
Использование технологии искусственного интеллекта (ИИ) на определенном разговорном языке является критической необходимостью для многих предприятий, чтобы иметь возможность эффективно использовать ее. Семейство моделей Gemma обладает некоторыми многоязычными возможностями, но использование его на языках, отличных от английского, часто дает далеко не идеальные результаты.
К счастью, вам не нужно учить Джемму всему разговорному языку, чтобы иметь возможность выполнять задания на этом языке. Более того, вы можете настроить модели Gemma для выполнения конкретных задач на языке, используя гораздо меньше данных и усилий, чем вы думаете. Используя около 20 примеров запросов и ожидаемых ответов на вашем целевом языке, вы можете заставить Gemma помочь вам решить множество различных бизнес-задач на языке, который лучше всего подходит вам и вашим клиентам.
Видео-обзор проекта и способы его расширения, включая идеи людей, которые его создают, можно посмотреть в видеоролике «Создание Spoken Language AI Assistant с помощью Google AI». Вы также можете просмотреть код этого проекта в репозитории кода Gemma Cookbook . В противном случае вы можете начать расширять проект, используя следующие инструкции.
Обзор
В этом руководстве вы узнаете, как настроить, запустить и расширить приложение для задач разговорного языка, созданное с помощью Gemma и Python. Приложение предоставляет базовый веб-интерфейс пользователя, который вы можете изменить в соответствии со своими потребностями. Приложение создано для генерации ответов на электронные письма клиентов вымышленной корейской пекарни, а весь ввод и вывод данных осуществляется полностью на корейском языке. Этот шаблон приложения можно использовать с любым языком и любой бизнес-задачой, использующей ввод и вывод текста.
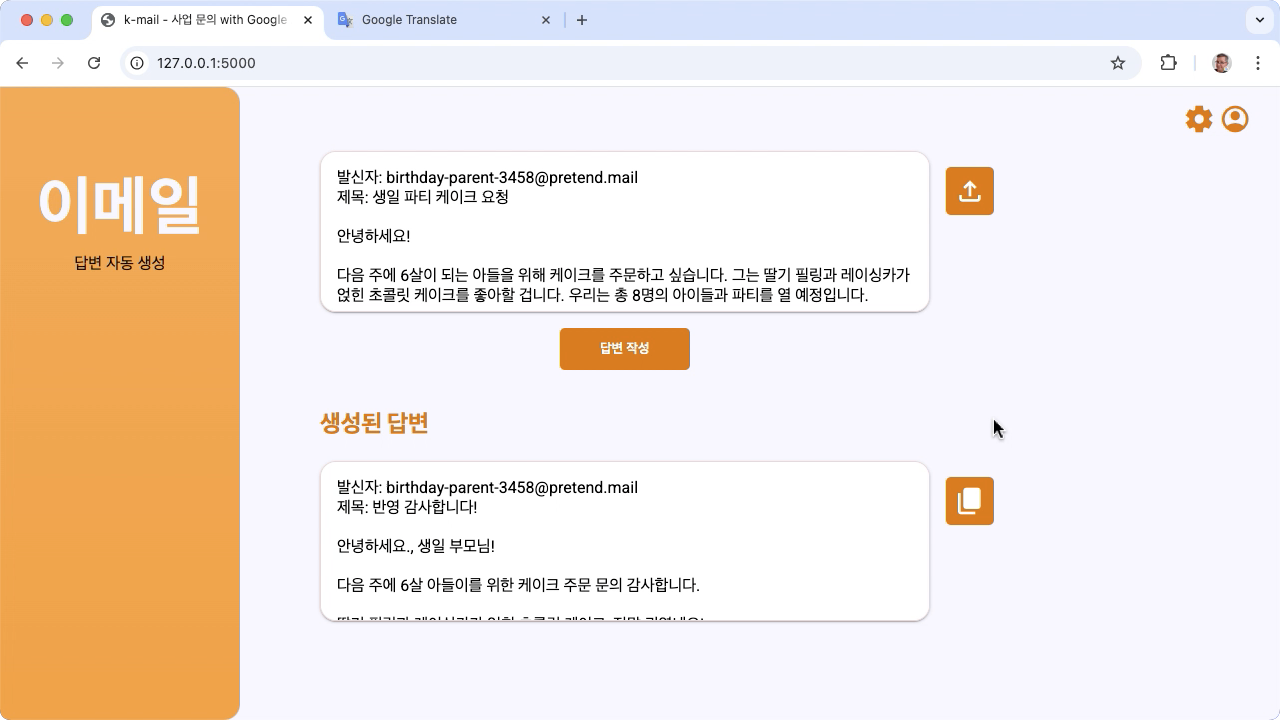
Рисунок 1. Пользовательский интерфейс проекта для запросов по электронной почте о корейских пекарнях.
Требования к оборудованию
Запустите этот процесс настройки на компьютере с графическим процессором (GPU) или тензорным процессором (TPU) и достаточным объемом памяти для хранения существующей модели, а также данных настройки. Для запуска конфигурации настройки в этом проекте вам потребуется около 16 ГБ памяти графического процессора, примерно такой же объем обычной оперативной памяти и минимум 50 ГБ дискового пространства.
Вы можете запустить часть этого руководства по настройке модели Gemma, используя среду Colab со средой выполнения T4 GPU . Если вы создаете этот проект на экземпляре виртуальной машины Google Cloud, настройте экземпляр в соответствии со следующими требованиями:
- Аппаратное обеспечение графического процессора : для запуска этого проекта требуется NVIDIA T4, рекомендуется NVIDIA L4 или выше.
- Операционная система : выберите вариант глубокого обучения в Linux , в частности, виртуальную машину глубокого обучения с CUDA 12.3 M124 с предустановленными программными драйверами графического процессора.
- Размер загрузочного диска : предоставьте не менее 50 ГБ дискового пространства для ваших данных, моделей и вспомогательного программного обеспечения.
Настройка проекта
Эти инструкции помогут вам подготовить проект к разработке и тестированию. Общие этапы установки включают установку необходимого программного обеспечения, клонирование проекта из репозитория кода, настройку нескольких переменных среды, установку библиотек Python и тестирование веб-приложения.
Установить и настроить
В этом проекте используется Python 3 и виртуальные среды ( venv ) для управления пакетами и запуска приложения. Следующие инструкции по установке предназначены для хост-компьютера Linux.
Чтобы установить необходимое программное обеспечение:
Установите Python 3 и пакет виртуальной среды
venvдля Python.sudo apt update sudo apt install git pip python3-venv
Клонировать проект
Загрузите код проекта на свой компьютер разработчика. Вам понадобится программное обеспечение для управления версиями git , чтобы получить исходный код проекта.
Чтобы скачать код проекта:
Клонируйте репозиторий git, используя следующую команду.
git clone https://github.com/google-gemini/gemma-cookbook.gitПри желании настройте свой локальный репозиторий git на использование разреженного извлечения, чтобы у вас были только файлы для проекта.
cd gemma-cookbook/ git sparse-checkout set Demos/spoken-language-tasks/ git sparse-checkout init --cone
Установите библиотеки Python
Установите библиотеки Python с активированной виртуальной средой Python venv для управления пакетами и зависимостями Python. Обязательно активируйте виртуальную среду Python перед установкой библиотек Python с помощью установщика pip . Дополнительные сведения об использовании виртуальных сред Python см. в документации Python venv .
Чтобы установить библиотеки Python:
В окне терминала перейдите в каталог
spoken-language-tasks:cd Demos/spoken-language-tasks/Настройте и активируйте виртуальную среду Python (venv) для этого проекта:
python3 -m venv venv source venv/bin/activateУстановите необходимые библиотеки Python для этого проекта с помощью сценария
setup_python../setup_python.sh
Установить переменные среды
Задайте несколько переменных среды, которые необходимы для запуска этого проекта кода, включая имя пользователя Kaggle и ключ токена Kaggle. У вас должна быть учетная запись Kaggle и запросить доступ к моделям Gemma, чтобы иметь возможность их загрузить. В этом проекте вы добавляете свое имя пользователя Kaggle и ключ токена Kaggle в два файла .env , которые считываются веб-приложением и программой настройки соответственно.
Чтобы установить переменные среды:
- Получите свое имя пользователя Kaggle и ключ токена, следуя инструкциям в документации Kaggle .
- Получите доступ к модели Gemma, следуя инструкциям «Получить доступ к Gemma» на странице настройки Gemma .
- Создайте файлы переменных среды для проекта, создав текстовый файл
.envв каждом из этих мест клона проекта:k-mail-replier/k_mail_replier/.env k-gemma-it/.env
После создания текстовых файлов
.envдобавьте в оба файла следующие настройки:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Запустите и протестируйте приложение
После завершения установки и настройки проекта запустите веб-приложение, чтобы убедиться, что вы настроили его правильно. Вам следует сделать это в качестве базовой проверки перед редактированием проекта для собственного использования.
Чтобы запустить и протестировать проект:
В окне терминала перейдите в каталог
/k_mail_replier/:cd spoken-language-tasks/k-mail-replier/Запустите приложение с помощью скрипта
run_flask_app.sh:./run_flask_app.shПосле запуска веб-приложения в программном коде указан URL-адрес, по которому вы можете просмотреть и протестировать. Обычно это адрес:
http://127.0.0.1:5000/В веб-интерфейсе нажмите кнопку «Добавить» под первым полем ввода, чтобы сгенерировать ответ модели.
Первый ответ модели после запуска приложения занимает больше времени, поскольку он должен выполнить шаги инициализации при первом запуске поколения. Последующие запросы и генерация в уже работающем веб-приложении выполняются за меньшее время.
Расширить приложение
После запуска приложения вы можете расширить его, изменив пользовательский интерфейс и бизнес-логику, чтобы оно работало для задач, которые актуальны для вас или вашего бизнеса. Вы также можете изменить поведение модели Gemma с помощью кода приложения, изменив компоненты приглашения, которое приложение отправляет генеративной модели ИИ.
Приложение предоставляет инструкции модели вместе с входными данными от пользователя и полную подсказку модели. Вы можете изменить эти инструкции, чтобы изменить поведение модели, например, указав, что модель должна извлекать информацию из запроса и помещать ее в формат структурированных данных, например JSON. Более простой способ изменить поведение модели — предоставить дополнительные инструкции или рекомендации для ответа модели, например указать, что сгенерированные ответы должны быть написаны вежливым тоном.
Чтобы изменить подсказки:
- В проекте разговорной речи откройте файл кода
k-mail-replier/k_mail_replier/app.py. В коде
app.pyдобавьте дополнительные инструкции в функциюget_prompt():::def get_prompt(): return "발신자에게 요청에 대한 감사를 전하고, 곧 자세한 내용을 알려드리겠다고 정중하게 답장해 주세요. 정중하게 답변해 주세요!:\n"
В этом примере добавляется фраза «Пожалуйста, напишите вежливый ответ!» к инструкции на корейском языке.
Предоставление дополнительных подсказок может сильно повлиять на генерируемый результат и требует значительно меньше усилий для реализации. Сначала вам следует попробовать этот метод, чтобы увидеть, сможете ли вы получить от модели желаемое поведение. Однако использование подсказок для изменения поведения модели Gemma имеет свои ограничения. В частности, общий лимит входных токенов модели, который составляет 8 192 токена для Gemma 2, требует от вас сбалансировать подробные инструкции подсказок с размером новых данных, которые вы предоставляете, чтобы вы оставались в пределах этого ограничения.
Более того, если вы хотите, чтобы Gemma выполняла задачи на языке, отличном от английского, простой запрос базовой модели вряд ли даст надежные полезные результаты. Вместо этого вам следует настроить модель с помощью примеров на целевом языке, а затем рассмотреть возможность изменения инструкций подсказки, чтобы внести небольшие изменения в выходные данные настроенной модели.
Настройте модель
Выполнение тонкой настройки модели Gemma — рекомендуемый способ заставить ее эффективно реагировать на разговорном языке, отличном от английского. Однако вам не обязательно стремиться к полному владению целевым языком, чтобы модель могла выполнять задачи на этом языке. Вы можете достичь базовой функциональности на целевом языке для задачи, используя около 20 примеров. В этом разделе руководства объясняется, как настроить и выполнить тонкую настройку модели Gemma для конкретной задачи на определенном языке.
Следующие инструкции объясняют, как выполнить операцию тонкой настройки в среде виртуальной машины, однако вы также можете выполнить эту операцию настройки с помощью связанного блокнота Colab для этого проекта.
Требования к оборудованию
Требования к вычислительным ресурсам для тонкой настройки такие же, как и к аппаратному обеспечению для остальной части проекта. Вы можете запустить операцию настройки в среде Colab со средой выполнения T4 GPU , если ограничите количество входных токенов до 256, а размер пакета — до 1.
Подготовьте данные
Прежде чем приступить к настройке модели Gemma, необходимо подготовить данные для настройки. Когда вы настраиваете модель для конкретной задачи и языка, вам нужен набор примеров запросов и ответов на этом целевом языке. В этих примерах должен быть показан текст запроса без каких-либо инструкций и текст ожидаемого ответа. Для начала вам следует подготовить набор данных примерно из 20 примеров. Эти примеры должны отражать все разнообразие запросов и идеальные ответы. Убедитесь, что запросы и ответы не повторяются, так как это может привести к повторению ответов моделей и невозможности соответствующей адаптации к изменениям в запросах. В следующей таблице показаны несколько примеров записей из набора данных этого примера кода:
| Запрос | Ответ |
|---|---|
| 안녕하세요, 2 주 뒤에 아이 생일을 위해 3 호 케이크 3 개를 주문하고 싶은데 가능할까요? | 고객님, 안녕하세요. 2-й раз и 3-й раз нажмите 2-й раз, когда он будет готов. Например, 3 - 케이크 2개 주문 가능합니다. Если вы хотите, чтобы устройство было готово, оно должно быть готово. Когда вы начнете варить кофе, вы можете использовать его в качестве источника питания. Нажмите на кнопку «Получить» и нажмите кнопку «Получить». Если вы хотите, чтобы это произошло, вы можете сделать это! [가게 이름] 드림 |
| 안녕하세요, 9–15 дней в году, когда вы хотите, чтобы это произошло. - 케이크 종류: 생크림 케이크 - 크기: 2호 - 디자인: 아기자기한 동물 디자인 - 문구: "첫 생일 축 Вот, вот это да!» - Время проведения: 9 – 14 - 14 дней, 3 месяца и 9 – 14 лет, а затем 9 – 14 лет. . 감사합니다. 김민지 드림 | 안녕하세요, 김민지 님, 9-15 일 아드님의 돌잔치를 위한 케이크 주문 문의 감사합니다. - 생크림 케이크 2호, 아기자기한 동물 디자인, "첫 생일 축하해, 사랑하는 아들!" Например, 9–14 дней и 3 месяца, когда вы будете в восторге. - 가격은 5만원입니다. Нажмите на кнопку «Получить» и нажмите кнопку «Получить». [가게 이름] 드림 |
Таблица 1. Частичный список набора данных настройки для автоответчика корейской пекарни.
Формат данных и загрузка
Вы можете хранить данные настройки в любом удобном формате, включая записи базы данных, файлы JSON, CSV или обычные текстовые файлы, если у вас есть средства для извлечения записей с помощью кода Python. Для удобства пример программы настройки получает записи из онлайн-репозитория . В этом примере программы токарной обработки набор данных настройки загружается в модуль k-gemma-it/main.py с помощью prepare_tuning_dataset() :
def prepare_tuning_dataset():
tokenizer = keras_nlp.models.GemmaTokenizer.from_preset(model_id)
# load data from repository (or local directory)
from datasets import load_dataset
ds = load_dataset(
# Dataset : https://huggingface.co/datasets/bebechien/korean_cake_boss
"bebechien/korean_cake_boss",
split="train",
)
...
Как упоминалось ранее, вы можете хранить набор данных в удобном формате, при условии, что вы можете извлекать запросы со связанными ответами и собирать их в текстовую строку, которая используется в качестве записи настройки.
Собрать тюнинговые записи
Для фактического процесса настройки каждый запрос и ответ собираются в одну строку с подсказками и тегами, обозначающими содержимое запроса и содержание ответа. Затем эта программа настройки токенизирует строку для использования моделью. Посмотреть код сборки настроечной записи можно в функции prepare_tuning_dataset() модуля k-gemma-it/main.py следующим образом:
def prepare_tuning_dataset():
...
prompt_instruction = "다음에 대한 이메일 답장을 작성해줘."
for x in data:
item = f"<start_of_turn>user\n{prompt_instruction}\n\"{x['input']}\"<end_of_turn>\n<start_of_turn>model\n{x['output']}<end_of_turn>"
length = len(tokenizer(item))
# skip data if the token length is longer than our limit
if length < token_limit:
tuning_dataset.append(item)
if(len(tuning_dataset)>=num_data_limit):
break
...
Эта функция считывает данные и форматирует их, добавляя теги start_of_turn и end_of_turn , которые являются обязательным форматом при предоставлении данных для настройки модели Gemma. Этот код также вставляет prompt_instruction для каждого запроса, которую вам следует отредактировать в соответствии с вашим приложением.
Генерация весов модели
После того как данные настройки собраны и загружены, вы можете запустить программу настройки. Процесс настройки для этого примера приложения использует библиотеку Keras NLP для настройки модели с помощью метода адаптации низкого ранга или метода LoRA для создания новых весов модели. По сравнению с полной точной настройкой использование LoRA значительно более эффективно использует память, поскольку аппроксимирует изменения весов модели. Затем вы можете наложить эти приблизительные веса на существующие веса модели, чтобы изменить поведение модели.
Чтобы выполнить настройку и рассчитать новые веса:
В окне терминала перейдите в каталог
k-gemma-it/.cd spoken-language-tasks/k-gemma-it/Запустите процесс настройки с помощью скрипта
tune_model:./tune_model.sh
Процесс настройки занимает несколько минут в зависимости от доступных вычислительных ресурсов. После успешного завершения программа настройки записывает новые файлы весов *.h5 в каталог k-gemma-it/weights в следующем формате:
gemma2-2b_k-tuned_4_epoch##.lora.h5
Поиск неисправностей
Если настройка не завершилась успешно, возможны две причины:
- Недостаточно памяти/ресурсы исчерпаны . Эти ошибки возникают, когда процесс настройки запрашивает память, превышающую доступную память графического процессора или памяти процессора. Убедитесь, что вы не запускаете веб-приложение во время процесса настройки. Если вы настраиваете устройство с 16 ГБ памяти графического процессора, убедитесь, что для
token_limitустановлено значение 256 , аbatch_sizeустановлено значение 1 . - Драйверы графического процессора не установлены или несовместимы с JAX . Для процесса преобразования требуется, чтобы на вычислительном устройстве были установлены аппаратные драйверы, совместимые с версией библиотек JAX . Более подробную информацию см. в документации по установке JAX .
Развертывание настроенной модели
Процесс настройки генерирует несколько весов на основе данных настройки и общего количества эпох, установленных в приложении настройки. По умолчанию программа настройки генерирует 20 файлов веса модели, по одному для каждой эпохи настройки. Каждая последующая эпоха настройки создает веса, которые более точно воспроизводят результаты данных настройки. Вы можете увидеть показатели точности для каждой эпохи в выходных данных терминала процесса настройки следующим образом:
...
Epoch 14/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 567ms/step - loss: 0.4026 - sparse_categorical_accuracy: 0.8235
Epoch 15/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 569ms/step - loss: 0.3659 - sparse_categorical_accuracy: 0.8382
Epoch 16/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 571ms/step - loss: 0.3314 - sparse_categorical_accuracy: 0.8538
Epoch 17/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 572ms/step - loss: 0.2996 - sparse_categorical_accuracy: 0.8686
Epoch 18/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 574ms/step - loss: 0.2710 - sparse_categorical_accuracy: 0.8801
Epoch 19/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2451 - sparse_categorical_accuracy: 0.8903
Epoch 20/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2212 - sparse_categorical_accuracy: 0.9021
Хотя вы хотите, чтобы коэффициент точности был относительно высоким, примерно от 0,80 до 0,90, вы не хотите, чтобы показатель был слишком высоким или очень близким к 1,00, поскольку это означает, что веса приблизились к переобучению данных настройки. Когда это происходит, модель плохо работает с запросами, которые существенно отличаются от примеров настройки. По умолчанию сценарий развертывания выбирает веса эпохи 17, которые обычно имеют точность около 0,90.
Чтобы развернуть сгенерированные веса в веб-приложении:
В окне терминала перейдите в каталог
k-gemma-it/.cd spoken-language-tasks/k-gemma-it/Запустите процесс настройки с помощью скрипта
deploy_weights:./deploy_weights.sh
После запуска этого сценария вы должны увидеть новый файл *.h5 в каталоге k-mail-replier/k_mail_replier/weights/ .
Протестируйте новую модель
После того как вы внедрили новые веса в приложение, пришло время опробовать недавно настроенную модель. Это можно сделать, перезапустив веб-приложение и сгенерировав ответ.
Чтобы запустить и протестировать проект:
В окне терминала перейдите в каталог
/k_mail_replier/.cd spoken-language-tasks/k-mail-replier/Запустите приложение с помощью скрипта
run_flask_app.sh:./run_flask_app.shПосле запуска веб-приложения в программном коде указан URL-адрес, по которому вы можете просмотреть и протестировать, обычно это адрес:
http://127.0.0.1:5000/В веб-интерфейсе нажмите кнопку «Добавить» под первым полем ввода, чтобы сгенерировать ответ модели.
Теперь вы настроили и развернули модель Gemma в приложении! Поэкспериментируйте с приложением и попытайтесь определить пределы возможностей генерации настроенной модели для вашей задачи. Если вы обнаружите сценарии, в которых модель работает не очень хорошо, рассмотрите возможность добавления некоторых из этих запросов в список данных примера настройки, добавив запрос и предоставив идеальный ответ. Затем повторно запустите процесс настройки, повторно примените новые веса и протестируйте выходные данные.
Дополнительные ресурсы
Дополнительную информацию об этом проекте можно найти в репозитории кода Gemma Cookbook . Если вам нужна помощь в создании приложения или вы хотите сотрудничать с другими разработчиками, посетите сервер Discord сообщества разработчиков Google . Дополнительные сведения о проектах Build with Google AI можно найти в плейлисте видео .