
模型页面:CodeGemma
资源和技术文档:
使用条款: 条款
作者:Google
型号信息
模型摘要
说明
CodeGemma 是一系列基于 Gemma 构建的轻量级开放编码模型。CodeGemma 模型是文本到文本和文本到代码的仅解码器模型,提供以下变体:专门用于代码补全和代码生成任务的 70 亿参数预训练变体;用于代码聊天和指令遵循的 70 亿参数指令调优变体;以及用于快速代码补全的 20 亿参数预训练变体。
输入和输出
输入:对于预训练模型变体:代码前缀(可选)和代码补全和生成场景的后缀,或自然语言文本/提示。对于按指令微调的模型变体:自然语言文本或提示。
输出:对于预训练模型变体:填充中间部分代码补全、代码和自然语言。对于按指令调整的模型变体:代码和自然语言。
引用
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
模型数据
训练数据集
使用 Gemma 作为基础模型,CodeGemma 2B 和 7B 预训练变体在另外 500 到 10000 亿个令牌(主要来自开源数学数据集和合成生成的代码)的英语语言数据上进行了进一步训练。
训练数据处理
我们在训练 CodeGemma 时应用了以下数据预处理技术:
- FIM - 预训练的 CodeGemma 模型侧重于填充中间部分 (FIM) 任务。这些模型经过训练,可同时适用于 PSM 和 SPM 模式。我们的 FIM 设置为 80% 到 90% 的 FIM 速率,以及 50-50 PSM/SPM。
- 基于依赖项图的打包和基于单元测试的词法打包技术:为了提高模型与真实应用的契合度,我们在项目/代码库级别构建了训练示例,以便在每个代码库中放置最相关的源文件。具体而言,我们采用了两种启发词语技术:基于依赖项图的打包和基于单元测试的词法打包。
- 我们开发了一种新技术,用于将文档拆分为前缀、中间部分和后缀,以使后缀从语法上更自然的位置开始,而不是完全随机分布。
- 安全性:与 Gemma 一样,我们会根据我们的政策,部署严格的安全过滤措施,包括过滤个人数据、过滤 CSAM 内容以及根据内容质量和安全性进行的其他过滤。
实现信息
训练期间使用的硬件和框架
与 Gemma 一样,CodeGemma 使用 JAX 和 ML Pathways 在最新一代张量处理单元 (TPU) 硬件 (TPUv5e) 上进行训练。
评估信息
基准测试结果
评估方法
- 代码补全基准测试:HumanEval (HE)(单行和多行填充)
- 代码生成基准测试:HumanEval、MBPP、BabelCode (BC) [C++、C#、Go、Java、JavaScript、Kotlin、Python、Rust]
- 问答:BoolQ、PIQA、TriviaQA
- 自然语言:ARC-Challenge、HellaSwag、MMLU、WinoGrande
- 数学推理:GSM8K、MATH
编码基准测试结果
| 基准 | 2B | 2B (1.1) | 70 亿 | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60.4 |
| MBPP | 43.6 | 49.2 | 56.2 | 54.2 | 55.6 |
| HumanEval 单行 | 78.4 | 79.3 | 76.1 | 68.3 | 77.4 |
| HumanEval 多行 | 51.4 | 51.0 | 58.4 | 20.1 | 23.7 |
| BC HE C++ | 24.2 | 19.9 | 32.9 | 42.2 | 46.6 |
| BC HE C# | 10.6 | 26.1 | 22.4 | 26.7 | 54.7 |
| BC HE Go | 20.5 | 18.0 | 21.7 | 28.6 | 34.2 岁 |
| BC HE Java | 29.2 | 29.8 | 41.0 | 48.4 | 50.3 |
| BC HE JavaScript | 21.7 | 28.0 | 39.8 | 46.0 | 48.4 |
| BC HE Kotlin | 28.0 | 32.3 | 39.8 | 51.6 | 47.8 |
| BC HE Python | 21.7 | 36.6 | 42.2 | 48.4 | 54.0 |
| BC HE Rust | 26.7 | 24.2 | 34.1 | 36.0 | 37.3 |
| BC MBPP C++ | 47.1 | 38.9 岁 | 53.8 | 56.7 | 63.5 |
| BC MBPP C# | 28.7 | 45.3 | 32.5 岁 | 41.2 | 62.0 |
| BC MBPP Go | 45.6 | 38.9 岁 | 43.3 | 46.2 | 53.2 |
| BC MBPP Java | 41.8 | 49.7 | 50.3 | 57.3 | 62.9 |
| BC MBPP JavaScript | 45.3 | 45.0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46.8 | 49.7 | 54.7 | 59.9 | 62.6 |
| BC MBPP Python | 38.6 | 52.9 | 59.1 | 62.0 | 60.2 |
| BC MBPP Rust | 45.3 | 47.4 | 52.9 | 53.5 | 52.3 |
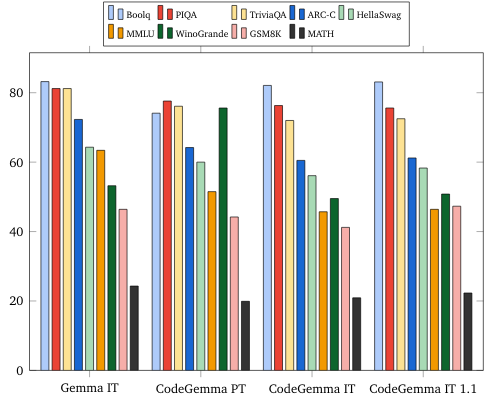
自然语言基准测试(基于 7B 模型)
道德和安全
伦理和安全评估
评估方法
我们的评估方法包括结构化评估,以及对相关内容政策的内部红队测试。红队攻击由多个不同的团队执行,每个团队都有不同的目标和人为评估指标。我们根据与伦理和安全相关的多个不同类别对这些模型进行了评估,包括:
针对涉及内容安全性和表征性伤害的提示进行人工评估。如需详细了解评估方法,请参阅 Gemma 模型卡片。
对网络攻击能力进行专门测试,重点是测试自主黑客攻击能力并确保潜在危害受到限制。
评估结果
在儿童安全、内容安全、表征性伤害、记忆、大规模伤害等类别方面,伦理和安全评估结果符合内部政策的接受阈值。如需了解详情,请参阅 Gemma 模型卡片。
模型使用和限制
已知限制
大语言模型 (LLM) 存在一些限制,这些限制源自其训练数据和该技术固有的限制。如需详细了解 LLM 的限制,请参阅 Gemma 模型卡片。
道德注意事项和风险
大语言模型 (LLM) 的开发引发了一些伦理问题。在开发这些模型时,我们仔细考虑了多方面因素。
如需了解模型详情,请参阅 Gemma 模型卡片中的相同讨论。
预期用途
应用
Code Gemma 模型具有广泛的应用,具体取决于 IT 和 PT 模型。以下潜在用途列表并未详尽列出所有用途。此列表旨在提供背景信息,说明模型创建者在模型训练和开发过程中考虑的可能用例。
- 代码补全:PT 模型可用于通过 IDE 扩展程序补全代码
- 代码生成:IT 模型可用于在有或没有 IDE 扩展程序的情况下生成代码
- 代码对话:IT 模型可为讨论代码的对话界面提供支持
- 编程教育:IT 模型支持互动式编程学习体验,有助于语法纠正或提供编程练习
优势
与同等规模的模型相比,此系列模型在发布时提供专注于开源代码的高性能大语言模型实现,从头开始设计,以实现 Responsible AI 开发。
使用本文档中介绍的编码基准评估指标,这些模型的性能已被证明优于其他规模相当的开放模型替代方案。