
모델 페이지: CodeGemma
리소스 및 기술 문서:
이용약관: 약관
저자: Google
모델 정보
모델 요약
설명
CodeGemma는 Gemma를 기반으로 빌드된 경량형 오픈 코드 모델 제품군입니다. CodeGemma 모델은 텍스트 대 텍스트 및 텍스트 대 코드 디코더 전용 모델이며, 코드 완성 및 코드 생성 태스크에 특화된 70억 개 사전 학습된 변형, 코드 채팅 및 명령어 실행을 위한 70억 개 매개변수 명령어 조정 변형, 빠른 코드 완성을 위한 20억 개 매개변수 사전 학습된 변형으로 사용할 수 있습니다.
입력 및 출력
입력: 사전 학습된 모델 변형의 경우 코드 완성 및 생성 시나리오 또는 자연어 텍스트/프롬프트의 코드 접두사 및 선택적으로 접미사 안내 조정 모델 변형의 경우: 자연어 텍스트 또는 프롬프트
출력: 사전 학습된 모델 변형의 경우: fill-in-the-middle 코드 완성, 코드, 자연어 안내 조정 모델 변형의 경우: 코드 및 자연어
인용
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
모델 데이터
학습 데이터 세트
Gemma를 기본 모델로 사용하여 CodeGemma 2B 및 7B 선행 학습 변형은 오픈소스 수학 데이터 세트 및 합성 생성 코드에서 주로 영어 언어 데이터의 추가 토큰 5,000억~10,000억 개를 사용하여 추가로 학습됩니다.
학습 데이터 처리
CodeGemma를 학습하는 데 다음과 같은 데이터 사전 처리 기법이 적용되었습니다.
- FIM - 사전 학습된 CodeGemma 모델은 fill-in-the-middle (FIM) 작업에 중점을 둡니다. 모델은 PSM 모드와 SPM 모드 모두에서 작동하도록 학습됩니다. FIM 설정은 50~50 PSM/SPM으로 80~90% FIM 비율입니다.
- 종속 항목 그래프 기반 패킹 및 단위 테스트 기반 렉시컬 패킹 기법: 실제 애플리케이션과의 모델 정렬을 개선하기 위해 프로젝트/저장소 수준에서 학습 예시를 구성하여 각 저장소 내에 가장 관련성 높은 소스 파일을 함께 배치했습니다. 구체적으로는 종속 항목 그래프 기반 패킹과 단위 테스트 기반 리터럴 패킹이라는 두 가지 휴리스틱 기법을 사용했습니다.
- 문서를 접두사, 중간, 접미사로 분할하는 새로운 기법을 개발하여 접미사가 순전히 무작위 배포가 아닌 더 문법적으로 자연스러운 지점에서 시작되도록 했습니다.
- 안전: Gemma와 마찬가지로 Google은 Google 정책에 따라 개인 정보 필터링, 아동 성적 학대물 필터링, 콘텐츠 품질 및 안전을 기반으로 한 기타 필터링을 포함한 엄격한 안전 필터링을 배포했습니다.
구현 정보
학습 중에 사용된 하드웨어 및 프레임워크
Gemma와 마찬가지로 CodeGemma는 JAX 및 ML 개발자 과정을 사용하여 최신 세대의 Tensor Processing Unit (TPU) 하드웨어 (TPUv5e)에서 학습되었습니다.
평가 정보
벤치마크 결과
평가 접근 방식
- 코드 완성 벤치마크: HumanEval (HE) (단일 줄 및 여러 줄 채우기)
- 코드 생성 벤치마크: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
- Q&A: BoolQ, PIQA, TriviaQA
- 자연어: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- 수학적 추론: GSM8K, MATH
코딩 벤치마크 결과
| 벤치마크 | 20억 | 2B (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60.4 |
| MBPP | 43.6 | 49.2 | 56.2 | 54.2 | 55.6 |
| HumanEval 단일 행 | 78.4 | 79.3 | 76.1 | 68.3 | 77.4 |
| HumanEval 여러 줄 | 51.4 | 51.0 | 58.4 | 20.1 | 23.7 |
| BC HE C++ | 24.2 | 19.9 | 32.9 | 42.2 | 46.6 |
| BC HE C# | 10.6 | 26.1 | 22.4 | 26.7 | 54.7 |
| BC HE Go | 20.5 | 18.0 | 21.7 | 28.6 | 34.2 |
| BC HE Java | 29.2 | 29.8 | 41.0 | 48.4 | 50.3 |
| BC HE JavaScript | 21.7 | 28.0 | 39.8 | 46.0 | 48.4 |
| BC HE Kotlin | 28.0 | 32.3 | 39.8 | 51.6 | 47.8 |
| BC HE Python | 21.7 | 36.6 | 42.2 | 48.4 | 54.0 |
| BC HE Rust | 26.7 | 24.2 | 34.1 | 36.0 | 37.3 |
| BC MBPP C++ | 47.1 | 38.9 | 53.8 | 56.7 | 63.5 |
| BC MBPP C# | 28.7 | 45.3 | 32.5 | 41.2 | 62.0 |
| BC MBPP Go | 45.6 | 38.9 | 43.3 | 46.2 | 53.2 |
| BC MBPP Java | 41.8 | 49.7 | 50.3 | 57.3 | 62.9 |
| BC MBPP JavaScript | 45.3 | 45.0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46.8 | 49.7 | 54.7 | 59.9 | 62.6 |
| BC MBPP Python | 38.6 | 52.9 | 59.1 | 62.0 | 60.2 |
| BC MBPP Rust | 45.3 | 47.4 | 52.9 | 53.5 | 52.3 |
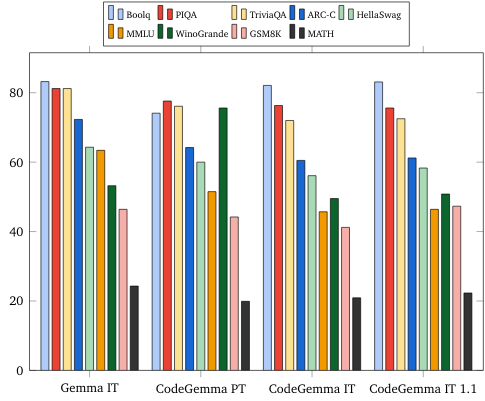
자연어 벤치마크 (70억 개 모델)
윤리 및 안전
윤리 및 안전 평가
평가 접근 방식
YouTube의 평가 방법에는 구조화된 평가와 관련 콘텐츠 정책에 대한 내부 레드 팀 테스트가 포함됩니다. 레드팀은 각각 서로 다른 목표와 인간 평가 측정항목을 가진 여러 팀에서 수행했습니다. 이러한 모델은 윤리 및 안전과 관련된 여러 카테고리(예:
콘텐츠 안전 및 표현적 해악을 다루는 프롬프트에 대한 사람의 평가 평가 접근 방식에 관한 자세한 내용은 Gemma 모델 카드를 참고하세요.
자율 해킹 기능 테스트 및 잠재적 피해 제한에 중점을 둔 사이버 공격 기능에 관한 구체적인 테스트
평가 결과
윤리 및 안전 평가 결과가 아동 안전, 콘텐츠 안전, 표현적 해악, 암기, 대규모 해악과 같은 카테고리의 내부 정책을 충족하기에 허용 가능한 기준점 내에 있습니다. 자세한 내용은 Gemma 모델 카드를 참고하세요.
모델 사용 및 제한사항
알려진 제한사항
대규모 언어 모델 (LLM)에는 학습 데이터와 기술의 고유한 제한사항에 따른 제한사항이 있습니다. LLM의 제한사항에 관한 자세한 내용은 Gemma 모델 카드를 참고하세요.
윤리적 고려사항 및 위험
대규모 언어 모델 (LLM)의 개발은 몇 가지 윤리적 문제를 제기합니다. Google은 이러한 모델을 개발할 때 여러 측면을 신중하게 고려했습니다.
모델 세부정보는 Gemma 모델 카드의 동일한 논의를 참고하세요.
사용 목적
애플리케이션
Code Gemma 모델은 IT 모델과 PT 모델 간에 다양한 애플리케이션을 보유하고 있습니다. 다음은 가능한 사용 사례의 일부 목록입니다. 이 목록의 목적은 모델 제작자가 모델 학습 및 개발의 일부로 고려한 가능한 사용 사례에 관한 문맥 정보를 제공하는 것입니다.
- 코드 완성: PT 모델을 사용하여 IDE 확장 프로그램으로 코드를 완성할 수 있습니다.
- 코드 생성: IT 모델을 사용하여 IDE 확장 프로그램 유무와 관계없이 코드를 생성할 수 있습니다.
- 코드 대화: IT 모델이 코드를 논의하는 대화 인터페이스를 지원할 수 있습니다.
- 코딩 교육: IT 모델이 대화형 코딩 학습 환경을 지원하거나, 문법 수정을 지원하거나, 코딩 연습을 제공합니다.
이점
출시 시 이 모델 제품군은 비슷한 크기의 모델에 비해 책임감 있는 AI 개발을 위해 처음부터 설계된 고성능 개방형 코드 중심 대규모 언어 모델 구현을 제공합니다.
이 문서에 설명된 코딩 벤치마크 평가 측정항목을 사용하면 이러한 모델이 비슷한 크기의 다른 오픈 소스 모델 대안보다 우수한 성능을 제공하는 것으로 나타났습니다.