
Задача распознавания жестов MediaPipe позволяет распознавать жесты рук в реальном времени и предоставляет результаты распознавания жестов, а также координаты обнаруженных рук. В этих инструкциях показано, как использовать распознаватель жестов для веб-приложений и приложений на JavaScript.
Вы можете увидеть эту задачу в действии, посмотрев демонстрацию . Для получения дополнительной информации о возможностях, моделях и параметрах конфигурации этой задачи см. раздел «Обзор» .
Пример кода
Пример кода для распознавания жестов представляет собой полную реализацию этой задачи на JavaScript для вашего ознакомления. Этот код поможет вам протестировать задачу и начать разработку собственного приложения для распознавания жестов. Вы можете просматривать, запускать и редактировать пример распознавания жестов, используя только веб-браузер.
Настраивать
В этом разделе описаны ключевые шаги по настройке среды разработки специально для использования Gesture Recognizer. Общую информацию о настройке среды разработки веб-приложений и JavaScript, включая требования к версиям платформы, см. в руководстве по настройке веб-приложений .
пакеты JavaScript
Код распознавания жестов доступен через NPM- пакет MediaPipe @mediapipe/tasks-vision . Вы можете найти и загрузить эти библиотеки, следуя инструкциям в руководстве по настройке платформы.
Необходимые пакеты можно установить через NPM, используя следующую команду:
npm install @mediapipe/tasks-vision
Если вы хотите импортировать код задачи через службу сети доставки контента (CDN), добавьте следующий код в тег <head> вашего HTML-файла:
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
Модель
Для задачи распознавания жестов MediaPipe требуется обученная модель, совместимая с этой задачей. Дополнительную информацию о доступных обученных моделях для распознавания жестов см. в разделе «Модели» обзора задачи.
Выберите и загрузите модель, а затем сохраните её в каталоге вашего проекта:
<dev-project-root>/app/shared/models/
Создайте задачу
Используйте одну из функций createFrom...() класса Gesture Recognizer, чтобы подготовить задачу к выполнению выводов. Используйте функцию createFromModelPath() с относительным или абсолютным путем к файлу обученной модели. Если ваша модель уже загружена в память, вы можете использовать метод createFromModelBuffer() .
Приведённый ниже пример кода демонстрирует использование функции createFromOptions() для настройки задачи. Функция createFromOptions позволяет настраивать распознаватель жестов с помощью параметров конфигурации. Дополнительную информацию о параметрах конфигурации см. в разделе «Параметры конфигурации» .
Приведенный ниже код демонстрирует, как создать и настроить задачу с пользовательскими параметрами:
// Create task for image file processing:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm "
);
const gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath: "https://storage.googleapis.com/mediapipe-tasks/gesture_recognizer/gesture_recognizer.task"
},
numHands: 2
});
Параметры конфигурации
Данная задача имеет следующие параметры конфигурации для веб-приложений:
| Название варианта | Описание | Диапазон значений | Значение по умолчанию |
|---|---|---|---|
runningMode | Задает режим выполнения задачи. Доступны два режима: ИЗОБРАЖЕНИЕ: Режим для ввода одного изображения. ВИДЕО: Режим декодирования кадров видео или потока входных данных в реальном времени, например, с камеры. | { IMAGE, VIDEO } | IMAGE |
num_hands | Устройство GestureRecognizer может распознать максимальное количество рук. | Any integer > 0 | 1 |
min_hand_detection_confidence | Минимальный показатель достоверности, необходимый для успешного обнаружения руки в модели распознавания ладони. | 0.0 - 1.0 | 0.5 |
min_hand_presence_confidence | Минимальный показатель достоверности наличия руки в модели обнаружения ориентиров руки. В режиме видео и режиме прямой трансляции Gesture Recognizer, если показатель достоверности наличия руки в модели обнаружения ориентиров руки ниже этого порога, запускается модель обнаружения ладони. В противном случае используется облегченный алгоритм отслеживания руки для определения местоположения руки (рук) для последующего обнаружения ориентиров. | 0.0 - 1.0 | 0.5 |
min_tracking_confidence | Минимальный показатель достоверности, при котором отслеживание руки считается успешным. Это пороговое значение IoU ограничивающей рамки между руками в текущем кадре и в предыдущем кадре. В видеорежиме и потоковом режиме распознавания жестов, если отслеживание не удается, распознаватель жестов запускает обнаружение рук. В противном случае обнаружение рук пропускается. | 0.0 - 1.0 | 0.5 |
canned_gestures_classifier_options | Параметры для настройки поведения классификатора стандартных жестов. Стандартные жесты: ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"] |
|
|
custom_gestures_classifier_options | Параметры для настройки поведения классификатора пользовательских жестов. |
|
|
Подготовка данных
Gesture Recognizer может распознавать жесты на изображениях в любом формате, поддерживаемом браузером. Задача также включает предварительную обработку входных данных, включая изменение размера, поворот и нормализацию значений. Для распознавания жестов в видео можно использовать API для быстрой обработки каждого кадра по отдельности, используя метку времени кадра для определения момента появления жестов в видео.
Запустите задачу
Распознаватель жестов использует методы recognize() (в режиме выполнения 'image' ) и recognizeForVideo() (в режиме выполнения 'video' ) для запуска процесса распознавания. Задача обрабатывает данные, пытается распознать жесты рук, а затем сообщает о результатах.
Следующий код демонстрирует, как выполнить обработку с использованием модели задач:
Изображение
const image = document.getElementById("image") as HTMLImageElement; const gestureRecognitionResult = gestureRecognizer.recognize(image);
Видео
await gestureRecognizer.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const gestureRecognitionResult = gestureRecognizer.recognizeForVideo(video); processResult(gestureRecognitionResult); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
Вызовы методов recognize() и recognizeForVideo() объекта Gesture Recognizer выполняются синхронно и блокируют поток пользовательского интерфейса. Если вы распознаете жесты в видеокадрах с камеры устройства, каждое распознавание будет блокировать основной поток. Этого можно избежать, реализовав веб-воркеры, которые будут запускать методы recognize() и recognizeForVideo() в другом потоке.
Более подробную информацию о реализации задачи распознавания жестов см. в примере .
Обработка и отображение результатов
Распознаватель жестов генерирует объект результата распознавания жестов для каждого запуска распознавания. Объект результата содержит координаты кисти в координатах изображения, координаты кисти в мировых координатах, информацию о ведущей руке (левая/правая) и категории жестов обнаруженных рук.
Ниже приведён пример выходных данных, полученных в результате выполнения этой задачи:
Полученный объект GestureRecognizerResult содержит четыре компонента, каждый из которых представляет собой массив, где каждый элемент содержит результат распознавания одной распознанной руки.
Правша/левша
Определение ведущей руки показывает, являются ли обнаруженные руки левой или правой.
Жесты
Распознанные категории жестов обнаруженных рук.
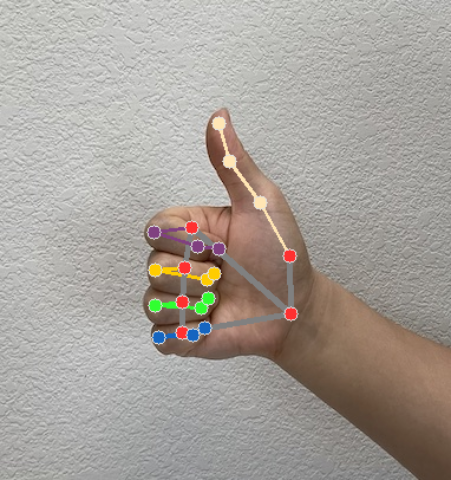
Достопримечательности
Имеется 21 контрольная точка на руке, каждая из которых состоит из координат
x,yиz. Координатыxиyнормализованы до диапазона [0,0, 1,0] с учетом ширины и высоты изображения соответственно. Координатаzпредставляет глубину контрольной точки, причем глубина на запястье является началом координат. Чем меньше значение, тем ближе контрольная точка к камере. Величинаzпримерно соответствует масштабуx.Всемирные достопримечательности
21 ориентир на руке также представлен в мировых координатах. Каждый ориентир состоит из
x,yиz, представляющих собой реальные трехмерные координаты в метрах с началом координат в геометрическом центре руки.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
На следующих изображениях представлена визуализация результатов выполнения задачи:
Более подробную информацию о создании задачи распознавания жестов см. в примере .