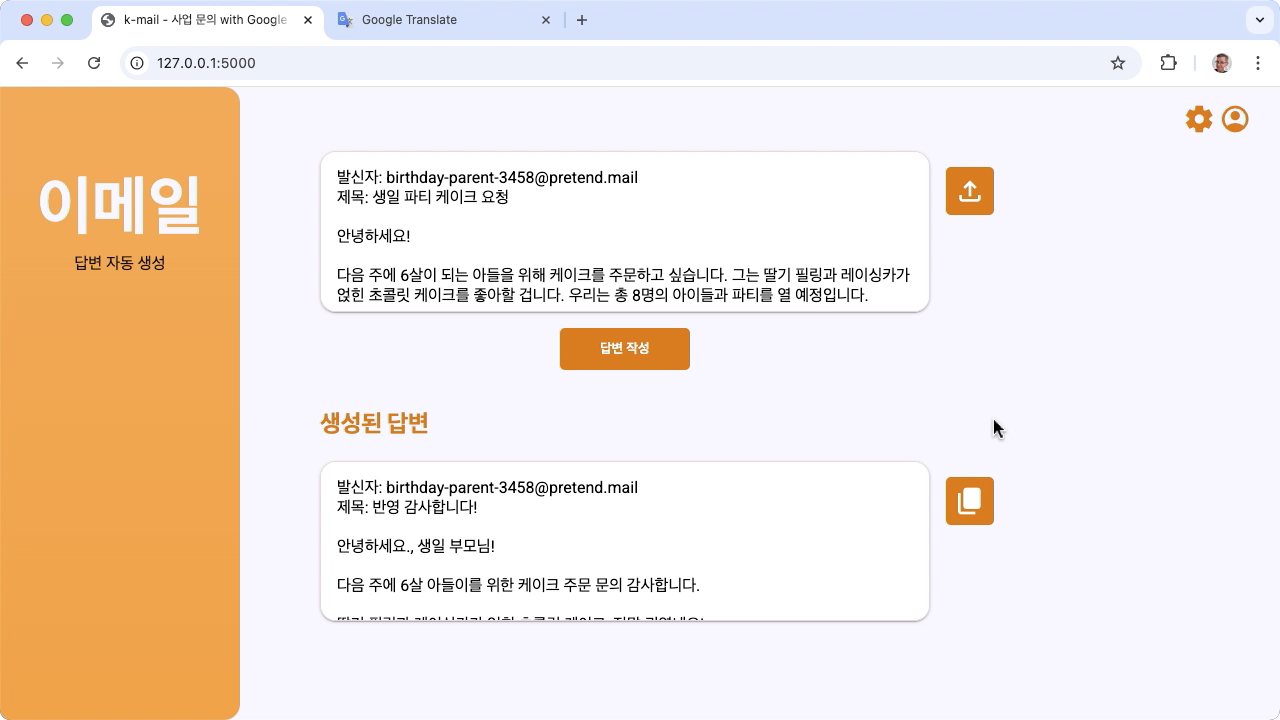
Figura 1: Interfaz de usuario del proyecto, para consultas por correo electrónico de la panadería coreana
Requisitos de hardware
Ejecuta este proceso de ajuste en una computadora con una unidad de procesamiento gráfico (GPU) o una unidad de procesamiento tensorial (TPU) y suficiente memoria para contener el modelo existente, además de los datos de ajuste. Para ejecutar la configuración de ajuste en este proyecto, necesitas alrededor de 16 GB de memoria de GPU, aproximadamente la misma cantidad de RAM normal y un mínimo de 50 GB de espacio en disco.
Puedes ejecutar la parte de este instructivo sobre el ajuste del modelo Gemma mediante un entorno de Colab con un entorno de ejecución de GPU T4. Si compilas este proyecto en una instancia de VM de Google Cloud, configúrala según estos requisitos:
- Hardware de GPU: Se requiere una NVIDIA T4 para ejecutar este proyecto y se recomienda una NVIDIA L4 o una versión posterior.
- Sistema operativo: Selecciona una opción de Aprendizaje profundo en Linux, específicamente la VM de Deep Learning con CUDA 12.3 M124 con controladores de software de GPU preinstalados.
- Tamaño del disco de arranque: Aprovisiona al menos 50 GB de espacio en el disco para tus datos, modelos y software de compatibilidad.
Configura el proyecto
Estas instrucciones te ayudarán a preparar este proyecto para el desarrollo y las pruebas. Los pasos de configuración generales incluyen instalar el software necesario, clonar el proyecto desde el repositorio de código, configurar algunas variables de entorno, instalar bibliotecas de Python y probar la aplicación web.
Instalación y configuración
Este proyecto usa Python 3 y entornos virtuales (venv) para administrar paquetes y ejecutar la aplicación. Las siguientes instrucciones de instalación son para una máquina anfitrión de Linux.
Para instalar el software necesario, sigue estos pasos:
Instala Python 3 y el paquete de entorno virtual
venvpara Python.sudo apt update sudo apt install git pip python3-venv
Cómo clonar el proyecto
Descarga el código del proyecto en tu computadora de desarrollo. Necesitas el software de control de código fuente git para recuperar el código fuente del proyecto.
Para descargar el código del proyecto, sigue estos pasos:
Clona el repositorio de Git con el siguiente comando.
git clone https://github.com/google-gemini/gemma-cookbook.gitDe manera opcional, configura tu repositorio de Git local para usar el resultado disperso de la confirmación de la compra, de modo que solo tengas los archivos del proyecto.
cd gemma-cookbook/ git sparse-checkout set Demos/spoken-language-tasks/ git sparse-checkout init --cone
Instala bibliotecas de Python
Instala las bibliotecas de Python con el entorno virtual de Python venv activado para administrar los paquetes y las dependencias de Python. Asegúrate de activar el entorno virtual de Python antes de instalar las bibliotecas de Python con el instalador pip. Para obtener más información sobre el uso de entornos virtuales de Python, consulta la documentación de venv de Python.
Para instalar las bibliotecas de Python, sigue estos pasos:
En una ventana de terminal, navega al directorio
spoken-language-tasks:cd Demos/spoken-language-tasks/Configura y activa el entorno virtual (venv) de Python para este proyecto:
python3 -m venv venv source venv/bin/activateInstala las bibliotecas de Python necesarias para este proyecto con la secuencia de comandos
setup_python../setup_python.sh
Configure las variables de entorno
Configura algunas variables de entorno que son necesarias para permitir que se ejecute este proyecto de código, incluido un nombre de usuario y una clave de token de Kaggle. Debes tener una cuenta de
Kaggle y solicitar acceso a los modelos de Gemma para poder descargarlos. Para este proyecto, agregas tu nombre de usuario y clave de token de Kaggle a dos archivos .env, que leen la aplicación web y el programa de ajuste, respectivamente.
Para configurar las variables de entorno, sigue estos pasos:
- Para obtener tu nombre de usuario y clave de token de Kaggle, sigue las instrucciones de la documentación de Kaggle.
- Para acceder al modelo de Gemma, sigue las instrucciones de Obtén acceso a Gemma en la página Configuración de Gemma.
- Crea archivos de variables de entorno para el proyecto. Para ello, crea un archivo de texto
.enven cada una de estas ubicaciones en la clonación del proyecto:k-mail-replier/k_mail_replier/.env k-gemma-it/.env
Después de crear los archivos de texto
.env, agrega la siguiente configuración a ambos archivos:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Ejecuta y prueba la aplicación
Una vez que hayas completado la instalación y configuración del proyecto, ejecuta la aplicación web para confirmar que la configuraste correctamente. Debes hacerlo como una verificación de referencia antes de editar el proyecto para tu propio uso.
Para ejecutar y probar el proyecto, haz lo siguiente:
En una ventana de terminal, navega al directorio
/k_mail_replier/:cd spoken-language-tasks/k-mail-replier/Ejecuta la aplicación con la secuencia de comandos
run_flask_app.sh:./run_flask_app.shDespués de iniciar la aplicación web, el código del programa muestra una URL en la que puedes explorar y probar. Por lo general, esta dirección es la siguiente:
http://127.0.0.1:5000/En la interfaz web, presiona el botón 답변 작성 debajo del primer campo de entrada para generar una respuesta del modelo.
La primera respuesta del modelo después de ejecutar la aplicación tarda más, ya que debe completar los pasos de inicialización en la primera ejecución de generación. Las solicitudes y generaciones de instrucciones posteriores en una aplicación web que ya se está ejecutando se completan en menos tiempo.
Extiende la aplicación
Una vez que tengas la aplicación en ejecución, puedes extenderla modificando la interfaz de usuario y la lógica empresarial para que funcione en tareas que sean relevantes para ti o tu empresa. También puedes modificar el comportamiento del modelo de Gemma con el código de la aplicación. Para ello, cambia los componentes de la instrucción que la app envía al modelo de IA generativa.
La aplicación proporciona instrucciones al modelo y los datos de entrada del usuario una instrucción completa del modelo. Puedes modificar estas instrucciones para cambiar el comportamiento del modelo, por ejemplo, especificar que el modelo debe extraer información de la solicitud y colocarla en formato de datos estructurados, como JSON. Una forma más sencilla de cambiar el comportamiento del modelo es proporcionar instrucciones o orientación adicionales para la respuesta del modelo, como especificar que las respuestas generadas deben escribirse en un tono educado.
Para modificar las instrucciones de los mensajes, haz lo siguiente:
- En el proyecto de tarea de lenguaje hablado, abre el archivo de código
k-mail-replier/k_mail_replier/app.py. En el código
app.py, agrega instrucciones de adición a la funciónget_prompt()::def get_prompt(): return "발신자에게 요청에 대한 감사를 전하고, 곧 자세한 내용을 알려드리겠다고 정중하게 답장해 주세요. 정중하게 답변해 주세요!:\n"
En este ejemplo, se agrega la frase “Escribe una respuesta educada” a las instrucciones en coreano.
Proporcionar instrucciones adicionales puede influir mucho en el resultado generado y requiere mucho menos esfuerzo para implementarse. Primero, debes probar este método para ver si puedes obtener el comportamiento que deseas del modelo. Sin embargo, usar instrucciones de instrucciones para modificar el comportamiento de un modelo de Gemma tiene sus límites. En particular, el límite general de tokens de entrada del modelo, que es de 8,192 tokens para Gemma 2, requiere que equilibres las instrucciones detalladas de la instrucción con el tamaño de los datos nuevos que proporcionas para que no superes ese límite.
Además, cuando quieras que Gemma realice tareas en un idioma que no sea el inglés, es probable que simplemente solicitar el modelo de base no genere resultados útiles de manera confiable. En cambio, debes ajustar el modelo con ejemplos en el idioma objetivo y, luego, considera modificar las instrucciones de las instrucciones para realizar ajustes más pequeños en la salida del modelo ajustado.
Ajusta el modelo
La forma recomendada de lograr que un modelo de Gemma responda de manera eficaz en un idioma hablado que no sea inglés es realizar un ajuste fino. Sin embargo, no es necesario que tengas fluidez total en el idioma de destino para que el modelo pueda completar tareas en ese idioma. Puedes lograr una funcionalidad básica en tu idioma de destino para una tarea con alrededor de 20 ejemplos. En esta sección del instructivo, se explica cómo configurar y ejecutar el ajuste fino en un modelo de Gemma para una tarea específica, en un idioma específico.
En las siguientes instrucciones, se explica cómo realizar la operación de ajuste en un entorno de VM. Sin embargo, también puedes realizar esta operación con el notebook de Colab asociado a este proyecto.
Requisitos de hardware
Los requisitos de procesamiento para el ajuste fino son los mismos que los requisitos de hardware para el resto del proyecto. Puedes ejecutar la operación de ajuste en un entorno de Colab con un entorno de ejecución de GPU T4 si limitas los tokens de entrada a 256 y el tamaño del lote a 1.
Preparar los datos
Antes de comenzar a ajustar un modelo de Gemma, debes preparar los datos para el ajuste. Cuando ajustas un modelo para una tarea y un idioma específicos, necesitas un conjunto de ejemplos de solicitudes y respuestas en ese idioma de destino. En estos ejemplos, se debe mostrar el texto de la solicitud, sin instrucciones, y el texto de la respuesta esperada. Para empezar, debes preparar un conjunto de datos con unos 20 ejemplos. Estos ejemplos deben representar una variedad completa de solicitudes y las respuestas ideales. Asegúrate de que las solicitudes y respuestas no sean repetitivas, ya que eso puede hacer que las respuestas de los modelos sean repetitivas y no se ajusten de forma adecuada a las variaciones en las solicitudes. En la siguiente tabla, se muestran algunos registros de muestra del conjunto de datos de este ejemplo de código:
| Solicitud | Respuesta |
|---|---|
| ⩍녕이크 3더 뒤 있사 아이 생할까 3 | 고객님, 안녕하세요. 2주 뒤 아이 생일 축하를 위해 3호 케이크 2개를 주문하고 싶습니다. 네, 3호 케이크 2개 주문 가능합니다. 아이 생일 케이크인 만큼 더욱 신경 써서 정성껏 준비하겠습니다. 혹시 원하시는 디자인이나 특별한 요청 사항이 있으시면 편하게 말씀해주세요. 픽업 날짜와 시간을 알려주시면 더욱 자세한 안내를 도와드리겠습니다. maps 多첈 문ั 감사장이며, 아이 생 장심장 line 축 potente instrumentos [GFLT림] |
| 안녕하세요, 9월 15일에 있을 아들의 돌잔치를 위해 케이크를 주문하고 싶습니다. - 케이크 종류: 생크림 케이크 - 크기: 2호 - 디자인: 아기자기한 동물 디자인 - 문구: "첫 생일 축하해, 사랑하는 아들!" - 픽업 날짜 및 시간: 9월 14일 오후 3시 가격 및 주문 가능 여부를 알려주시면 감사하겠습니다. 감사합니다. 김 り림 | 안녕하세요, 김민지 님, 9월 15일 아드님의 돌잔치를 위한 케이크 주문 문의 감사합니다. - 생크림 케이크 2호, 아기자기한 동물 디자인, "첫 생일 축하해, 사랑하는 아들!" 문, 9월 14improve Close후 3 픽업 사두 능장장. - 가격은 5만원입니다. ⩍문장 헰면 연락 감사장니ト. [가게 이름] 드림 |
Tabla 1: Lista parcial del conjunto de datos de ajuste para la respuesta de correo electrónico de panadería coreana.
Formato y carga de datos
Puedes almacenar tus datos de ajuste en cualquier formato que te resulte conveniente, incluidos registros de bases de datos, archivos JSON, CSV o archivos de texto sin formato, siempre que tengas los medios para recuperar los registros con código de Python. Para mayor comodidad, el programa de ajuste de ejemplo obtiene los registros de un repositorio en línea.
En este ejemplo de programa de ajuste, el conjunto de datos de ajuste se carga en el módulo k-gemma-it/main.py con la función prepare_tuning_dataset():
def prepare_tuning_dataset():
tokenizer = keras_nlp.models.GemmaTokenizer.from_preset(model_id)
# load data from repository (or local directory)
from datasets import load_dataset
ds = load_dataset(
# Dataset : https://huggingface.co/datasets/bebechien/korean_cake_boss
"bebechien/korean_cake_boss",
split="train",
)
...
Como se mencionó anteriormente, puedes almacenar el conjunto de datos en un formato conveniente, siempre que puedas recuperar las solicitudes con las respuestas asociadas y ensamblarlas en una cadena de texto que se use como registro de ajuste.
Cómo ensamblar registros de ajuste
Para el proceso de ajuste real, cada solicitud y respuesta se ensambla en una sola cadena con las instrucciones y etiquetas de solicitud para indicar el contenido de la solicitud y la respuesta. Luego, este programa de ajuste asigna tokens a la cadena para que el modelo la consuma. Puedes ver el código para ensamblar un registro de ajuste en la función prepare_tuning_dataset() del módulo k-gemma-it/main.py, de la siguiente manera:
def prepare_tuning_dataset():
...
prompt_instruction = "다음에 대한 이메일 답장을 작성해줘."
for x in data:
item = f"<start_of_turn>user\n{prompt_instruction}\n\"{x['input']}\"<end_of_turn>\n<start_of_turn>model\n{x['output']}<end_of_turn>"
length = len(tokenizer(item))
# skip data if the token length is longer than our limit
if length < token_limit:
tuning_dataset.append(item)
if(len(tuning_dataset)>=num_data_limit):
break
...
Esta función lee los datos y les aplica formato agregando etiquetas start_of_turn y end_of_turn, que es el formato requerido cuando se proporcionan datos para ajustar un modelo de Gemma. Este código también inserta un prompt_instruction para cada solicitud, que debes editar según corresponda para tu aplicación.
Genera pesos del modelo
Una vez que tengas los datos de ajuste en su lugar y se estén cargando, puedes ejecutar el programa de ajuste. El proceso de ajuste de esta aplicación de ejemplo usa la biblioteca de NLP de Keras para ajustar el modelo con una adaptación de rango bajo, o técnica LoRA, para generar nuevos pesos del modelo. En comparación con el ajuste de precisión completa, el uso de LoRA es mucho más eficiente en cuanto a la memoria porque se aproxima a los cambios en los pesos del modelo. Luego, puedes superponer estos pesos aproximados en los pesos del modelo existente para cambiar su comportamiento.
Para realizar la ejecución del ajuste y calcular los pesos nuevos, haz lo siguiente:
En una ventana de terminal, navega al directorio
k-gemma-it/.cd spoken-language-tasks/k-gemma-it/Ejecuta el proceso de ajuste con la secuencia de comandos
tune_model:./tune_model.sh
El proceso de ajuste tarda varios minutos según los recursos de procesamiento disponibles. Cuando se completa correctamente, el programa de ajuste escribe nuevos archivos de peso *.h5 en el directorio k-gemma-it/weights con el siguiente formato:
gemma2-2b_k-tuned_4_epoch##.lora.h5
Solución de problemas
Si el ajuste no se completa correctamente, es posible que se deba a uno de los siguientes motivos:
- Memoria insuficiente o recursos agotados: Estos errores se producen cuando el proceso de ajuste solicita memoria que supera la memoria disponible de la GPU o de la CPU. Asegúrate de no ejecutar la aplicación web mientras se ejecuta el proceso de ajuste. Si realizas el ajuste en un dispositivo con 16 GB de memoria GPU, asegúrate de configurar el
token_limiten 256 y elbatch_sizeen 1. - Los controladores de GPU no están instalados o son incompatibles con JAX: El proceso de conversión requiere que el dispositivo de procesamiento tenga instalados controladores de hardware compatibles con la versión de las bibliotecas de JAX. Para obtener más detalles, consulta la documentación sobre la instalación de JAX.
Implementa el modelo ajustado
El proceso de ajuste genera varias ponderaciones según los datos de ajuste y la cantidad total de épocas establecidas en la aplicación de ajuste. De forma predeterminada, el programa de ajuste genera 20 archivos de peso del modelo, uno para cada época de ajuste. Cada época de ajuste sucesiva produce pesos que reproducen con mayor precisión los resultados de los datos de ajuste. Puedes ver las tasas de precisión de cada época en el resultado de la terminal del proceso de ajuste, como se indica a continuación:
...
Epoch 14/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 567ms/step - loss: 0.4026 - sparse_categorical_accuracy: 0.8235
Epoch 15/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 569ms/step - loss: 0.3659 - sparse_categorical_accuracy: 0.8382
Epoch 16/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 571ms/step - loss: 0.3314 - sparse_categorical_accuracy: 0.8538
Epoch 17/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 572ms/step - loss: 0.2996 - sparse_categorical_accuracy: 0.8686
Epoch 18/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 574ms/step - loss: 0.2710 - sparse_categorical_accuracy: 0.8801
Epoch 19/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2451 - sparse_categorical_accuracy: 0.8903
Epoch 20/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2212 - sparse_categorical_accuracy: 0.9021
Si bien deseas que la tasa de precisión sea relativamente alta, de alrededor de 0.80 a 0.90, no querrás que sea demasiado alta o muy cercana a 1.00, ya que eso significa que los pesos se acercaron al sobreajuste de los datos de ajuste. Cuando eso sucede, el modelo no tiene un buen rendimiento en las solicitudes que son muy diferentes de los ejemplos de ajuste. De forma predeterminada, la secuencia de comandos de implementación elige los pesos de la época 17, que suelen tener una tasa de precisión de alrededor de 0.90.
Para implementar las ponderaciones generadas en la aplicación web, haz lo siguiente:
En una ventana de terminal, navega al directorio
k-gemma-it/.cd spoken-language-tasks/k-gemma-it/Ejecuta el proceso de ajuste con la secuencia de comandos
deploy_weights:./deploy_weights.sh
Después de ejecutar esta secuencia de comandos, deberías ver un archivo *.h5 nuevo en el directorio k-mail-replier/k_mail_replier/weights/.
Prueba el modelo nuevo
Una vez que hayas implementado las nuevas ponderaciones en la aplicación, es hora de probar el modelo ajustado. Para ello, vuelve a ejecutar la aplicación web y genera una respuesta.
Para ejecutar y probar el proyecto, haz lo siguiente:
En una ventana de terminal, navega al directorio
/k_mail_replier/.cd spoken-language-tasks/k-mail-replier/Ejecuta la aplicación con la secuencia de comandos
run_flask_app.sh:./run_flask_app.shDespués de iniciar la aplicación web, el código del programa muestra una URL en la que puedes explorar y probar. Esta dirección suele ser la siguiente:
http://127.0.0.1:5000/En la interfaz web, presiona el botón 답변 작성 debajo del primer campo de entrada para generar una respuesta del modelo.
Ya ajustaste e implementaste un modelo de Gemma en una aplicación. Experimenta con la aplicación y trata de determinar los límites de la capacidad de generación del modelo ajustado para tu tarea. Si encuentras situaciones en las que el modelo no tiene un buen rendimiento, considera agregar algunas de esas solicitudes a tu lista de datos de ejemplo de ajuste. Para ello, agrega la solicitud y proporciona una respuesta ideal. Luego, vuelve a ejecutar el proceso de ajuste, implementa las ponderaciones nuevas y prueba el resultado.
Recursos adicionales
Para obtener más información sobre este proyecto, consulta el repositorio de código de Gemma Cookbook. Si necesitas ayuda para compilar la aplicación o deseas colaborar con otros desarrolladores, consulta el servidor de Discord de la comunidad de Google Developers. Para ver más proyectos de Build with Google AI, consulta la playlist de videos.