
Le traitement des demandes des clients, y compris des e-mails, est une partie nécessaire de la gestion de nombreuses entreprises, mais il peut rapidement devenir accablant. Avec un peu d'effort, les modèles d'intelligence artificielle (IA) comme Gemma peuvent vous aider à simplifier ce travail.
Chaque entreprise gère les demandes comme les e-mails un peu différemment. Il est donc important de pouvoir adapter les technologies comme l'IA générative aux besoins de votre entreprise. Ce projet s'attaque au problème spécifique de l'extraction des informations de commande à partir d'e-mails envoyés à une boulangerie pour les transformer en données structurées, afin qu'elles puissent être rapidement ajoutées à un système de gestion des commandes. En utilisant 10 à 20 exemples de requêtes et le résultat souhaité, vous pouvez ajuster un modèle Gemma pour traiter les e-mails de vos clients, vous aider à répondre rapidement et l'intégrer à vos systèmes d'entreprise existants. Ce projet est conçu comme un modèle d'application d'IA que vous pouvez étendre et adapter pour tirer parti des modèles Gemma pour votre entreprise.
Pour obtenir une présentation vidéo du projet et découvrir comment l'étendre, y compris des informations fournies par les personnes qui l'ont créé, consultez la vidéo Assistant IA pour les e-mails professionnels sur Build with Google AI. Vous pouvez également consulter le code de ce projet dans le dépôt de code du cookbook Gemma. Sinon, vous pouvez commencer à étendre le projet en suivant les instructions ci-dessous.
Présentation
Ce tutoriel vous explique comment configurer, exécuter et étendre une application d'assistance pour les e-mails professionnels conçue avec Gemma, Python et Flask. Le projet fournit une interface utilisateur Web de base que vous pouvez modifier pour l'adapter à vos besoins. L'application est conçue pour extraire les données des e-mails des clients dans une structure pour une boulangerie fictive. Vous pouvez utiliser ce modèle d'application pour n'importe quelle tâche métier qui utilise des entrées et des sorties de texte.
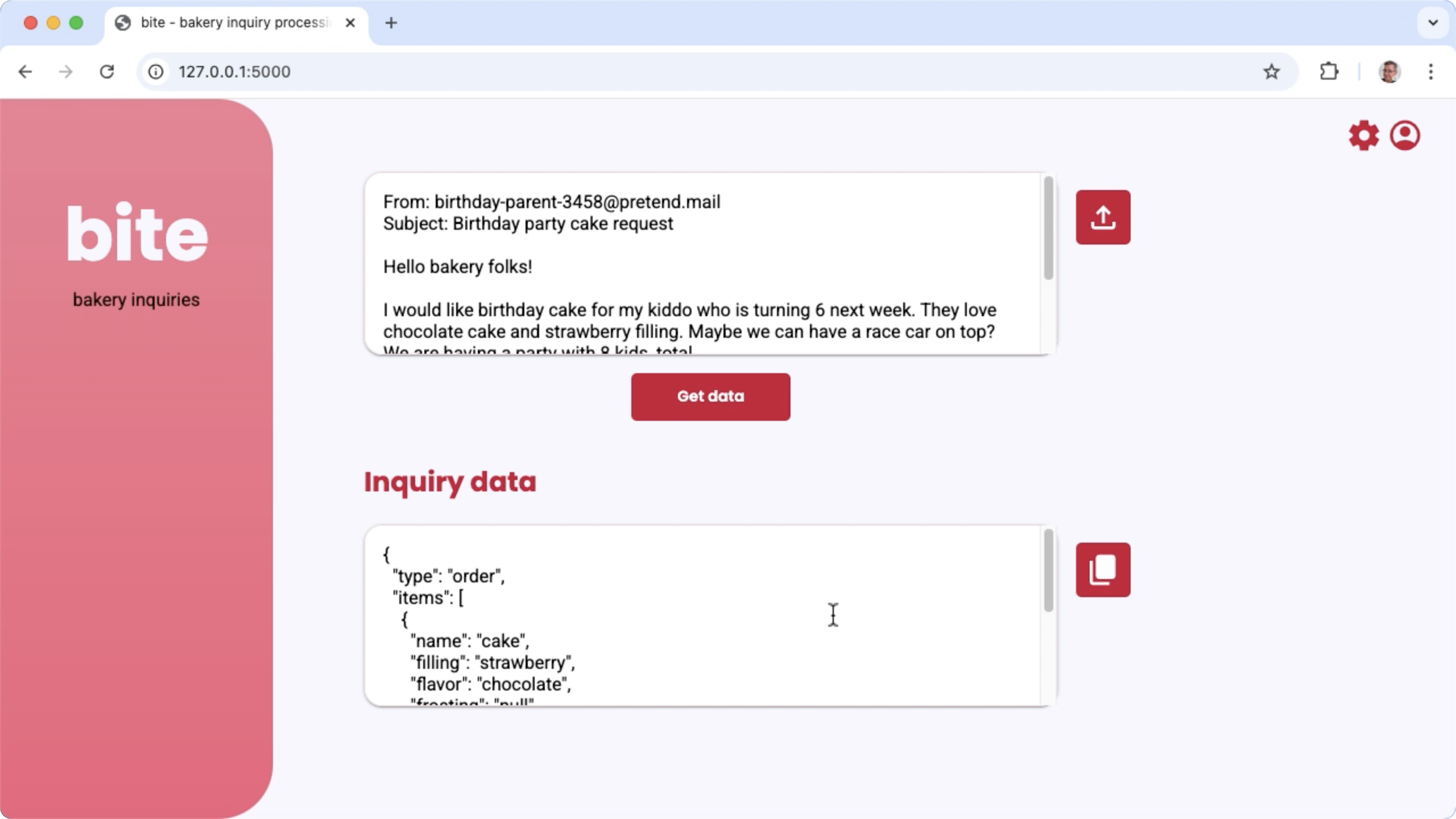
Figure 1. Interface utilisateur du projet pour traiter les demandes par e-mail concernant la boulangerie
Matériel requis
Exécutez ce processus d'ajustement sur un ordinateur doté d'un processeur graphique (GPU) ou d'un Tensor Processing Unit (TPU), et d'une mémoire GPU ou TPU suffisante pour contenir le modèle existant, ainsi que les données d'ajustement. Pour exécuter la configuration de réglage dans ce projet, vous avez besoin d'environ 16 Go de mémoire GPU, d'environ la même quantité de RAM normale et d'au moins 50 Go d'espace disque.
Vous pouvez exécuter la partie du tutoriel sur l'ajustement du modèle Gemma à l'aide d'un environnement Colab avec un GPU T4. Si vous créez ce projet sur une instance de VM Google Cloud, configurez l'instance en respectant les exigences suivantes :
- Matériel GPU : un GPU NVIDIA T4 est requis pour exécuter ce projet (NVIDIA L4 ou version ultérieure recommandé).
- Système d'exploitation : sélectionnez une option Deep Learning sur Linux, plus précisément Deep Learning VM avec CUDA 12.3 M124 avec des pilotes logiciels de GPU préinstallés.
- Taille du disque de démarrage : prévoyez au moins 50 Go d'espace disque pour vos données, vos modèles et les logiciels associés.
Configuration du projet
Ces instructions vous expliquent comment préparer ce projet pour le développement et les tests. Les étapes de configuration générales incluent l'installation des logiciels requis, le clonage du projet à partir du dépôt de code, la définition de quelques variables d'environnement, l'installation des bibliothèques Python et le test de l'application Web.
Installer et configurer
Ce projet utilise Python 3 et des environnements virtuels (venv) pour gérer les packages et exécuter l'application. Les instructions d'installation suivantes concernent une machine hôte Linux.
Pour installer le logiciel requis :
Installez Python 3 et le package d'environnement virtuel
venvpour Python :sudo apt update sudo apt install git pip python3-venv
Cloner le projet
Téléchargez le code du projet sur votre ordinateur de développement. Vous avez besoin du logiciel de contrôle du code source git pour récupérer le code source du projet.
Pour télécharger le code du projet :
Clonez le dépôt Git à l'aide de la commande suivante :
git clone https://github.com/google-gemini/gemma-cookbook.gitVous pouvez également configurer votre dépôt Git local pour qu'il utilise l'extraction éparse, afin de ne disposer que des fichiers du projet :
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
Installer les bibliothèques Python
Installez les bibliothèques Python avec l'environnement virtuel Python venv activé pour gérer les packages et les dépendances Python. Assurez-vous d'activer l'environnement virtuel Python avant d'installer les bibliothèques Python avec le programme d'installation pip. Pour en savoir plus sur l'utilisation des environnements virtuels Python, consultez la documentation Python venv.
Pour installer les bibliothèques Python :
Dans une fenêtre de terminal, accédez au répertoire
business-email-assistant:cd Demos/business-email-assistant/Configurez et activez un environnement virtuel Python (venv) pour ce projet :
python3 -m venv venv source venv/bin/activateInstallez les bibliothèques Python requises pour ce projet à l'aide du script
setup_python:./setup_python.sh
Définir des variables d'environnement
Ce projet nécessite l'exécution de quelques variables d'environnement, y compris un nom d'utilisateur Kaggle et un jeton d'API Kaggle. Vous devez disposer d'un compte Kaggle et demander l'accès aux modèles Gemma pour pouvoir les télécharger. Pour ce projet, vous devez ajouter votre nom d'utilisateur Kaggle et votre jeton d'API Kaggle à deux fichiers .env, qui sont lus respectivement par l'application Web et le programme de réglage.
Pour définir les variables d'environnement :
- Obtenez votre nom d'utilisateur et votre clé jeton Kaggle en suivant les instructions de la documentation Kaggle.
- Accédez au modèle Gemma en suivant les instructions de la section Accéder à Gemma sur la page Configuration de Gemma.
- Créez des fichiers de variables d'environnement pour le projet en créant un fichier texte
.envà chacun des emplacements suivants dans votre clone du projet :email-processing-webapp/.env model-tuning/.env
Après avoir créé les fichiers texte
.env, ajoutez les paramètres suivants aux deux fichiers :KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Exécuter et tester l'application
Une fois l'installation et la configuration du projet terminées, exécutez l'application Web pour vérifier que vous l'avez configurée correctement. Vous devez effectuer cette vérification de base avant de modifier le projet pour votre propre usage.
Pour exécuter et tester le projet :
Dans une fenêtre de terminal, accédez au répertoire
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Exécutez l'application à l'aide du script
run_app:./run_app.shUne fois l'application Web démarrée, le code du programme liste une URL que vous pouvez parcourir et tester. Cette adresse est généralement :
http://127.0.0.1:5000/Dans l'interface Web, appuyez sur le bouton Obtenir des données sous le premier champ d'entrée pour générer une réponse du modèle.
La première réponse du modèle après l'exécution de l'application prend plus de temps, car il doit effectuer des étapes d'initialisation lors de la première exécution de la génération. Les demandes et la génération de requêtes ultérieures sur une application Web déjà en cours d'exécution prennent moins de temps.
Étendre l'application
Une fois l'application en cours d'exécution, vous pouvez l'étendre en modifiant l'interface utilisateur et la logique métier pour qu'elle fonctionne pour les tâches qui vous intéressent ou qui intéressent votre entreprise. Vous pouvez également modifier le comportement du modèle Gemma à l'aide du code de l'application en modifiant les composants de la requête que l'application envoie au modèle d'IA générative.
L'application fournit des instructions au modèle ainsi que les données d'entrée de l'utilisateur, ce qui constitue une requête complète pour le modèle. Vous pouvez modifier ces instructions pour changer le comportement du modèle, par exemple en spécifiant les noms des paramètres et la structure du fichier JSON à générer. Pour modifier plus facilement le comportement du modèle, vous pouvez lui fournir des instructions ou des conseils supplémentaires pour sa réponse, par exemple en précisant que les réponses générées ne doivent pas inclure de mise en forme Markdown.
Pour modifier les instructions du prompt :
- Dans le projet de développement, ouvrez le fichier de code
business-email-assistant/email-processing-webapp/app.py. Dans le code
app.py, ajoutez des instructions à la fonctionget_prompt()::def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
Cet exemple ajoute l'expression "sans mise en forme Markdown supplémentaire" aux instructions.
Fournir des instructions supplémentaires dans la requête peut avoir une forte influence sur le résultat généré et demande beaucoup moins d'efforts à mettre en œuvre. Vous devez d'abord essayer cette méthode pour voir si vous pouvez obtenir le comportement souhaité du modèle. Toutefois, l'utilisation d'instructions d'invite pour modifier le comportement d'un modèle Gemma a ses limites. En particulier, la limite globale de jetons d'entrée du modèle, qui est de 8 192 jetons pour Gemma 2, vous oblige à trouver un équilibre entre les instructions détaillées de l'invite et la taille des nouvelles données que vous fournissez afin de ne pas dépasser cette limite.
Régler le modèle
L'affinage d'un modèle Gemma est la méthode recommandée pour qu'il réponde de manière plus fiable à des tâches spécifiques. En particulier, si vous souhaitez que le modèle génère du code JSON avec une structure spécifique, y compris des paramètres nommés, vous devez envisager d'ajuster le modèle pour ce comportement. En fonction de la tâche que vous souhaitez que le modèle effectue, vous pouvez obtenir des fonctionnalités de base avec 10 à 20 exemples. Cette section du tutoriel explique comment configurer et exécuter l'affinage d'un modèle Gemma pour une tâche spécifique.
Les instructions suivantes expliquent comment effectuer l'opération d'affinage dans un environnement de VM. Toutefois, vous pouvez également effectuer cette opération d'affinage à l'aide du notebook Colab associé à ce projet.
Matériel requis
Les exigences de calcul pour le réglage fin sont les mêmes que les exigences matérielles pour le reste du projet. Vous pouvez exécuter l'opération de réglage dans un environnement Colab avec un GPU T4 si vous limitez les jetons d'entrée à 256 et la taille du lot à 1.
Préparer les données
Avant de commencer à régler un modèle Gemma, vous devez préparer les données pour le réglage. Lorsque vous ajustez un modèle pour une tâche spécifique, vous avez besoin d'un ensemble d'exemples de requêtes et de réponses. Ces exemples doivent afficher le texte de la requête, sans aucune instruction, et le texte de la réponse attendue. Pour commencer, vous devez préparer un ensemble de données contenant une dizaine d'exemples. Ces exemples doivent représenter une grande variété de requêtes et les réponses idéales. Assurez-vous que les requêtes et les réponses ne sont pas répétitives, car cela peut entraîner des réponses répétitives du modèle et l'empêcher de s'adapter correctement aux variations des requêtes. Si vous ajustez le modèle pour qu'il produise un format de données structurées, assurez-vous que toutes les réponses fournies respectent strictement le format de données de sortie souhaité. Le tableau suivant présente quelques exemples d'enregistrements de l'ensemble de données de cet exemple de code :
| Requête | Réponse |
|---|---|
| Bonjour Indian Bakery Central,\nAuriez-vous 10 pendas et 30 bundi ladoos à disposition ? Vendez-vous également des gâteaux à la vanille et au chocolat ? Je cherche une taille de 15 cm. | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| J'ai vu votre établissement sur Google Maps. Vendez-vous des jellabi et des gulab jamun ? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
Tableau 1. Liste partielle de l'ensemble de données de réglage pour l'extracteur de données d'e-mails de boulangerie.
Format et chargement des données
Vous pouvez stocker vos données d'ajustement dans n'importe quel format qui vous convient, y compris les enregistrements de base de données, les fichiers JSON, les fichiers CSV ou les fichiers en texte brut, à condition que vous puissiez récupérer les enregistrements avec du code Python. Ce projet lit les fichiers JSON d'un répertoire data dans un tableau d'objets de dictionnaire.
Dans cet exemple de programme d'optimisation, l'ensemble de données d'optimisation est chargé dans le module model-tuning/main.py à l'aide de la fonction prepare_tuning_dataset() :
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
Comme indiqué précédemment, vous pouvez stocker l'ensemble de données dans un format qui vous convient, à condition de pouvoir récupérer les requêtes avec les réponses associées et de les assembler en une chaîne de texte qui sera utilisée comme enregistrement de réglage.
Assembler les enregistrements de réglage
Pour le processus d'ajustement proprement dit, le programme assemble chaque requête et réponse en une seule chaîne avec les instructions de l'invite et le contenu de la réponse. Le programme de réglage tokenise ensuite la chaîne pour que le modèle puisse l'utiliser. Vous pouvez consulter le code permettant d'assembler un enregistrement de réglage dans la fonction prepare_tuning_dataset() du module model-tuning/main.py, comme suit :
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
Cette fonction prend les données comme entrée et les met en forme en ajoutant un saut de ligne entre l'instruction et la réponse.
Générer des pondérations de modèle
Une fois que vous avez les données de réglage en place et chargées, vous pouvez exécuter le programme de réglage. Le processus de réglage de cet exemple d'application utilise la bibliothèque Keras NLP pour régler le modèle avec une adaptation à faible rang, ou technique LoRA, afin de générer de nouveaux poids de modèle. Par rapport au réglage de précision complète, l'utilisation de LoRA est beaucoup plus efficace en termes de mémoire, car elle permet d'approximer les modifications apportées aux pondérations du modèle. Vous pouvez ensuite superposer ces pondérations approximatives sur les pondérations de modèle existantes pour modifier le comportement du modèle.
Pour effectuer l'exécution du réglage et calculer de nouveaux poids :
Dans une fenêtre de terminal, accédez au répertoire
model-tuning/.cd business-email-assistant/model-tuning/Exécutez le processus d'optimisation à l'aide du script
tune_model:./tune_model.sh
Le processus d'optimisation prend plusieurs minutes en fonction des ressources de calcul disponibles. Une fois le programme d'ajustement terminé, il écrit de nouveaux fichiers de poids *.h5 dans le répertoire model-tuning/weights au format suivant :
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
Dépannage
Si le réglage ne s'est pas terminé correctement, deux raisons sont probables :
- Mémoire insuffisante ou ressources épuisées : ces erreurs se produisent lorsque le processus d'optimisation demande une quantité de mémoire supérieure à la mémoire GPU ou CPU disponible. Assurez-vous de ne pas exécuter l'application Web pendant le processus de réglage. Si vous effectuez un réglage sur un appareil doté de 16 Go de mémoire GPU, assurez-vous que
token_limitest défini sur 256 et quebatch_sizeest défini sur 1. - Pilotes de GPU non installés ou incompatibles avec JAX : le processus d'optimisation nécessite que le périphérique de calcul dispose de pilotes matériels installés et compatibles avec la version des bibliothèques JAX. Pour en savoir plus, consultez la documentation sur l'installation de JAX.
Déployer le modèle réglé
Le processus d'optimisation génère plusieurs pondérations en fonction des données d'optimisation et du nombre total d'époques défini dans l'application d'optimisation. Par défaut, le programme d'ajustement génère trois fichiers de pondération de modèle, un pour chaque époque d'ajustement. Chaque époque d'ajustement successive produit des pondérations qui reproduisent plus précisément les résultats des données d'ajustement. Vous pouvez consulter les taux de précision pour chaque époque dans la sortie du terminal du processus d'optimisation, comme suit :
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
Bien que vous souhaitiez que le taux de précision soit relativement élevé (environ 0, 80), vous ne voulez pas qu'il soit trop élevé ni très proche de 1, 00, car cela signifie que les pondérations se sont rapprochées du surapprentissage des données de réglage. Dans ce cas, le modèle ne fonctionne pas bien pour les requêtes qui sont très différentes des exemples d'ajustement. Par défaut, le script de déploiement sélectionne les pondérations de l'époque 3, qui ont généralement un taux de précision d'environ 0,80.
Pour déployer les poids générés dans l'application Web :
Dans une fenêtre de terminal, accédez au répertoire
model-tuning:cd business-email-assistant/model-tuning/Exécutez le processus d'optimisation à l'aide du script
deploy_weights:./deploy_weights.sh
Après avoir exécuté ce script, vous devriez voir un nouveau fichier *.h5 dans le répertoire email-processing-webapp/weights/.
Tester le nouveau modèle
Une fois que vous avez déployé les nouveaux poids dans l'application, il est temps d'essayer le modèle nouvellement ajusté. Pour ce faire, réexécutez l'application Web et générez une réponse.
Pour exécuter et tester le projet :
Dans une fenêtre de terminal, accédez au répertoire
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Exécutez l'application à l'aide du script
run_app:./run_app.shUne fois l'application Web démarrée, le code du programme liste une URL où vous pouvez naviguer et tester. Cette adresse est généralement la suivante :
http://127.0.0.1:5000/Dans l'interface Web, appuyez sur le bouton Obtenir des données sous le premier champ d'entrée pour générer une réponse du modèle.
Vous avez maintenant ajusté et déployé un modèle Gemma dans une application. Testez l'application et essayez de déterminer les limites de la capacité de génération du modèle ajusté pour votre tâche. Si vous identifiez des scénarios dans lesquels le modèle ne fonctionne pas bien, envisagez d'ajouter certaines de ces requêtes à votre liste de données d'exemple pour l'ajustement. Pour ce faire, ajoutez la requête et fournissez une réponse idéale. Ensuite, réexécutez le processus d'ajustement, redéployez les nouveaux poids et testez le résultat.
Ressources supplémentaires
Pour en savoir plus sur ce projet, consultez le dépôt de code Gemma Cookbook. Si vous avez besoin d'aide pour créer l'application ou si vous souhaitez collaborer avec d'autres développeurs, consultez le serveur Discord de la communauté Google Developers. Pour découvrir d'autres projets Build with Google AI, consultez la playlist de vidéos.