
Página do modelo:CodeGemma
Recursos e documentação técnica:
Termos de Uso:Termos
Autores:Google
Informações do modelo
Resumo do modelo
Descrição
O CodeGemma é uma família de modelos de código aberto leves criados com base no Gemma. Os modelos CodeGemma são modelos de decodificador de texto para texto e de texto para código e estão disponíveis como uma variante pré-treinada de 7 bilhões que se especializa em tarefas de preenchimento e geração de código, uma variante ajustada de instrução de 7 bilhões para chat de código e acompanhamento de instruções e uma variante pré-treinada de 2 bilhões para preenchimento rápido de código.
Entradas e saídas
Entrada: para variantes de modelos pré-treinados, use o prefixo e, opcionalmente, o sufixo para cenários de preenchimento e geração de código ou texto/comando de linguagem natural. Para a variante do modelo ajustada por instruções: texto ou comando de linguagem natural.
Saída:para variantes de modelos pré-treinados: preenchimento de código no meio, código e linguagem natural. Para a variante do modelo ajustada por instruções: código e linguagem natural.
Citação
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
Dados do modelo
Conjunto de dados de treinamento
Usando o Gemma como modelo base, as variantes pré-treinadas do CodeGemma 2B e 7B são treinadas em mais 500 a 1 bilhão de tokens de dados de idioma em inglês principalmente de conjuntos de dados de matemática de código aberto e código gerado sinteticamente.
Processamento de dados de treinamento
As técnicas de pré-processamento de dados a seguir foram aplicadas para treinar o CodeGemma:
- FIM: os modelos pré-treinados do CodeGemma se concentram em tarefas de preenchimento (FIM, na sigla em inglês). Os modelos são treinados para funcionar com os modos PSM e SPM. Nossas configurações de FIM são de 80% a 90% com 50/50 PSM/SPM.
- Técnicas de empacotamento lexical com base em testes de unidade e em gráfico de dependências: para melhorar o alinhamento do modelo com aplicativos do mundo real, estruturamos exemplos de treinamento no nível do projeto/repositório para colocar os arquivos de origem mais relevantes em cada repositório. Especificamente, empregamos duas técnicas heuristicas: empacotamento lexical baseado em testes de unidade e empacotamento baseado em gráfico de dependência.
- Desenvolvemos uma técnica nova para dividir os documentos em prefixo, meio e sufixo para que o sufixo comece em um ponto sintaticamente mais natural em vez de uma distribuição puramente aleatória.
- Segurança: assim como Gemma, implantamos uma filtragem de segurança rigorosa, incluindo filtragem de dados pessoais, filtragem de CSAM e outras filtragens com base na qualidade e segurança do conteúdo, de acordo com nossas políticas.
Informações de implementação
Hardware e frameworks usados durante o treinamento
Como o Gemma, o CodeGemma foi treinado na geração mais recente de hardware Unidade de Processamento de Tensor (TPU) (TPUv5e), usando JAX e ML Pathways.
Informações da avaliação
Resultados da comparação
Abordagem de avaliação
- Comparações de mercado para preenchimento de código: HumanEval (HE) (preenchimento de uma e várias linhas)
- Comparativos de mercado para geração de código: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
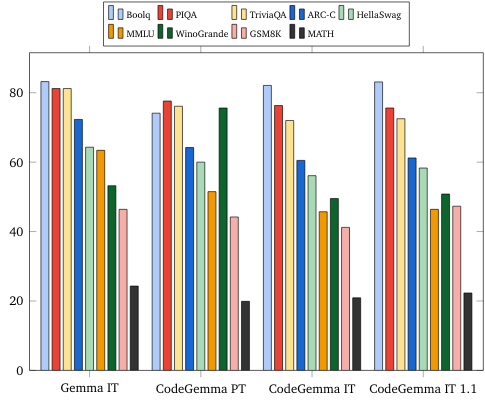
- Perguntas e respostas: BoolQ, PIQA, TriviaQA
- Linguagem natural: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- Raciocínio matemático: GSM8K, MATH
Resultados da comparação de programação
| Benchmark | 2 bilhões | 2B (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37,8 | 44,5 | 56.1 | 60,4 |
| MBPP | 43,6 | 49,2 | 56.2 | 54,2 | 55,6 |
| HumanEval Single Line | 78,4 | 79,3 | 76,1 | 68,3 | 77,4 |
| HumanEval Multi Line | 51,4 | 51,0 | 58,4 | 20.1 | 23.7 |
| BC HE C++ | 24.2 | 19,9 | 32,9 | 42.2 | 46,6 |
| BC HE C# | 10.6 | 26.1 | 22,4 | 26,7 | 54,7 |
| BC HE Go | 20,5 | 18.0 | 21,7 | 28,6 | 34.2 |
| BC HE Java | 29,2 | 29,8 | 41,0 | 48,4 | 50,3 |
| JavaScript BC HE | 21,7 | 28.0 | 39,8 | 46,0 | 48,4 |
| BC HE Kotlin | 28.0 | 32.3 | 39,8 | 51,6 | 47,8 |
| BC HE Python | 21,7 | 36,6 | 42.2 | 48,4 | 54,0 |
| BC HE Rust | 26,7 | 24.2 | 34.1 | 36,0 | 37,3 |
| BC MBPP C++ | 47.1 | 38,9 | 53,8 | 56,7 | 63,5 |
| BC MBPP C# | 28,7 | 45.3 | 32,5 | 41.2 | 62,0 |
| BC MBPP Go | 45,6 | 38,9 | 43.3 | 46,2 | 53.2 |
| Java do BC MBPP | 41,8 | 49,7 | 50,3 | 57,3 | 62,9 |
| JavaScript do BC MBPP | 45.3 | 45,0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46,8 | 49,7 | 54,7 | 59,9 | 62,6 |
| BC MBPP Python | 38,6 | 52,9 | 59,1 | 62,0 | 60.2 |
| BC MBPP Rust | 45.3 | 47,4 | 52,9 | 53,5 | 52,3 |
Comparações de mercado de linguagem natural (em modelos de 7 bilhões)
Ética e segurança
Ética e avaliações de segurança
Abordagem de avaliação
Nossos métodos de avaliação incluem avaliações estruturadas e testes internos de equipe vermelha de políticas de conteúdo relevantes. O red-teaming foi conduzido por várias equipes diferentes, cada uma com objetivos e métricas de avaliação humana diferentes. Esses modelos foram avaliados em relação a várias categorias diferentes relevantes para ética e segurança, incluindo:
Avaliação humana de instruções que abrangem a segurança do conteúdo e os danos de representação. Consulte o card do modelo Gemma para mais detalhes sobre a abordagem de avaliação.
Testes específicos de recursos de ataque cibernético, com foco em testar recursos de hackeamento autônomo e garantir que os possíveis danos sejam limitados.
Resultados da avaliação
Os resultados das avaliações de ética e segurança estão dentro dos limites aceitáveis para atender às políticas internas em categorias como segurança infantil, segurança de conteúdo, danos de representação, memorização e danos em grande escala. Consulte o card de modelo do Gemma para mais detalhes.
Uso e limitações do modelo
Limitações conhecidas
Os modelos de linguagem grandes (LLMs) têm limitações com base nos dados de treinamento e nas limitações inerentes da tecnologia. Consulte o card do modelo Gemma para mais detalhes sobre as limitações de LLMs.
Considerações éticas e riscos
O desenvolvimento de modelos de linguagem grandes (LLMs) levanta várias questões éticas. Consideramos vários aspectos no desenvolvimento desses modelos.
Consulte a mesma discussão no card de modelo do Gemma para conferir os detalhes.
Uso pretendido
Aplicativo
Os modelos Code Gemma têm uma ampla gama de aplicações, que variam entre modelos de TI e PT. A lista a seguir de possíveis usos não é abrangente. O objetivo desta lista é fornecer informações contextuais sobre os possíveis casos de uso que os criadores do modelo consideraram como parte do treinamento e desenvolvimento do modelo.
- Conclusão de código: os modelos PT podem ser usados para concluir código com uma extensão de ambiente de desenvolvimento integrado
- Geração de código: o modelo de TI pode ser usado para gerar código com ou sem uma extensão de IDE
- Conversa de código: o modelo de TI pode oferecer interfaces de conversa que discutem código.
- Educação em programação: o modelo de TI oferece suporte a experiências interativas de aprendizado de programação, ajuda na correção de sintaxe ou oferece prática de programação.
Vantagens
No momento do lançamento, essa família de modelos oferece implementações de modelos de linguagem grandes de alto desempenho com foco em código, projetadas do zero para o desenvolvimento de IA responsável em comparação com modelos de tamanho semelhante.
Usando as métricas de avaliação de comparação de programação descritas neste documento, esses modelos mostraram desempenho superior a outras alternativas de modelo aberto de tamanho semelhante.