
Pagina del modello: CodeGemma
Risorse e documentazione tecnica:
Termini e condizioni d'uso: Termini
Autori: Google
Informazioni sul modello
Riepilogo modello
Descrizione
CodeGemma è una famiglia di modelli open source leggeri basati su Gemma. I modelli CodeGemma sono modelli solo di decodifica da testo a testo e da testo a codice e sono disponibili come variante preaddestrata da 7 miliardi di parametri specializzata in attività di completamento e generazione di codice, una variante con 7 miliardi di parametri ottimizzata per le istruzioni per chat di codice e l'esecuzione di istruzioni e una variante preaddestrata con 2 miliardi di parametri per il completamento rapido del codice.
Input e output
Input: per le varianti del modello preaddestrato: prefisso e, facoltativamente, suffisso del codice per scenari di completamento e generazione di codice o testo/prompt in linguaggio naturale. Per la variante del modello ottimizzata in base alle istruzioni: testo in linguaggio naturale o prompt.
Output: per le varianti del modello preaddestrato: compilazione del codice con riempimento intermedio, codice e linguaggio naturale. Per la variante del modello ottimizzata per le istruzioni: codice e linguaggio naturale.
Citazione
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
Dati del modello
Set di dati di addestramento
Utilizzando Gemma come modello di base, le varianti preaddestrate di CodeGemma 2B e 7B vengono ulteriormente addestrate su altri 500-1000 miliardi di token di dati linguistici principalmente in inglese provenienti da set di dati matematici open source e codice generato sinteticamente.
Elaborazione dei dati di addestramento
Per addestrare CodeGemma sono state applicate le seguenti tecniche di pre-elaborazione dei dati:
- FIM: i modelli CodeGemma preaddestrati si concentrano sulle attività di completamento intermedio (FIM). I modelli vengono addestrati per funzionare sia con la modalità PSM sia con la modalità SPM. Le nostre impostazioni FIM sono in un intervallo compreso tra l'80% e il 90% con PSM/SPM 50-50.
- Tecniche di organizzazione in pacchetti basate su grafo di dipendenze e tecniche di organizzazione in pacchetti lessicali basate su test di unità: per migliorare l'allineamento del modello con le applicazioni reali, abbiamo strutturato gli esempi di addestramento a livello di progetto/repository per collocare in modo co-localizzato i file di origine più pertinenti all'interno di ogni repository. In particolare, abbiamo utilizzato due tecniche basate su heuristics: il packing basato sul grafo delle dipendenze e il packing lessicale basato sui test di unità.
- Abbiamo sviluppato una nuova tecnica per suddividere i documenti in prefisso, mediana e suffisso in modo che il suffisso inizi in un punto sintatticamente più naturale anziché in una distribuzione puramente casuale.
- Sicurezza: come per Gemma, abbiamo implementato rigorosi filtri di sicurezza, tra cui il filtro dei dati personali, il filtro del materiale pedopornografico e altri filtri in base alla qualità e alla sicurezza dei contenuti, in linea con le nostre norme.
Informazioni sull'implementazione
Hardware e framework utilizzati durante l'addestramento
Come Gemma, CodeGemma è stato addestrato sull'hardware (TPUv5e) di ultima generazione Tensor Processing Unit (TPU), utilizzando JAX e ML Pathways.
Informazioni sulla valutazione
Risultati del benchmark
Approccio di valutazione
- Benchmark per il completamento del codice: HumanEval (HE) (compilazione di una riga e di più righe)
- Benchmark di generazione di codice: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
- Domande e risposte: BoolQ, PIQA, TriviaQA
- Linguaggio naturale: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- Ragionamento matematico: GSM8K, MATH
Risultati del benchmark di programmazione
| Benchmark | 2B | 2 miliardi (1.1) | 7 miliardi | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37,8 | 44,5 | 56,1 | 60,4 |
| MBPP | 43,6 | 49,2 | 56,2 | 54,2 | 55,6 |
| HumanEval riga singola | 78,4 | 79,3 | 76,1 | 68,3 | 77,4 |
| HumanEval Multi Line | 51,4 | 51,0 | 58,4 | 20,1 | 23,7 |
| BC HE C++ | 24,2 | 19,9 | 32,9 | 42,2 | 46,6 |
| BC HE C# | 10.6 | 26.1 | 22,4 | 26,7 | 54,7 |
| BC HE Go | 20,5 | 18.0 | 21,7 | 28,6 | 34,2 |
| BC HE Java | 29,2 | 29,8 | 41,0 | 48,4 | 50,3 |
| JavaScript BC HE | 21,7 | 28,0 | 39,8 | 46,0 | 48,4 |
| BC HE Kotlin | 28,0 | 32,3 | 39,8 | 51,6 | 47,8 |
| BC HE Python | 21,7 | 36,6 | 42,2 | 48,4 | 54,0 |
| Ruggine BC HE | 26,7 | 24,2 | 34,1 | 36,0 | 37,3 |
| BC MBPP C++ | 47,1 | 38,9 | 53,8 | 56,7 | 63,5 |
| BC MBPP C# | 28,7 | 45,3 | 32,5 | 41,2 | 62,0 |
| BC MBPP Go | 45,6 | 38,9 | 43,3 | 46,2 | 53,2 |
| Java BC MBPP | 41,8 | 49,7 | 50,3 | 57,3 | 62,9 |
| JavaScript BC MBPP | 45,3 | 45,0 | 58,2 | 61,4 | 61,4 |
| BC MBPP Kotlin | 46,8 | 49,7 | 54,7 | 59,9 | 62,6 |
| BC MBPP Python | 38,6 | 52,9 | 59,1 | 62,0 | 60,2 |
| BC MBPP Rust | 45,3 | 47,4 | 52,9 | 53,5 | 52,3 |
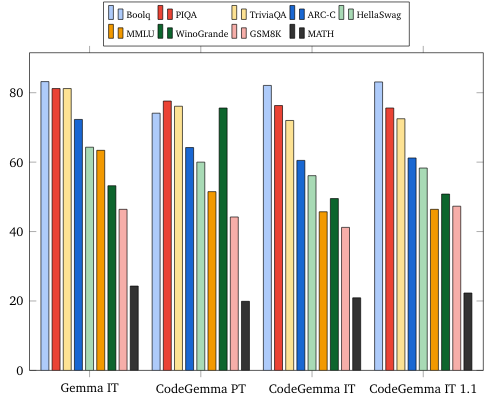
Benchmark sul linguaggio naturale (su modelli da 7 miliardi)
Etica e sicurezza
Valutazioni di etica e sicurezza
Approccio alle valutazioni
I nostri metodi di valutazione includono valutazioni strutturate e test di red team interni delle norme relative ai contenuti pertinenti. L'attività di red teaming è stata condotta da diversi team, ognuno con obiettivi e metriche di valutazione umana diversi. Questi modelli sono stati valutati in base a una serie di categorie diverse pertinenti a temi etici e di sicurezza, tra cui:
Valutazione umana dei prompt che riguardano la sicurezza dei contenuti e i danni rappresentati. Per ulteriori dettagli sull'approccio di valutazione, consulta la scheda del modello Gemma.
Test specifici delle funzionalità di cyber-offesa, incentrato sul test delle funzionalità di hacking autonome e sulla garanzia che i potenziali danni siano limitati.
Risultati valutazione
I risultati delle valutazioni relative a etica e sicurezza rientrano nelle soglie accettabili per rispettare le norme interne per categorie quali sicurezza dei bambini, sicurezza dei contenuti, danni causati dalla rappresentazione, memorizzazione, danni su larga scala. Per ulteriori dettagli, consulta la scheda del modello Gemma.
Utilizzo e limitazioni dei modelli
Limitazioni note
I modelli linguistici di grandi dimensioni (LLM) hanno limitazioni in base ai dati di addestramento e ai limiti insiti della tecnologia. Per ulteriori dettagli sulle limitazioni degli LLM, consulta la scheda del modello Gemma.
Considerazioni etiche e rischi
Lo sviluppo di modelli linguistici di grandi dimensioni (LLM) solleva diversi problemi etici. Abbiamo preso in considerazione attentamente diversi aspetti nello sviluppo di questi modelli.
Per informazioni dettagliate sul modello, consulta la stessa discussione nella scheda del modello Gemma.
Utilizzo previsto
Applicazione
I modelli Code Gemma hanno una vasta gamma di applicazioni, che variano in base ai modelli IT e PT. Il seguente elenco di potenziali utilizzi non è esaustivo. Lo scopo di questo elenco è fornire informazioni contestuali sui possibili casi d'uso che i creator dei modelli hanno preso in considerazione durante l'addestramento e lo sviluppo dei modelli.
- Completamento del codice: i modelli PT possono essere utilizzati per completare il codice con un'estensione IDE
- Generazione di codice: il modello IT può essere utilizzato per generare codice con o senza un'estensione IDE
- Conversazione di codice: il modello IT può supportare interfacce di conversazione che discutono di codice
- Istruzione di programmazione: il modello IT supporta esperienze di apprendimento interattive del codice, aiuta a correggere la sintassi o fornisce esercitazioni di programmazione
Vantaggi
Al momento del rilascio, questa famiglia di modelli fornisce implementazioni di modelli linguistici di grandi dimensioni aperte e incentrate sul codice ad alte prestazioni, progettate da zero per lo sviluppo di AI responsabile rispetto ai modelli di dimensioni simili.
Utilizzando le metriche di valutazione del benchmark di codifica descritte in questo documento, questi modelli hanno dimostrato di offrire un rendimento superiore rispetto ad altre alternative di modelli aperti di dimensioni simili.