
LiteRT est le framework Google sur l'appareil pour le déploiement de ML et d'IA générative hautes performances sur les plates-formes Edge.
Conversion, exécution et optimisation efficaces pour le machine learning sur l'appareil.
Basé sur la base éprouvée de TensorFlow Lite
LiteRT n'est pas seulement nouveau : il s'agit de la prochaine génération du runtime de machine learning le plus déployé au monde. Il alimente les applications que vous utilisez tous les jours, en offrant une faible latence et une confidentialité élevée sur des milliards d'appareils.
Approuvé par les applications Google les plus critiques
Plus de 100 000 applications, des milliards d'utilisateurs dans le monde
Points forts de LiteRT

Compatible multiplate-forme

Exploiter l'IA générative

Accélération matérielle simplifiée

Compatibilité avec plusieurs frameworks
Déployer avec LiteRT
Simplifiez votre workflow de deep learning, de l'entraînement au déploiement sur l'appareil.

1.Obtenir un modèle
Utilisez des modèles pré-entraînés .tflite ou convertissez des modèles PyTorch, JAX ou TensorFlow au format .tflite.

2.Optimiser
Utilisez le kit d'outils d'optimisation LiteRT pour quantifier vos modèles après l'entraînement.

3.Course
Déployez votre modèle avec LiteRT et choisissez l'accélérateur optimal pour votre application.
Choisir votre parcours de développement
Utilisez LiteRT pour déployer l'IA n'importe où, des applications mobiles hautes performances aux appareils IoT aux ressources limitées.
Utilisateur TFLite existant
Passage à LiteRT pour profiter de performances améliorées et d'API unifiées sur toutes les plates-formes (Android, ordinateur, Web).
BYOM : Bring Your Own Models
Vous avez un modèle PyTorch et vous souhaitez implémenter des expériences de vision ou audio sur l'appareil.
Déployer des modèles d'IA générative
Créer des chatbots sophistiqués sur l'appareil à l'aide de modèles d'IA générative à poids ouverts optimisés comme Gemma ou un autre modèle à poids ouvert.
[Avancé] Expert en modèles
Créer des modèles personnalisés ou effectuer des optimisations CPU/GPU/NPU spécifiques au matériel pour des performances optimales.
Exemples, modèles et démo

Consulter l'exemple d'application LiteRT sur GitHub
Exemples d'applications complètes de bout en bout.

Voir les modèles d'IA générative
Modèles d'IA générative pré-entraînés et prêts à l'emploi.

Voir les démos : application Google AI Edge Gallery
Galerie présentant des cas d'utilisation du ML/de l'IA générative sur l'appareil à l'aide de LiteRT.
Blogs et annonces
Tenez-vous informé des dernières annonces, présentations techniques détaillées et benchmarks de performances de l'équipe LiteRT.

Créer une IA sur l'appareil concrète avec LiteRT et NPU
Découvrez comment les leaders du secteur créent des applications d'IA hautes performances et concrètes sur l'appareil à l'aide de LiteRT et des NPU.
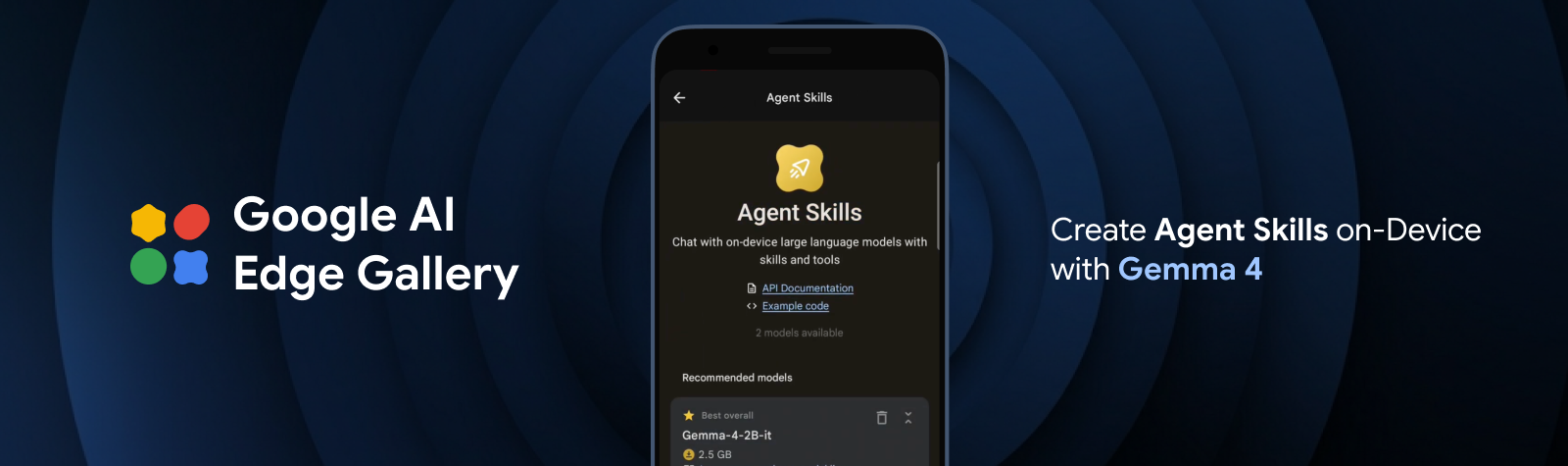
Exploitez des compétences agentives de pointe en périphérie avec Gemma 4
Déployez des capacités de planification agentives et en plusieurs étapes entièrement sur l'appareil avec la nouvelle famille Gemma 4 et LiteRT.

LiteRT : le framework universel pour l'IA sur l'appareil
Framework de ML unifié de Google sur l'appareil, qui évolue à partir de TFLite pour un déploiement hautes performances.
NPU MediaTek et LiteRT : au service de la nouvelle génération d'IA sur l'appareil
Extension de la compatibilité de l'accélération NPU aux chipsets MediaTek pour une IA très efficace.
Exploiter tout le potentiel des NPU Qualcomm avec LiteRT
Des performances révolutionnaires pour l'IA générative sur les unités de traitement neuronal Qualcomm.

LiteRT : des performances maximales, simplifiées
Présentation de l'API CompiledModel pour la sélection automatique du matériel et l'exécution asynchrone.
IA générative sur l'appareil dans Chrome, Chromebook Plus et Pixel Watch avec LiteRT-LM
Déployez des modèles de langage sur des plates-formes portables et basées sur navigateur à l'aide de LiteRT-LM.

Petits modèles de langage, multimodalité et appel de fonction Google AI Edge
Dernières informations sur le RAG, la multimodalité et les appels de fonction pour les modèles de langage Edge
Rejoignez la communauté
Communauté GitHub LiteRT
Contribuez directement au projet et collaborez avec les développeurs principaux.

Hugging Face Hub
Accédez à des modèles à pondération ouverte optimisés sur le hub Hugging Face.