
MediaPipe 동작 인식기 태스크를 사용하면 손 동작을 실시간으로 인식하고 감지된 손의 인식된 손 동작 결과와 손 랜드마크를 제공할 수 있습니다. 이 안내에서는 Android 앱에서 동작 감지기를 사용하는 방법을 보여줍니다. 이 안내에 설명된 코드 샘플은 GitHub에서 확인할 수 있습니다.
웹 데모를 보면서 이 작업이 작동하는 모습을 확인할 수 있습니다. 이 태스크의 기능, 모델, 구성 옵션에 관한 자세한 내용은 개요를 참고하세요.
코드 예
MediaPipe Tasks 예시 코드는 Android용 동작 감지기 앱의 간단한 구현입니다. 이 예에서는 실제 Android 기기의 카메라를 사용하여 손 동작을 연속적으로 감지하고 기기 갤러리의 이미지와 동영상을 사용하여 동작을 정적으로 감지할 수도 있습니다.
이 앱을 자체 Android 앱의 시작점으로 사용하거나 기존 앱을 수정할 때 참고할 수 있습니다. 동작 감지기 예시 코드는 GitHub에서 호스팅됩니다.
코드 다운로드
다음 안내에서는 git 명령줄 도구를 사용하여 예시 코드의 로컬 사본을 만드는 방법을 보여줍니다.
예시 코드를 다운로드하려면 다음 안내를 따르세요.
- 다음 명령어를 사용하여 git 저장소를 클론합니다.
git clone https://github.com/google-ai-edge/mediapipe-samples
- 원하는 경우 드문 삭제를 사용하도록 git 인스턴스를 구성하여 동작 감지기 예시 앱의 파일만 포함되도록 합니다.
cd mediapipe-samples git sparse-checkout init --cone git sparse-checkout set examples/gesture_recognizer/android
예시 코드의 로컬 버전을 만든 후 프로젝트를 Android 스튜디오로 가져와 앱을 실행할 수 있습니다. 안내는 Android용 설정 가이드를 참고하세요.
주요 구성요소
다음 파일에는 이 손동작 인식 예시 애플리케이션의 중요한 코드가 포함되어 있습니다.
- GestureRecognizerHelper.kt - 동작 인식자를 초기화하고 모델 및 위임 선택을 처리합니다.
- MainActivity.kt -
GestureRecognizerHelper및GestureRecognizerResultsAdapter호출을 비롯하여 애플리케이션을 구현합니다. - GestureRecognizerResultsAdapter.kt - 결과를 처리하고 형식을 지정합니다.
설정
이 섹션에서는 특히 동작 감지기를 사용하도록 개발 환경 및 코드 프로젝트를 설정하는 주요 단계를 설명합니다. 플랫폼 버전 요구사항을 비롯하여 MediaPipe 작업을 사용하기 위한 개발 환경 설정에 관한 일반적인 정보는 Android 설정 가이드를 참고하세요.
종속 항목
동작 인식기 작업은 com.google.mediapipe:tasks-vision 라이브러리를 사용합니다. Android 앱의 build.gradle 파일에 다음 종속 항목을 추가합니다.
dependencies {
implementation 'com.google.mediapipe:tasks-vision:latest.release'
}
모델
MediaPipe 동작 인식기 태스크에는 이 태스크와 호환되는 학습된 모델 번들이 필요합니다. 동작 감지기에 사용할 수 있는 학습된 모델에 관한 자세한 내용은 작업 개요 모델 섹션을 참고하세요.
모델을 선택하고 다운로드한 후 프로젝트 디렉터리 내에 저장합니다.
<dev-project-root>/src/main/assets
ModelAssetPath 매개변수 내에 모델의 경로를 지정합니다. 예시 코드에서 모델은 GestureRecognizerHelper.kt 파일에 정의되어 있습니다.
baseOptionBuilder.setModelAssetPath(MP_RECOGNIZER_TASK)
할 일 만들기
MediaPipe 동작 인식기 태스크는 createFromOptions() 함수를 사용하여 태스크를 설정합니다. createFromOptions() 함수는 구성 옵션의 값을 허용합니다. 구성 옵션에 관한 자세한 내용은 구성 옵션을 참고하세요.
동작 감지기는 정지 이미지, 동영상 파일, 실시간 동영상 스트림이라는 3가지 입력 데이터 유형을 지원합니다. 태스크를 만들 때 입력 데이터 유형에 해당하는 실행 모드를 지정해야 합니다. 입력 데이터 유형에 해당하는 탭을 선택하여 태스크를 만들고 추론을 실행하는 방법을 확인하세요.
이미지
val baseOptionsBuilder = BaseOptions.builder().setModelAssetPath(MP_RECOGNIZER_TASK)
val baseOptions = baseOptionBuilder.build()
val optionsBuilder =
GestureRecognizer.GestureRecognizerOptions.builder()
.setBaseOptions(baseOptions)
.setMinHandDetectionConfidence(minHandDetectionConfidence)
.setMinTrackingConfidence(minHandTrackingConfidence)
.setMinHandPresenceConfidence(minHandPresenceConfidence)
.setRunningMode(RunningMode.IMAGE)
val options = optionsBuilder.build()
gestureRecognizer =
GestureRecognizer.createFromOptions(context, options)
동영상
val baseOptionsBuilder = BaseOptions.builder().setModelAssetPath(MP_RECOGNIZER_TASK)
val baseOptions = baseOptionBuilder.build()
val optionsBuilder =
GestureRecognizer.GestureRecognizerOptions.builder()
.setBaseOptions(baseOptions)
.setMinHandDetectionConfidence(minHandDetectionConfidence)
.setMinTrackingConfidence(minHandTrackingConfidence)
.setMinHandPresenceConfidence(minHandPresenceConfidence)
.setRunningMode(RunningMode.VIDEO)
val options = optionsBuilder.build()
gestureRecognizer =
GestureRecognizer.createFromOptions(context, options)
실시간 스트림
val baseOptionsBuilder = BaseOptions.builder().setModelAssetPath(MP_RECOGNIZER_TASK)
val baseOptions = baseOptionBuilder.build()
val optionsBuilder =
GestureRecognizer.GestureRecognizerOptions.builder()
.setBaseOptions(baseOptions)
.setMinHandDetectionConfidence(minHandDetectionConfidence)
.setMinTrackingConfidence(minHandTrackingConfidence)
.setMinHandPresenceConfidence(minHandPresenceConfidence)
.setResultListener(this::returnLivestreamResult)
.setErrorListener(this::returnLivestreamError)
.setRunningMode(RunningMode.LIVE_STREAM)
val options = optionsBuilder.build()
gestureRecognizer =
GestureRecognizer.createFromOptions(context, options)
동작 감지기 예시 코드 구현을 사용하면 사용자가 처리 모드 간에 전환할 수 있습니다. 이 접근 방식을 사용하면 태스크 생성 코드가 더 복잡해지고 사용 사례에 적합하지 않을 수 있습니다. 이 코드는 GestureRecognizerHelper.kt 파일의 setupGestureRecognizer() 함수에서 확인할 수 있습니다.
구성 옵션
이 작업에는 Android 앱에 관한 다음과 같은 구성 옵션이 있습니다.
| 옵션 이름 | 설명 | 값 범위 | 기본값 | |
|---|---|---|---|---|
runningMode |
태스크의 실행 모드를 설정합니다. 모드는 세 가지입니다. IMAGE: 단일 이미지 입력의 모드입니다. 동영상: 동영상의 디코딩된 프레임 모드입니다. LIVE_STREAM: 카메라와 같은 입력 데이터의 라이브 스트림 모드입니다. 이 모드에서는 결과를 비동기식으로 수신할 리스너를 설정하려면 resultListener를 호출해야 합니다. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
|
numHands |
GestureRecognizer는 최대 GestureRecognizer개의 손을 감지할 수 있습니다.
|
Any integer > 0 |
1 |
|
minHandDetectionConfidence |
손바닥 감지 모델에서 손 감지가 성공으로 간주되기 위한 최소 신뢰도 점수입니다. | 0.0 - 1.0 |
0.5 |
|
minHandPresenceConfidence |
손 지형지물 감지 모델에서 손 존재 점수의 최소 신뢰도 점수입니다. 동작 인식기의 동영상 모드 및 라이브 스트림 모드에서 손 랜드마크 모델의 손 존재 신뢰도 점수가 이 기준점 미만이면 손바닥 감지 모델이 트리거됩니다. 그렇지 않으면 경량 손 추적 알고리즘을 사용하여 후속랜드마크 감지를 위한 손의 위치를 결정합니다. | 0.0 - 1.0 |
0.5 |
|
minTrackingConfidence |
손 추적이 성공으로 간주되는 최소 신뢰도 점수입니다. 현재 프레임과 마지막 프레임의 손 사이의 경계 상자 IoU 임곗값입니다. 동작 인식기의 동영상 모드 및 스트림 모드에서 추적이 실패하면 동작 인식기가 손 감지를 트리거합니다. 그렇지 않으면 손 감지가 건너뜁니다. | 0.0 - 1.0 |
0.5 |
|
cannedGesturesClassifierOptions |
사전 준비된 동작 분류기 동작을 구성하기 위한 옵션입니다. 미리 준비된 동작은 ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"]입니다. |
|
|
|
customGesturesClassifierOptions |
맞춤 동작 분류기 동작을 구성하기 위한 옵션입니다. |
|
|
|
resultListener |
동작 인식기가 라이브 스트림 모드일 때 분류 결과를 비동기식으로 수신하도록 결과 리스너를 설정합니다.
실행 모드가 LIVE_STREAM로 설정된 경우에만 사용할 수 있습니다. |
ResultListener |
해당 사항 없음 | 해당 사항 없음 |
errorListener |
선택적 오류 리스너를 설정합니다. | ErrorListener |
해당 사항 없음 | 해당 사항 없음 |
데이터 준비
동작 감지기는 이미지, 동영상 파일, 라이브 스트림 동영상에서 작동합니다. 이 작업은 크기 조절, 회전, 값 정규화를 비롯한 데이터 입력 사전 처리를 처리합니다.
다음 코드는 처리를 위해 데이터를 전달하는 방법을 보여줍니다. 이 샘플에는 이미지, 동영상 파일, 라이브 동영상 스트림의 데이터를 처리하는 방법에 관한 세부정보가 포함되어 있습니다.
이미지
import com.google.mediapipe.framework.image.BitmapImageBuilder import com.google.mediapipe.framework.image.MPImage // Convert the input Bitmap object to an MPImage object to run inference val mpImage = BitmapImageBuilder(image).build()
동영상
import com.google.mediapipe.framework.image.BitmapImageBuilder import com.google.mediapipe.framework.image.MPImage val argb8888Frame = if (frame.config == Bitmap.Config.ARGB_8888) frame else frame.copy(Bitmap.Config.ARGB_8888, false) // Convert the input Bitmap object to an MPImage object to run inference val mpImage = BitmapImageBuilder(argb8888Frame).build()
실시간 스트림
import com.google.mediapipe.framework.image.BitmapImageBuilder import com.google.mediapipe.framework.image.MPImage // Convert the input Bitmap object to an MPImage object to run inference val mpImage = BitmapImageBuilder(rotatedBitmap).build()
동작 감지기 예시 코드에서 데이터 준비는 GestureRecognizerHelper.kt 파일에서 처리됩니다.
태스크 실행
동작 인식기는 recognize, recognizeForVideo, recognizeAsync 함수를 사용하여 추론을 트리거합니다. 동작 인식의 경우 입력 데이터를 사전 처리하고, 이미지에서 손을 감지하고, 손 랜드마크를 감지하고, 랜드마크에서 손 동작을 인식하는 작업이 포함됩니다.
다음 코드는 작업 모델로 처리를 실행하는 방법을 보여줍니다. 이러한 샘플에는 이미지, 동영상 파일, 라이브 동영상 스트림의 데이터를 처리하는 방법에 관한 세부정보가 포함되어 있습니다.
이미지
val result = gestureRecognizer?.recognize(mpImage)
동영상
val timestampMs = i * inferenceIntervalMs gestureRecognizer?.recognizeForVideo(mpImage, timestampMs) ?.let { recognizerResult -> resultList.add(recognizerResult) }
실시간 스트림
val mpImage = BitmapImageBuilder(rotatedBitmap).build()
val frameTime = SystemClock.uptimeMillis()
gestureRecognizer?.recognizeAsync(mpImage, frameTime)
다음에 유의하세요.
- 동영상 모드 또는 라이브 스트림 모드에서 실행할 때는 입력 프레임의 타임스탬프도 동작 감지기 작업에 제공해야 합니다.
- 이미지 모드 또는 동영상 모드에서 실행되면 동작 감지기 작업은 입력 이미지 또는 프레임 처리를 완료할 때까지 현재 스레드를 차단합니다. 사용자 인터페이스를 차단하지 않으려면 백그라운드 스레드에서 처리를 실행합니다.
- 라이브 스트림 모드에서 실행하면 동작 감지기 작업이 현재 스레드를 차단하지 않고 즉시 반환됩니다. 입력 프레임 처리가 완료될 때마다 인식 결과와 함께 결과 리스너를 호출합니다. 동작 인식기 태스크가 다른 프레임을 처리하느라 바쁠 때 인식 함수가 호출되면 태스크는 새 입력 프레임을 무시합니다.
동작 감지기 예시 코드에서 recognize, recognizeForVideo, recognizeAsync 함수는 GestureRecognizerHelper.kt 파일에 정의되어 있습니다.
결과 처리 및 표시
동작 인식기는 각 인식 실행에 대해 동작 감지 결과 객체를 생성합니다. 결과 객체에는 이미지 좌표의 손 지형지물, 세계 좌표의 손 지형지물, 손잡이(왼손/오른손), 감지된 손의 손 동작 카테고리가 포함됩니다.
다음은 이 태스크의 출력 데이터 예시입니다.
결과 GestureRecognizerResult에는 4개의 구성요소가 포함되며 각 구성요소는 배열입니다. 여기서 각 요소는 감지된 단일 손의 감지 결과를 포함합니다.
주로 사용하는 손
손잡이는 감지된 손이 왼손인지 오른손인지 나타냅니다.
동작
감지된 손의 인식된 동작 카테고리입니다.
명소
손 랜드마크는 21개 있으며 각 랜드마크는
x,y,z좌표로 구성됩니다.x및y좌표는 각각 이미지 너비와 높이에 따라 [0.0, 1.0] 으로 정규화됩니다.z좌표는 랜드마크 깊이를 나타내며, 손목의 깊이가 원점입니다. 값이 작을수록 랜드마크가 카메라에 가까워집니다.z의 크기는x와 거의 동일한 크기를 사용합니다.세계 명소
21개의 손 랜드마크도 세계 좌표로 표시됩니다. 각 랜드마크는
x,y,z로 구성되며, 손의 기하학적 중심을 원점으로 하는 실제 3D 좌표를 미터 단위로 나타냅니다.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
다음 이미지는 태스크 출력의 시각화를 보여줍니다.
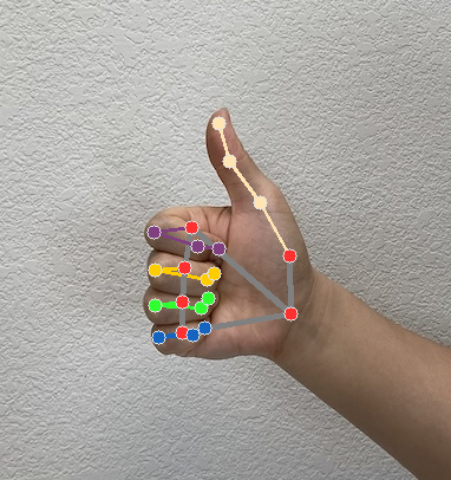
동작 감지기 예시 코드에서 GestureRecognizerResultsAdapter.kt 파일의 GestureRecognizerResultsAdapter 클래스가 결과를 처리합니다.