
Faqja e modelit: CodeGemma
Burimet dhe dokumentacioni teknik:
Kushtet e Përdorimit: Kushtet
Autorë: Google
Informacioni i modelit
Përmbledhja e modelit
Përshkrimi
CodeGemma është një familje modelesh të lehta me kod të hapur të ndërtuara në krye të Gemma. Modelet CodeGemma janë modele vetëm dekoder tekst-me-tekst dhe tekst-në-kod dhe janë të disponueshme si një variant 7 miliardë i paratrajnuar që specializohet në detyrat e plotësimit të kodit dhe gjenerimit të kodit, një variant 7 miliardë parametrash i akorduar me instruksione për bisedën dhe udhëzimin e kodit në vijim dhe një variant i paratrajnuar me 2 miliardë parametra për plotësimin e shpejtë të kodit.
Inputet dhe daljet
Hyrja: Për variantet e modelit të trajnuar paraprakisht: parashtesa e kodit dhe prapashtesa opsionale për skenarët e plotësimit dhe gjenerimit të kodit ose teksti/kërkesa e gjuhës natyrore. Për variantin e modelit të akorduar sipas udhëzimeve: tekst ose kërkesë në gjuhën natyrore.
Rezultati: Për variantet e modelit të trajnuar paraprakisht: plotësimi i kodit në mes, kodi dhe gjuha natyrore. Për variantin e modelit të akorduar me udhëzim: kodi dhe gjuha natyrore.
Citim
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
Të dhënat e modelit
Të dhënat e trajnimit
Duke përdorur Gemma si modelin bazë, variantet e para-trajnuara CodeGemma 2B dhe 7B trajnohen më tej në 500 deri në 1000 miliardë argumente shtesë të të dhënave kryesisht në gjuhën angleze nga grupet e të dhënave të matematikës me burim të hapur dhe kodi i krijuar në mënyrë sintetike.
Përpunimi i të dhënave të trajnimit
Teknikat e mëposhtme të parapërpunimit të të dhënave u aplikuan për të trajnuar CodeGemma:
- FIM - Modelet e paratrajnuara të CodeGemma fokusohen në detyrat plotësuese në mes (FIM). Modelet janë trajnuar për të punuar me të dyja mënyrat PSM dhe SPM. Cilësimet tona FIM janë 80% deri në 90% norma FIM me 50-50 PSM/SPM.
- Paketimi i bazuar në grafikun e varësisë dhe teknikat e paketimit leksikor të bazuara në teste njësi: Për të përmirësuar përafrimin e modelit me aplikacionet e botës reale, ne strukturuam shembuj trajnimi në nivel projekti/depoje për të vendosur skedarët burimor më të rëndësishëm brenda çdo depoje. Në mënyrë të veçantë, ne përdorëm dy teknika heuristike: paketimin e bazuar në grafikun e varësisë dhe paketimin leksikor të bazuar në testin e njësive.
- Ne zhvilluam një teknikë të re për ndarjen e dokumenteve në parashtesë, mes dhe prapashtesë për ta bërë prapashtesën të fillojë në një pikë më natyrale sintaksisht dhe jo në shpërndarje thjesht të rastësishme.
- Siguria: Ngjashëm me Gemma, ne vendosëm filtrim rigoroz të sigurisë duke përfshirë filtrimin e të dhënave personale, filtrimin CSAM dhe filtrim të tjerë bazuar në cilësinë dhe sigurinë e përmbajtjes në përputhje me politikat tona .
Informacioni i zbatimit
Pajisjet dhe kornizat e përdorura gjatë trajnimit
Ashtu si Gemma , CodeGemma u trajnua në gjeneratën e fundit të harduerit të Njësisë së Përpunimit Tensor (TPU) (TPUv5e), duke përdorur JAX dhe ML Pathways .
Informacioni i vlerësimit
Rezultatet e standardeve
Qasja e vlerësimit
- Standardet e plotësimit të kodit: HumanEval (HE) (Plotësimi me një linjë dhe me shumë rreshta)
- Standardet e gjenerimit të kodit: HumanEval, MBPP , BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
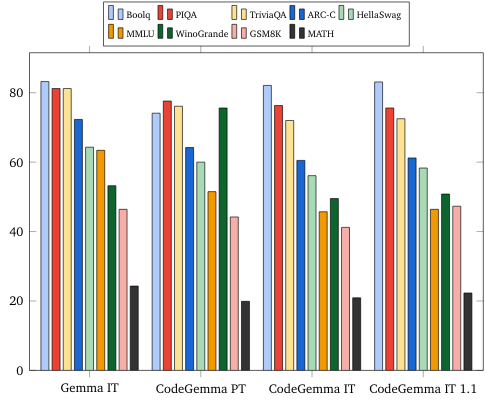
- Pyetje dhe përgjigje: BoolQ , PIQA , TriviaQA
- Gjuha natyrore: ARC-Sfida , HellaSwag , MMLU , WinoGrande
- Arsyetimi matematikor: GSM8K , MATH
Rezultatet e standardeve të kodimit
| Standardi | 2B | 2B (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60.4 |
| MBPP | 43.6 | 49.2 | 56.2 | 54.2 | 55.6 |
| Linja e vetme HumanEval | 78.4 | 79.3 | 76.1 | 68.3 | 77.4 |
| HumanEval Multi Line | 51.4 | 51.0 | 58.4 | 20.1 | 23.7 |
| BC HE C++ | 24.2 | 19.9 | 32.9 | 42.2 | 46.6 |
| BC HE C# | 10.6 | 26.1 | 22.4 | 26.7 | 54.7 |
| BC AI Shko | 20.5 | 18.0 | 21.7 | 28.6 | 34.2 |
| BC HE Java | 29.2 | 29.8 | 41.0 | 48.4 | 50.3 |
| BC HE JavaScript | 21.7 | 28.0 | 39.8 | 46.0 | 48.4 |
| BC HE Kotlin | 28.0 | 32.3 | 39.8 | 51.6 | 47.8 |
| BC HE Python | 21.7 | 36.6 | 42.2 | 48.4 | 54.0 |
| BC HE Ndryshk | 26.7 | 24.2 | 34.1 | 36.0 | 37.3 |
| BC MBPP C++ | 47.1 | 38.9 | 53.8 | 56.7 | 63.5 |
| BC MBPP C# | 28.7 | 45.3 | 32.5 | 41.2 | 62.0 |
| BC MBPP Shko | 45.6 | 38.9 | 43.3 | 46.2 | 53.2 |
| BC MBPP Java | 41.8 | 49.7 | 50.3 | 57.3 | 62.9 |
| BC MBPP JavaScript | 45.3 | 45.0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46.8 | 49.7 | 54.7 | 59.9 | 62.6 |
| BC MBPP Python | 38.6 | 52.9 | 59.1 | 62.0 | 60.2 |
| BC MBPP Rust | 45.3 | 47.4 | 52.9 | 53.5 | 52.3 |
Standardet e gjuhës natyrore (në modelet 7B)
Etika dhe siguria
Vlerësimet e etikës dhe sigurisë
Qasja e vlerësimeve
Metodat tona të vlerësimit përfshijnë vlerësime të strukturuara dhe testime të brendshme të grupeve të kuqe të politikave përkatëse të përmbajtjes. Red-skuadra u krye nga një numër skuadrash të ndryshme, secila me qëllime të ndryshme dhe metrika të vlerësimit njerëzor. Këto modele u vlerësuan kundrejt një numri kategorish të ndryshme që lidhen me etikën dhe sigurinë, duke përfshirë:
Vlerësimi njerëzor mbi kërkesat që mbulojnë sigurinë e përmbajtjes dhe dëmet e përfaqësimit. Shikoni kartën e modelit Gemma për më shumë detaje mbi qasjen e vlerësimit.
Testimi specifik i aftësive të sulmeve kibernetike, duke u fokusuar në testimin e aftësive autonome të hakerimit dhe sigurimin e dëmeve të mundshme janë të kufizuara.
Rezultatet e vlerësimit
Rezultatet e vlerësimeve të etikës dhe sigurisë janë brenda kufijve të pranueshëm për përmbushjen e politikave të brendshme për kategori të tilla si siguria e fëmijëve, siguria e përmbajtjes, dëmet e përfaqësimit, memorizimi, dëmet në shkallë të gjerë. Shikoni kartën e modelit Gemma për më shumë detaje.
Përdorimi dhe kufizimet e modelit
Kufizimet e njohura
Modelet e mëdha të gjuhës (LLM) kanë kufizime bazuar në të dhënat e tyre të trajnimit dhe kufizimet e qenësishme të teknologjisë. Shikoni kartën e modelit Gemma për më shumë detaje mbi kufizimet e LLM-ve.
Konsideratat dhe rreziqet etike
Zhvillimi i modeleve të mëdha gjuhësore (LLM) ngre disa shqetësime etike. Ne kemi shqyrtuar me kujdes aspekte të shumta në zhvillimin e këtyre modeleve.
Ju lutemi referojuni të njëjtit diskutim në kartën e modelit Gemma për detajet e modelit.
Përdorimi i synuar
Aplikimi
Modelet Code Gemma kanë një gamë të gjerë aplikimesh, të cilat ndryshojnë midis modeleve IT dhe PT. Lista e mëposhtme e përdorimeve të mundshme nuk është gjithëpërfshirëse. Qëllimi i kësaj liste është të sigurojë informacion kontekstual në lidhje me rastet e mundshme të përdorimit që krijuesit e modelit i konsideruan si pjesë e trajnimit dhe zhvillimit të modelit.
- Plotësimi i kodit: Modelet PT mund të përdoren për të plotësuar kodin me një shtrirje IDE
- Gjenerimi i kodit: Modeli IT mund të përdoret për të gjeneruar kode me ose pa një shtesë IDE
- Biseda me kode: Modeli IT mund të fuqizojë ndërfaqet e bisedave të cilat diskutojnë kodin
- Edukimi i kodit: Modeli IT mbështet përvojat ndërvepruese të të mësuarit të kodit, ndihmon në korrigjimin e sintaksës ose ofron praktikë kodimi
Përfitimet
Në momentin e lëshimit, kjo familje modelesh ofron zbatime të modeleve të gjuhëve të mëdha të përqendruara në kode me performancë të lartë, të dizajnuara nga themelet për zhvillimin e Përgjegjshëm të AI krahasuar me modelet me madhësi të ngjashme.
Duke përdorur matjet e vlerësimit të standardeve të kodimit të përshkruara në këtë dokument, këto modele kanë treguar se ofrojnë performancë superiore ndaj alternativave të tjera të modelit të hapur me madhësi të krahasueshme.