
يُعدّ التعامل مع استفسارات العملاء، بما في ذلك الرسائل الإلكترونية، جزءًا ضروريًا من إدارة العديد من الأنشطة التجارية، ولكن يمكن أن يصبح الأمر مرهقًا بسرعة. وببعض الجهد، يمكن أن تساعد نماذج الذكاء الاصطناعي، مثل Gemma، في تسهيل هذه المهمة.
تتعامل كل مؤسسة مع الاستفسارات، مثل الرسائل الإلكترونية، بشكل مختلف قليلاً، لذا من المهم أن تكون قادرًا على تكييف التكنولوجيات، مثل الذكاء الاصطناعي التوليدي، مع احتياجات مؤسستك. يتناول هذا المشروع المشكلة المحدّدة المتمثّلة في استخراج معلومات الطلبات من الرسائل الإلكترونية المرسَلة إلى مخبز وتحويلها إلى بيانات منظَّمة، ما يتيح إضافتها بسرعة إلى نظام معالجة الطلبات. باستخدام 10 إلى 20 مثالاً على الاستفسارات والنتائج التي تريدها، يمكنك ضبط نموذج Gemma لمعالجة الرسائل الإلكترونية الواردة من عملائك، والمساعدة في الرد عليها بسرعة، والدمج مع أنظمة عملك الحالية. تم إنشاء هذا المشروع كنمط لتطبيق الذكاء الاصطناعي يمكنك توسيعه وتكييفه للاستفادة من نماذج Gemma في مؤسستك.
للحصول على نظرة عامة على المشروع في فيديو وكيفية توسيعه، بما في ذلك إحصاءات من الفريق الذي أنشأه، يمكنك مشاهدة فيديو مساعد الذكاء الاصطناعي للبريد الإلكتروني الخاص بالأنشطة التجارية ضمن سلسلة Build with Google AI. يمكنك أيضًا مراجعة رمز هذا المشروع في مستودع رموز كتاب الطبخ الخاص بـ Gemma. وإلّا، يمكنك البدء في توسيع المشروع باتّباع التعليمات التالية.
نظرة عامة
يشرح لك هذا البرنامج التعليمي كيفية إعداد تطبيق مساعد للبريد الإلكتروني الخاص بالنشاط التجاري وتشغيله وتوسيع نطاقه، وهو تطبيق تم إنشاؤه باستخدام Gemma وPython وFlask. يوفّر المشروع واجهة مستخدم أساسية على الويب يمكنك تعديلها لتناسب احتياجاتك. تم تصميم التطبيق لاستخراج البيانات من رسائل البريد الإلكتروني للعملاء إلى بنية خاصة بمخبز وهمي. يمكنك استخدام نمط التطبيق هذا لأي مهمة تجارية تستخدم إدخال النص وإخراج النص.
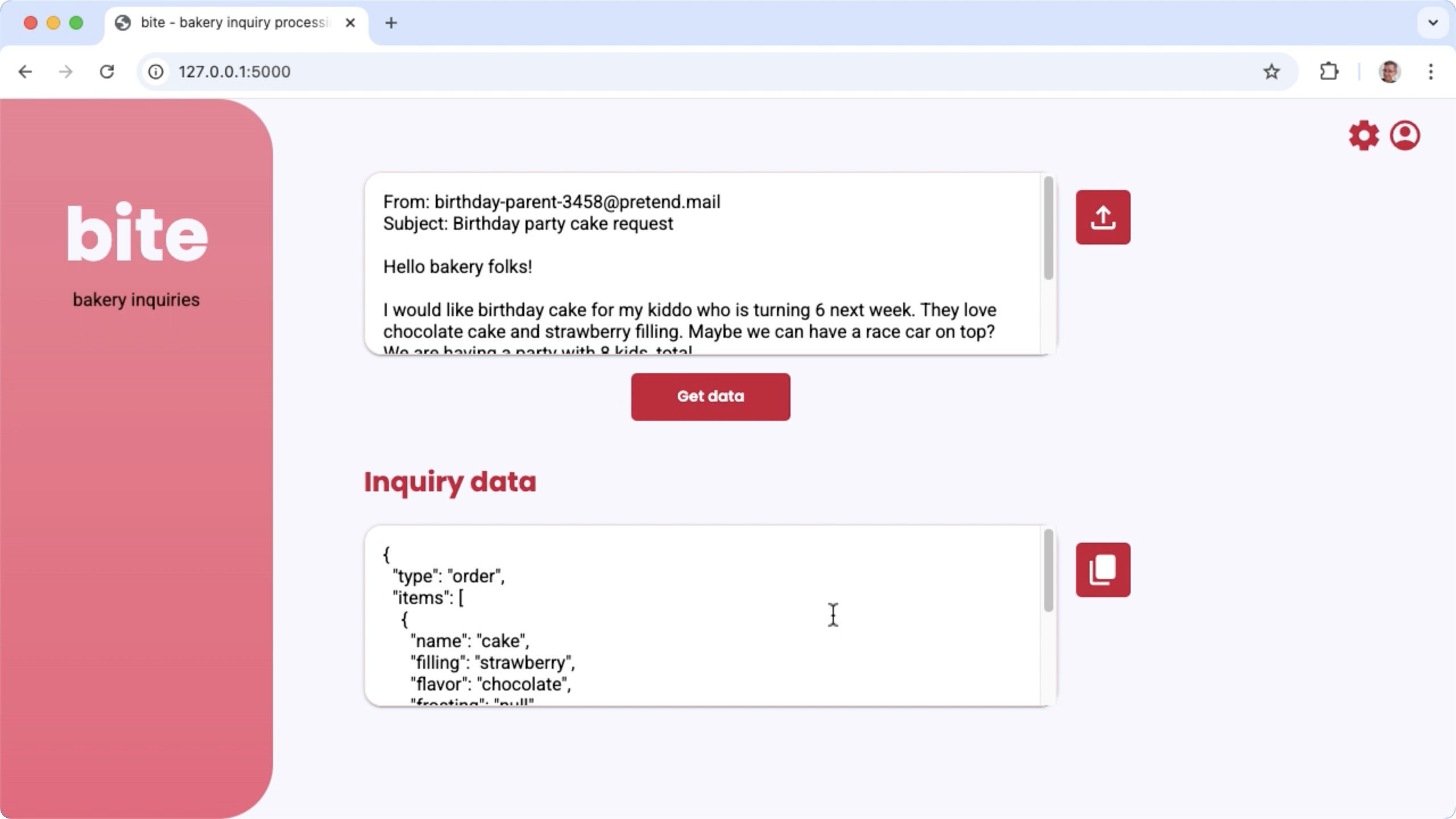
الشكل 1: واجهة مستخدم المشروع لمعالجة استفسارات البريد الإلكتروني الخاصة بالمخبز
متطلبات الأجهزة
يجب تنفيذ عملية الضبط هذه على جهاز كمبيوتر مزوّد بوحدة معالجة رسومات (GPU) أو وحدة معالجة الموتّرات (TPU)، مع توفّر مساحة كافية في ذاكرة وحدة معالجة الرسومات أو وحدة معالجة الموتّرات لتخزين النموذج الحالي بالإضافة إلى بيانات الضبط. لتشغيل إعدادات الضبط في هذا المشروع، تحتاج إلى ذاكرة وحدة معالجة الرسومات (GPU) بسعة 16 غيغابايت تقريبًا، ومساحة مماثلة من ذاكرة الوصول العشوائي (RAM) العادية، ومساحة على القرص لا تقل عن 50 غيغابايت.
يمكنك تنفيذ جزء ضبط نموذج Gemma في هذا البرنامج التعليمي باستخدام بيئة Colab مع بيئة تشغيل وحدة معالجة الرسومات T4. إذا كنت تنشئ هذا المشروع على جهاز افتراضي على Google Cloud، عليك إعداد الجهاز الافتراضي وفقًا للمتطلبات التالية:
- أجهزة وحدة معالجة الرسومات: يجب توفّر NVIDIA T4 لتشغيل هذا المشروع (يُنصح باستخدام NVIDIA L4 أو إصدار أحدث)
- نظام التشغيل: اختَر أحد خيارات التعلم العميق على نظام التشغيل Linux، وتحديدًا Deep Learning VM with CUDA 12.3 M124 مع برامج تشغيل برامج وحدة معالجة الرسومات المثبّتة مسبقًا.
- حجم قرص التشغيل: يجب توفير مساحة تخزين على القرص لا تقل عن 50 غيغابايت للبيانات والنماذج والبرامج الداعمة.
إعداد المشروع
توضّح لك هذه التعليمات كيفية إعداد هذا المشروع للتطوير والاختبار. تشمل خطوات الإعداد العامة تثبيت البرامج الأساسية المطلوبة، واستنساخ المشروع من مستودع الرموز البرمجية، وضبط بعض متغيرات البيئة، وتثبيت مكتبات Python، واختبار تطبيق الويب.
التثبيت والإعداد
يستخدم هذا المشروع الإصدار 3 من Python وVirtual Environments (venv) لإدارة الحِزم وتشغيل التطبيق. تعليمات التثبيت التالية مخصّصة لجهاز مضيف يعمل بنظام التشغيل Linux.
لتثبيت البرنامج المطلوب، اتّبِع الخطوات التالية:
ثبِّت الإصدار 3 من Python وحزمة البيئة الافتراضية
venvلـ Python:sudo apt update sudo apt install git pip python3-venv
استنساخ المشروع
نزِّل رمز المشروع إلى جهاز الكمبيوتر المخصّص للتطوير. يجب استخدام برنامج git للتحكّم في رمز المصدر من أجل استرداد رمز المصدر للمشروع.
لتنزيل رمز المشروع، اتّبِع الخطوات التالية:
استنسِخ مستودع git باستخدام الأمر التالي:
git clone https://github.com/google-gemini/gemma-cookbook.gitيمكنك اختياريًا ضبط مستودع git المحلي لاستخدام ميزة sparse checkout، بحيث لا يتضمّن سوى ملفات المشروع:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
تثبيت مكتبات Python
ثبِّت مكتبات Python مع تفعيل venv بيئة Python الافتراضية
لإدارة حِزم Python والتبعيات. تأكَّد من تفعيل البيئة الافتراضية للغة Python قبل تثبيت مكتبات Python باستخدام برنامج التثبيت pip. لمزيد من المعلومات حول استخدام البيئات الافتراضية في Python، يُرجى الاطّلاع على مستندات
Python venv.
لتثبيت مكتبات Python، اتّبِع الخطوات التالية:
في نافذة الوحدة الطرفية، انتقِل إلى الدليل
business-email-assistant:cd Demos/business-email-assistant/اضبط وفعِّل بيئة Python الافتراضية (venv) لهذا المشروع:
python3 -m venv venv source venv/bin/activateثبِّت مكتبات Python المطلوبة لهذا المشروع باستخدام النص البرمجي
setup_python:./setup_python.sh
ضبط متغيرات البيئة
يتطلّب هذا المشروع بعض متغيرات البيئة لتشغيله،
بما في ذلك اسم مستخدم على Kaggle ورمز مميّز لواجهة برمجة التطبيقات على Kaggle. يجب أن يكون لديك حساب على Kaggle وأن تطلب الوصول إلى نماذج Gemma لتتمكّن من تنزيلها. في هذا المشروع، ستضيف اسم مستخدمك على Kaggle ورمز Kaggle المميّز لواجهة برمجة التطبيقات إلى ملفَين .env
تقرأهما تطبيقات الويب وبرنامج الضبط، على التوالي.
لضبط متغيّرات البيئة، اتّبِع الخطوات التالية:
- احصل على اسم المستخدم ورمز الدخول في Kaggle باتّباع التعليمات الواردة في مستندات Kaggle.
- يمكنك الوصول إلى نموذج Gemma باتّباع التعليمات الواردة في صفحة إعداد Gemma ضمن الوصول إلى Gemma.
- أنشئ ملفات متغيرة للبيئة خاصة بالمشروع، وذلك عن طريق إنشاء ملف نصي
.envفي كل من المواقع التالية في نسخة المشروع التي نسختها:email-processing-webapp/.env model-tuning/.env
بعد إنشاء ملفات
.envالنصية، أضِف الإعدادات التالية إلى كلا الملفين:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
تشغيل التطبيق واختباره
بعد إكمال عملية تثبيت المشروع وإعداده، شغِّل تطبيق الويب للتأكّد من أنّك أعددته بشكل صحيح. يجب إجراء هذا الفحص الأساسي قبل تعديل المشروع لاستخدامك الخاص.
لتشغيل المشروع واختباره، اتّبِع الخطوات التالية:
في نافذة الوحدة الطرفية، انتقِل إلى الدليل
email-processing-webapp:cd business-email-assistant/email-processing-webapp/شغِّل التطبيق باستخدام النص البرمجي
run_app:./run_app.shبعد بدء تشغيل تطبيق الويب، يعرض رمز البرنامج عنوان URL يمكنك من خلاله التصفّح والاختبار. عادةً ما يكون هذا العنوان:
http://127.0.0.1:5000/في واجهة الويب، اضغط على الزر الحصول على البيانات أسفل حقل الإدخال الأول لإنشاء ردّ من النموذج.
يستغرق الردّ الأول من النموذج وقتًا أطول بعد تشغيل التطبيق، لأنّه يجب إكمال خطوات التهيئة عند تشغيل الجيل الأول. تستغرق طلبات إنشاء المحتوى اللاحقة على تطبيق ويب قيد التشغيل حاليًا وقتًا أقل.
تمديد فترة التطبيق
بعد تشغيل التطبيق، يمكنك توسيعه من خلال تعديل واجهة المستخدم ومنطق النشاط التجاري ليعمل مع المهام ذات الصلة بك أو بنشاطك التجاري. يمكنك أيضًا تعديل سلوك نموذج Gemma باستخدام رمز التطبيق من خلال تغيير مكوّنات الطلب الذي يرسله التطبيق إلى نموذج الذكاء الاصطناعي التوليدي.
يقدّم التطبيق تعليمات إلى النموذج مع بيانات الإدخال من المستخدم، وهو طلب كامل من النموذج. يمكنك تعديل هذه التعليمات لتغيير سلوك النموذج، مثل تحديد أسماء المَعلمات وبنية JSON التي سيتم إنشاؤها. يمكنك تغيير سلوك النموذج بطريقة أبسط من خلال تقديم تعليمات أو إرشادات إضافية بشأن رد النموذج، مثل تحديد أنّه يجب ألا تتضمّن الردود التي يتم إنشاؤها أي تنسيق Markdown.
لتعديل تعليمات الطلب:
- في مشروع التطوير، افتح ملف الرمز
business-email-assistant/email-processing-webapp/app.py. في الرمز
app.py، أضِف تعليمات إضافية إلى الدالةget_prompt()::def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
يضيف هذا المثال العبارة "بدون أي تنسيق إضافي بلغة الترميز Markdown" إلى التعليمات.
يمكن أن يؤثّر تقديم تعليمات إضافية في الطلب بشكل كبير في الناتج الذي يتم إنشاؤه، كما أنّ تنفيذها لا يتطلّب جهدًا كبيرًا. ننصحك بتجربة هذه الطريقة أولاً لمعرفة ما إذا كان بإمكانك الحصول على السلوك الذي تريده من النموذج. ومع ذلك، هناك حدود لاستخدام تعليمات الطلبات لتعديل سلوك نموذج Gemma. على وجه الخصوص، يتطلّب الحدّ الأقصى لعدد الرموز المميزة التي يمكن إدخالها في النموذج، وهو 8,192 رمزًا مميزًا في Gemma 2، منك تحقيق التوازن بين التعليمات التفصيلية في الطلب وحجم البيانات الجديدة التي تقدّمها لكي لا تتجاوز هذا الحدّ.
ضبط النموذج
يُنصح بتحسين نموذج Gemma ليصبح قادرًا على تقديم ردود أكثر موثوقية عند تنفيذ مهام معيّنة. على وجه الخصوص، إذا كنت تريد أن ينشئ النموذج ملف JSON ببنية معيّنة، بما في ذلك معلَمات تحمل أسماء محدّدة، عليك التفكير في ضبط النموذج على هذا السلوك. بناءً على المهمة التي تريد أن يكملها النموذج، يمكنك تحقيق وظائف أساسية باستخدام 10 إلى 20 مثالاً. يوضّح هذا القسم من البرنامج التعليمي كيفية إعداد عملية التحسين وتشغيلها على نموذج Gemma لتنفيذ مهمة معيّنة.
توضّح التعليمات التالية كيفية إجراء عملية الضبط الدقيق في بيئة آلة افتراضية، ولكن يمكنك أيضًا إجراء عملية الضبط هذه باستخدام مفكرة Colab المرتبطة بهذا المشروع.
متطلبات الأجهزة
متطلبات الحوسبة اللازمة لضبط النموذج بدقة هي نفسها متطلبات الأجهزة لبقية المشروع. يمكنك تنفيذ عملية الضبط الدقيق في بيئة Colab باستخدام بيئة تشغيل وحدة معالجة رسومات T4 إذا اقتصرت الرموز المميزة للإدخال على 256 وكان حجم الدفعة 1.
إعداد البيانات
قبل البدء في ضبط نموذج Gemma، عليك إعداد البيانات اللازمة لذلك. عند تحسين نموذج لأداء مهمة معيّنة، تحتاج إلى مجموعة من الأمثلة على الطلبات والاستجابات. يجب أن تعرض هذه الأمثلة نص الطلب بدون أي تعليمات ونص الاستجابة المتوقّع. للبدء، عليك إعداد مجموعة بيانات تتضمّن حوالي 10 أمثلة. يجب أن تمثّل هذه الأمثلة مجموعة كاملة من الطلبات والاستجابات المثالية. تأكَّد من أنّ الطلبات والردود ليست متكررة، لأنّ ذلك قد يؤدي إلى تكرار ردود النماذج وعدم تعديلها بشكل مناسب وفقًا للاختلافات في الطلبات. إذا كنت تريد ضبط النموذج لإنتاج تنسيق بيانات منظَّمة، تأكَّد من أنّ جميع الردود المقدَّمة تتوافق بدقة مع تنسيق إخراج البيانات الذي تريده. يعرض الجدول التالي بعض السجلات النموذجية من مجموعة بيانات مثال الرمز البرمجي هذا:
| طلب | الردّ |
|---|---|
| مرحبًا Indian Bakery Central،\nهل يتوفّر لديك 10 قطع من حلوى البيندا و30 قطعة من حلوى البوندي لادو؟ هل تبيعون أيضًا كعكات بنكهة الفانيليا والشوكولاتة؟ أبحث عن مقاس 6 بوصة | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| لقد رأيت نشاطك التجاري على "خرائط Google". هل تبيعون الجلابي والغولاب جامون؟ | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
الجدول 1. قائمة جزئية بمجموعة بيانات الضبط الخاصة بمستخرِج بيانات البريد الإلكتروني في المخبز.
تنسيق البيانات وتحميلها
يمكنك تخزين بيانات الضبط بأي تنسيق مناسب، بما في ذلك سجلات قاعدة البيانات أو ملفات JSON أو CSV أو ملفات نصية عادية، طالما لديك الوسائل اللازمة لاسترداد السجلات باستخدام رمز Python. يقرأ هذا المشروع ملفات JSON
من دليل data إلى مصفوفة من عناصر القاموس.
في برنامج الضبط هذا، يتم تحميل مجموعة بيانات الضبط في الوحدة model-tuning/main.py باستخدام الدالة prepare_tuning_dataset():
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
كما ذكرنا سابقًا، يمكنك تخزين مجموعة البيانات بتنسيق مناسب، طالما يمكنك استرداد الطلبات مع الردود المرتبطة بها وتجميعها في سلسلة نصية تُستخدَم كسجلّ ضبط.
تجميع سجلّات الضبط
أما بالنسبة إلى عملية الضبط الفعلية، فيقوم البرنامج بتجميع كل طلب ورد في سلسلة واحدة تتضمّن تعليمات الطلب ومحتوى الرد. بعد ذلك، يحوّل برنامج الضبط السلسلة إلى رموز مميّزة ليستخدمها النموذج. يمكنك الاطّلاع على الرمز البرمجي الخاص بتجميع سجلّ الضبط في الدالة model-tuning/main.py ضمن الوحدة prepare_tuning_dataset()، وذلك على النحو التالي:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
تأخذ هذه الدالة البيانات كمدخلات وتنسّقها من خلال إضافة فاصل أسطر بين التعليمات والرد.
إنشاء أوزان النموذج
بعد توفّر بيانات الضبط وتحميلها، يمكنك تشغيل برنامج الضبط. تستخدم عملية الضبط الدقيق لهذا التطبيق النموذجي مكتبة Keras NLP لضبط النموذج باستخدام تقنية Low Rank Adaptation أو LoRA، وذلك لإنشاء أوزان جديدة للنموذج. مقارنةً بعملية الضبط الدقيق الكاملة، يكون استخدام LoRA أكثر فعالية من حيث استهلاك الذاكرة لأنّه يقدّر التغييرات في أوزان النموذج. يمكنك بعد ذلك تطبيق هذه القيم التقريبية على قيم النموذج الحالية لتغيير سلوك النموذج.
لتنفيذ عملية الضبط وحساب الأوزان الجديدة، اتّبِع الخطوات التالية:
في نافذة الوحدة الطرفية، انتقِل إلى الدليل
model-tuning/.cd business-email-assistant/model-tuning/نفِّذ عملية الضبط باستخدام النص البرمجي
tune_model:./tune_model.sh
تستغرق عملية الضبط عدة دقائق حسب موارد الحوسبة المتاحة. عند اكتمال البرنامج بنجاح، يكتب برنامج الضبط ملفات أوزان جديدة *.h5
في الدليل model-tuning/weights بالتنسيق التالي:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
تحديد المشاكل وحلّها
إذا لم تكتمل عملية الضبط بنجاح، من المحتمل أن يكون أحد السببَين التاليَين هو السبب:
- نفاد الذاكرة أو استنفاد الموارد: تحدث هذه الأخطاء عندما تطلب عملية الضبط ذاكرة تتجاوز ذاكرة وحدة معالجة الرسومات أو ذاكرة وحدة المعالجة المركزية المتاحة. تأكَّد من عدم تشغيل تطبيق الويب أثناء عملية الضبط. إذا كنت تضبط الإعدادات على جهاز مزوّد بذاكرة وحدة معالجة الرسومات بسعة 16 غيغابايت، تأكَّد من ضبط قيمة
token_limitعلى 256 وقيمةbatch_sizeعلى 1. - عدم تثبيت برامج تشغيل وحدة معالجة الرسومات أو عدم توافقها مع JAX: تتطلّب عملية الضبط توفّر برامج تشغيل للأجهزة على جهاز الحوسبة تكون متوافقة مع إصدار مكتبات JAX. لمزيد من التفاصيل، يُرجى الاطّلاع على مستندات تثبيت JAX.
نشر النموذج المعدَّل
تنتج عملية الضبط أوزانًا متعددة استنادًا إلى بيانات الضبط وإجمالي عدد الدورات المحدّد في تطبيق الضبط. بشكل تلقائي، ينشئ برنامج الضبط ثلاثة ملفات لوزن النموذج، ملف واحد لكل حقبة ضبط. تنتج كل حقبة ضبط متتالية أوزانًا تعيد إنتاج نتائج بيانات الضبط بدقة أكبر. يمكنك الاطّلاع على معدّلات الدقة لكل حقبة في ناتج عملية الضبط في نافذة الجهاز الطرفي، كما يلي:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
مع أنّك تريد أن تكون نسبة الدقة مرتفعة نسبيًا، أي حوالي 0.80، إلا أنّك لا تريد أن تكون النسبة مرتفعة جدًا أو قريبة جدًا من 1.00، لأنّ ذلك يعني أنّ الأوزان أصبحت قريبة من الإفراط في ملاءمة بيانات الضبط. وعندما يحدث ذلك، لا يحقّق النموذج أداءً جيدًا في الطلبات التي تختلف بشكل كبير عن أمثلة الضبط. يختار نص البرمجة الخاص بالنشر تلقائيًا أوزان الحقبة 3، والتي تتضمّن عادةً معدّل دقة يبلغ 0.80 تقريبًا.
لنشر الأوزان التي تم إنشاؤها إلى تطبيق الويب، اتّبِع الخطوات التالية:
في نافذة الوحدة الطرفية، انتقِل إلى الدليل
model-tuning:cd business-email-assistant/model-tuning/نفِّذ عملية الضبط باستخدام النص البرمجي
deploy_weights:./deploy_weights.sh
بعد تشغيل هذا النص البرمجي، من المفترض أن يظهر ملف *.h5 جديد في الدليل email-processing-webapp/weights/.
اختبار النموذج الجديد
بعد نشر الأوزان الجديدة في التطبيق، حان الوقت لتجربة النموذج الذي تم ضبطه حديثًا. يمكنك إجراء ذلك من خلال إعادة تشغيل تطبيق الويب وإنشاء ردّ.
لتشغيل المشروع واختباره، اتّبِع الخطوات التالية:
في نافذة الوحدة الطرفية، انتقِل إلى الدليل
email-processing-webapp:cd business-email-assistant/email-processing-webapp/شغِّل التطبيق باستخدام النص البرمجي
run_app:./run_app.shبعد بدء تشغيل تطبيق الويب، يعرض رمز البرنامج عنوان URL يمكنك من خلاله التصفّح والاختبار، وعادةً ما يكون هذا العنوان هو:
http://127.0.0.1:5000/في واجهة الويب، اضغط على الزر الحصول على البيانات أسفل حقل الإدخال الأول لإنشاء ردّ من النموذج.
لقد تم الآن ضبط نموذج Gemma ونشره في أحد التطبيقات. جرِّب التطبيق وحاوِل تحديد حدود قدرة النموذج المضبوط على إنشاء المحتوى الخاص بمهمتك. إذا صادفت سيناريوهات لا يحقّق فيها النموذج أداءً جيدًا، ننصحك بإضافة بعض هذه الطلبات إلى قائمة البيانات النموذجية الخاصة بالتحسين من خلال إضافة الطلب وتقديم ردّ مثالي. بعد ذلك، أعِد تشغيل عملية الضبط وأعِد نشر الأوزان الجديدة واختبِر الناتج.
مراجع إضافية
لمزيد من المعلومات حول هذا المشروع، يُرجى الاطّلاع على مستودع رموز Gemma Cookbook. إذا كنت بحاجة إلى مساعدة في إنشاء التطبيق أو كنت تبحث عن التعاون مع مطوّرين آخرين، يمكنك الانتقال إلى خادم Google Developers Community Discord. للاطّلاع على المزيد من المشاريع ضمن "البناء باستخدام الذكاء الاصطناعي من Google"، يمكنك استكشاف قائمة تشغيل الفيديو.