
Xử lý thắc mắc của khách hàng, bao gồm cả email, là một phần cần thiết trong việc điều hành nhiều doanh nghiệp, nhưng việc này có thể nhanh chóng trở nên quá tải. Với một chút nỗ lực, các mô hình trí tuệ nhân tạo (AI) như Gemma có thể giúp bạn thực hiện công việc này dễ dàng hơn.
Mỗi doanh nghiệp xử lý các câu hỏi như email theo cách riêng, vì vậy, bạn cần có khả năng điều chỉnh các công nghệ như AI tạo sinh cho phù hợp với nhu cầu của doanh nghiệp mình. Dự án này giải quyết vấn đề cụ thể là trích xuất thông tin đơn đặt hàng từ email gửi đến một tiệm bánh thành dữ liệu có cấu trúc, để có thể nhanh chóng thêm vào hệ thống xử lý đơn đặt hàng. Bằng cách sử dụng từ 10 đến 20 ví dụ về câu hỏi và kết quả bạn muốn, bạn có thể điều chỉnh một mô hình Gemma để xử lý email của khách hàng, giúp bạn phản hồi nhanh chóng và tích hợp với các hệ thống kinh doanh hiện có. Dự án này được xây dựng dưới dạng một mẫu ứng dụng AI mà bạn có thể mở rộng và điều chỉnh để khai thác giá trị từ các mô hình Gemma cho doanh nghiệp của mình.
Để xem video tổng quan về dự án và cách mở rộng dự án, bao gồm cả thông tin chi tiết từ những người đã xây dựng dự án này, hãy xem video Trợ lý AI cho email doanh nghiệp của Build with Google AI. Bạn cũng có thể xem lại mã của dự án này trong kho lưu trữ mã Gemma Cookbook. Nếu không, bạn có thể bắt đầu mở rộng dự án theo hướng dẫn sau.
Tổng quan
Hướng dẫn này sẽ hướng dẫn bạn cách thiết lập, chạy và mở rộng một ứng dụng trợ lý email doanh nghiệp được xây dựng bằng Gemma, Python và Flask. Dự án này cung cấp một giao diện người dùng web cơ bản mà bạn có thể sửa đổi cho phù hợp với nhu cầu của mình. Ứng dụng này được xây dựng để trích xuất dữ liệu từ email của khách hàng vào một cấu trúc cho một tiệm bánh giả tưởng. Bạn có thể sử dụng mẫu ứng dụng này cho mọi tác vụ kinh doanh sử dụng đầu vào văn bản và đầu ra văn bản.
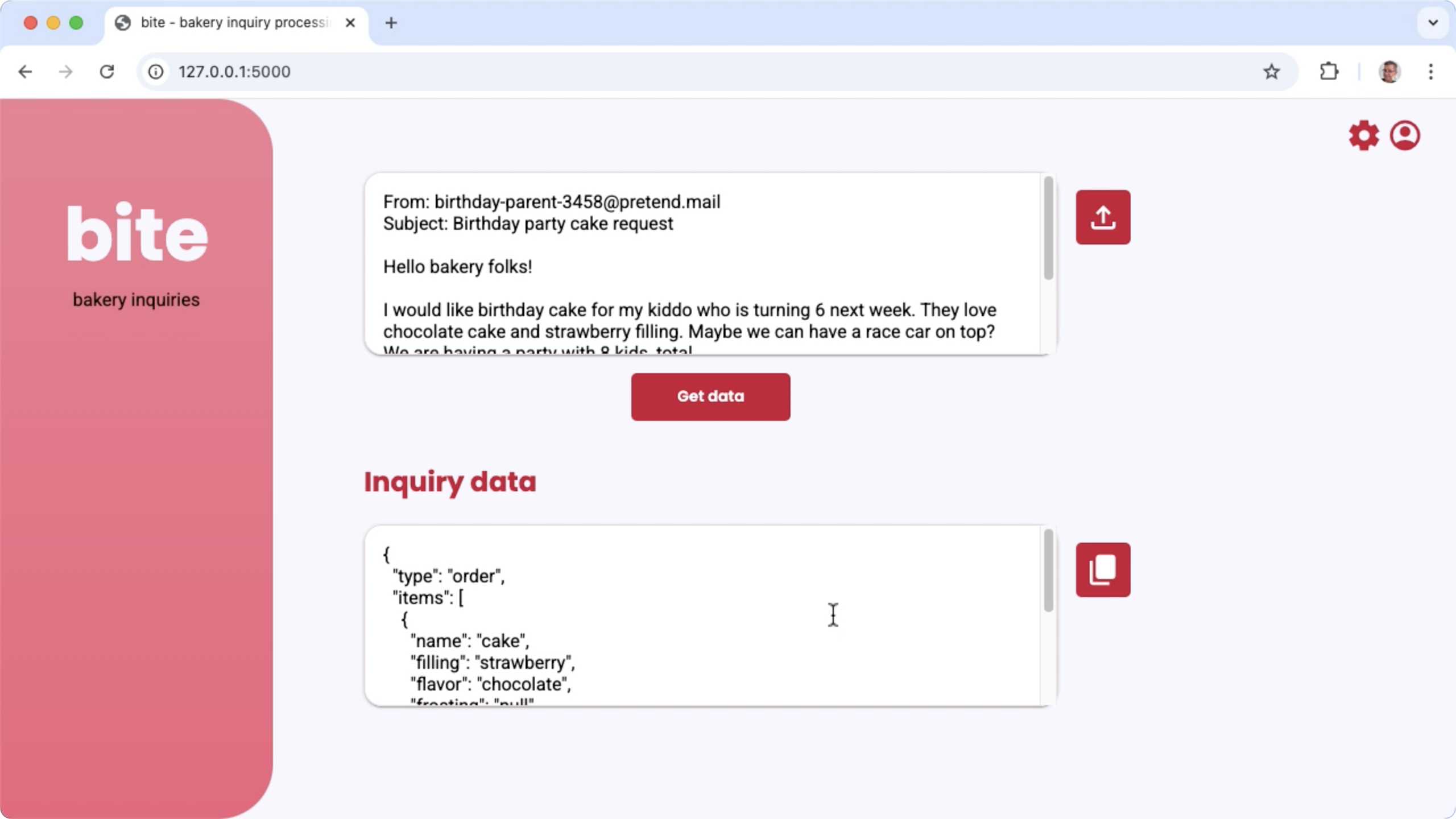
Hình 1. Giao diện người dùng của dự án để xử lý các thắc mắc về email của tiệm bánh
Yêu cầu về phần cứng
Chạy quy trình điều chỉnh này trên máy tính có bộ xử lý đồ hoạ (GPU) hoặc bộ xử lý Tensor (TPU) và đủ bộ nhớ GPU hoặc TPU để lưu trữ mô hình hiện có, cộng với dữ liệu điều chỉnh. Để chạy cấu hình điều chỉnh trong dự án này, bạn cần khoảng 16 GB bộ nhớ GPU, khoảng cùng lượng RAM thông thường và tối thiểu 50 GB dung lượng ổ đĩa.
Bạn có thể chạy phần điều chỉnh mô hình Gemma trong hướng dẫn này bằng môi trường Colab có thời gian chạy GPU T4. Nếu bạn đang tạo dự án này trên một phiên bản máy ảo Google Cloud, hãy định cấu hình phiên bản theo các yêu cầu sau:
- Phần cứng GPU: Bạn cần có NVIDIA T4 để chạy dự án này (nên dùng NVIDIA L4 trở lên)
- Hệ điều hành: Chọn một lựa chọn Học sâu trên Linux, cụ thể là Deep Learning VM có CUDA 12.3 M124 với trình điều khiển phần mềm GPU đã cài đặt sẵn.
- Kích thước ổ đĩa khởi động: Cung cấp ít nhất 50 GB dung lượng ổ đĩa cho dữ liệu, mô hình và phần mềm hỗ trợ của bạn.
Thiết lập dự án
Hướng dẫn này sẽ hướng dẫn bạn cách chuẩn bị dự án này cho quá trình phát triển và kiểm thử. Các bước thiết lập chung bao gồm cài đặt phần mềm bắt buộc, sao chép dự án từ kho lưu trữ mã, thiết lập một số biến môi trường, cài đặt thư viện Python và kiểm thử ứng dụng web.
Cài đặt và định cấu hình
Dự án này sử dụng Python 3 và Môi trường ảo (venv) để quản lý các gói và chạy ứng dụng. Sau đây là hướng dẫn cài đặt dành cho máy chủ Linux.
Cách cài đặt phần mềm cần thiết:
Cài đặt Python 3 và gói môi trường ảo
venvcho Python:sudo apt update sudo apt install git pip python3-venv
Sao chép dự án
Tải mã nguồn dự án xuống máy tính phát triển của bạn. Bạn cần phần mềm kiểm soát nguồn git để truy xuất mã nguồn dự án.
Cách tải mã nguồn dự án xuống:
Sao chép kho lưu trữ git bằng lệnh sau:
git clone https://github.com/google-gemini/gemma-cookbook.gitBạn có thể tuỳ ý định cấu hình kho lưu trữ git cục bộ để sử dụng tính năng kiểm xuất thưa thớt, nhờ đó bạn chỉ có các tệp cho dự án:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
Cài đặt thư viện Python
Cài đặt các thư viện Python bằng môi trường ảo Python venv đã kích hoạt để quản lý các gói và phần phụ thuộc Python. Hãy nhớ kích hoạt môi trường ảo Python trước khi cài đặt các thư viện Python bằng trình cài đặt pip. Để biết thêm thông tin về cách sử dụng môi trường ảo Python, hãy xem tài liệu về venv Python.
Cách cài đặt thư viện Python:
Trong cửa sổ dòng lệnh, hãy chuyển đến thư mục
business-email-assistant:cd Demos/business-email-assistant/Định cấu hình và kích hoạt môi trường ảo Python (venv) cho dự án này:
python3 -m venv venv source venv/bin/activateCài đặt các thư viện Python cần thiết cho dự án này bằng tập lệnh
setup_python:./setup_python.sh
Đặt các biến môi trường
Dự án này cần một số biến môi trường để chạy, bao gồm cả tên người dùng Kaggle và mã thông báo API Kaggle. Bạn phải có tài khoản Kaggle và yêu cầu quyền truy cập vào các mô hình Gemma thì mới có thể tải các mô hình này xuống. Đối với dự án này, bạn sẽ thêm Tên người dùng Kaggle và mã thông báo Kaggle API vào 2 tệp .env. Các tệp này sẽ được ứng dụng web và chương trình điều chỉnh đọc tương ứng.
Cách thiết lập biến môi trường:
- Lấy tên người dùng và khoá mã thông báo của bạn trên Kaggle bằng cách làm theo hướng dẫn trong tài liệu của Kaggle.
- Truy cập vào mô hình Gemma bằng cách làm theo hướng dẫn trong phần Truy cập vào Gemma trên trang Thiết lập Gemma.
- Tạo tệp biến môi trường cho dự án bằng cách tạo tệp văn bản
.envtại mỗi vị trí sau đây trong bản sao của dự án:email-processing-webapp/.env model-tuning/.env
Sau khi tạo tệp văn bản
.env, hãy thêm các chế độ cài đặt sau vào cả hai tệp:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Chạy và kiểm thử ứng dụng
Sau khi hoàn tất quá trình cài đặt và định cấu hình dự án, hãy chạy ứng dụng web để xác nhận rằng bạn đã định cấu hình đúng. Bạn nên thực hiện việc này như một bước kiểm tra cơ bản trước khi chỉnh sửa dự án để sử dụng cho riêng mình.
Cách chạy và kiểm thử dự án:
Trong cửa sổ dòng lệnh, hãy chuyển đến thư mục
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Chạy ứng dụng bằng tập lệnh
run_app:./run_app.shSau khi khởi động ứng dụng web, mã chương trình sẽ liệt kê một URL mà bạn có thể duyệt xem và kiểm thử. Thông thường, địa chỉ này là:
http://127.0.0.1:5000/Trong giao diện web, hãy nhấn vào nút Nhận dữ liệu bên dưới trường nhập liệu đầu tiên để tạo phản hồi từ mô hình.
Phản hồi đầu tiên của mô hình sau khi bạn chạy ứng dụng sẽ mất nhiều thời gian hơn vì mô hình phải hoàn tất các bước khởi chạy trong lần chạy đầu tiên. Các yêu cầu tiếp theo về câu lệnh và nội dung được tạo trên một ứng dụng web đang chạy sẽ hoàn tất trong thời gian ngắn hơn.
Mở rộng ứng dụng
Sau khi chạy ứng dụng, bạn có thể mở rộng ứng dụng bằng cách sửa đổi giao diện người dùng và logic nghiệp vụ để ứng dụng hoạt động cho những tác vụ phù hợp với bạn hoặc doanh nghiệp của bạn. Bạn cũng có thể sửa đổi hành vi của mô hình Gemma bằng mã ứng dụng bằng cách thay đổi các thành phần của câu lệnh mà ứng dụng gửi đến mô hình AI tạo sinh.
Ứng dụng cung cấp hướng dẫn cho mô hình cùng với dữ liệu đầu vào từ người dùng, một câu lệnh hoàn chỉnh của mô hình. Bạn có thể sửa đổi các chỉ dẫn này để thay đổi hành vi của mô hình, chẳng hạn như chỉ định tên của các tham số và cấu trúc của JSON cần tạo. Một cách đơn giản hơn để thay đổi hành vi của mô hình là cung cấp thêm hướng dẫn hoặc chỉ dẫn cho phản hồi của mô hình, chẳng hạn như chỉ định rằng các câu trả lời được tạo không được có định dạng Markdown.
Cách sửa đổi hướng dẫn cho câu lệnh:
- Trong dự án phát triển, hãy mở tệp mã
business-email-assistant/email-processing-webapp/app.py. Trong mã
app.py, hãy thêm các chỉ dẫn bổ sung vào hàmget_prompt()::def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
Ví dụ này thêm cụm từ "không có định dạng giảm giá bổ sung" vào hướng dẫn.
Việc cung cấp thêm hướng dẫn cho câu lệnh có thể ảnh hưởng mạnh mẽ đến kết quả được tạo và tốn ít công sức hơn đáng kể để triển khai. Trước tiên, bạn nên thử phương thức này để xem liệu bạn có thể nhận được hành vi mong muốn từ mô hình hay không. Tuy nhiên, việc sử dụng chỉ dẫn trong câu lệnh để sửa đổi hành vi của một mô hình Gemma có những giới hạn nhất định. Cụ thể, giới hạn mã thông báo đầu vào tổng thể của mô hình (8.192 mã thông báo đối với Gemma 2) yêu cầu bạn cân bằng hướng dẫn chi tiết trong câu lệnh với kích thước của dữ liệu mới mà bạn cung cấp để không vượt quá giới hạn đó.
Điều chỉnh mô hình
Tinh chỉnh mô hình Gemma là cách nên dùng để mô hình này phản hồi đáng tin cậy hơn cho các tác vụ cụ thể. Cụ thể, nếu muốn mô hình tạo JSON có cấu trúc cụ thể, bao gồm cả các tham số được đặt tên cụ thể, bạn nên cân nhắc điều chỉnh mô hình cho hành vi đó. Tuỳ thuộc vào nhiệm vụ mà bạn muốn mô hình hoàn thành, bạn có thể đạt được chức năng cơ bản với 10 đến 20 ví dụ. Phần này của hướng dẫn giải thích cách thiết lập và chạy quy trình tinh chỉnh trên một mô hình Gemma cho một tác vụ cụ thể.
Các hướng dẫn sau đây giải thích cách thực hiện thao tác tinh chỉnh trên môi trường máy ảo. Tuy nhiên, bạn cũng có thể thực hiện thao tác tinh chỉnh này bằng sổ tay Colab được liên kết cho dự án này.
Yêu cầu về phần cứng
Các yêu cầu về điện toán để tinh chỉnh giống với yêu cầu về phần cứng đối với phần còn lại của dự án. Bạn có thể chạy thao tác điều chỉnh trong môi trường Colab với thời gian chạy GPU T4 nếu bạn giới hạn số lượng mã thông báo đầu vào ở mức 256 và kích thước lô ở mức 1.
Chuẩn bị dữ liệu
Trước khi bắt đầu tinh chỉnh một mô hình Gemma, bạn phải chuẩn bị dữ liệu để tinh chỉnh. Khi tinh chỉnh một mô hình cho một nhiệm vụ cụ thể, bạn cần có một bộ ví dụ về yêu cầu và phản hồi. Các ví dụ này phải cho thấy văn bản yêu cầu mà không có bất kỳ hướng dẫn nào và văn bản phản hồi dự kiến. Để bắt đầu, bạn nên chuẩn bị một tập dữ liệu có khoảng 10 ví dụ. Những ví dụ này phải thể hiện đầy đủ các loại yêu cầu và câu trả lời lý tưởng. Đảm bảo rằng các yêu cầu và câu trả lời không lặp lại, vì điều đó có thể khiến câu trả lời của mô hình lặp lại và không điều chỉnh phù hợp với các biến thể trong yêu cầu. Nếu bạn đang điều chỉnh mô hình để tạo ra một định dạng dữ liệu có cấu trúc, hãy đảm bảo rằng tất cả các phản hồi được cung cấp đều tuân thủ nghiêm ngặt định dạng đầu ra dữ liệu mà bạn muốn. Bảng sau đây cho thấy một số bản ghi mẫu trong tập dữ liệu của ví dụ về mã này:
| Yêu cầu | Phản hồi |
|---|---|
| Xin chào Indian Bakery Central,\nBạn có 10 chiếc penda và 30 chiếc bundi ladoo không? Ngoài ra, bạn có bán bánh có hương vị sô cô la và kem vani không? Tôi đang tìm kích thước 6 inch | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| Tôi thấy doanh nghiệp của bạn trên Google Maps. Bạn có bán bánh jalebi và bánh gulab jamun không? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
Bảng 1. Danh sách một phần của tập dữ liệu điều chỉnh cho trình trích xuất dữ liệu email của tiệm bánh.
Định dạng và tải dữ liệu
Bạn có thể lưu trữ dữ liệu điều chỉnh ở bất kỳ định dạng nào thuận tiện, bao gồm cả bản ghi cơ sở dữ liệu, tệp JSON, CSV hoặc tệp văn bản thuần tuý, miễn là bạn có phương tiện để truy xuất các bản ghi bằng mã Python. Dự án này đọc các tệp JSON từ thư mục data vào một mảng các đối tượng từ điển.
Trong chương trình điều chỉnh này, tập dữ liệu điều chỉnh được tải trong mô-đun model-tuning/main.py bằng hàm prepare_tuning_dataset():
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
Như đã đề cập trước đó, bạn có thể lưu trữ tập dữ liệu ở định dạng thuận tiện, miễn là bạn có thể truy xuất các yêu cầu có phản hồi liên quan và tập hợp chúng thành một chuỗi văn bản được dùng làm bản ghi điều chỉnh.
Tập hợp các bản ghi điều chỉnh
Đối với quy trình điều chỉnh thực tế, chương trình sẽ tập hợp từng yêu cầu và phản hồi thành một chuỗi duy nhất có hướng dẫn về câu lệnh và nội dung của phản hồi. Sau đó, chương trình điều chỉnh sẽ mã hoá chuỗi để mô hình sử dụng. Bạn có thể xem mã để lắp ráp một bản ghi điều chỉnh trong hàm prepare_tuning_dataset() của mô-đun model-tuning/main.py như sau:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
Hàm này lấy dữ liệu làm đầu vào và định dạng dữ liệu đó bằng cách thêm một dấu ngắt dòng giữa chỉ dẫn và phản hồi.
Tạo trọng số mô hình
Sau khi có dữ liệu điều chỉnh và tải dữ liệu đó, bạn có thể chạy chương trình điều chỉnh. Quy trình điều chỉnh cho ứng dụng mẫu này sử dụng thư viện Keras NLP để điều chỉnh mô hình bằng kỹ thuật Thích ứng thứ hạng thấp (LoRA) nhằm tạo ra các trọng số mô hình mới. So với việc tinh chỉnh độ chính xác đầy đủ, việc sử dụng LoRA tiết kiệm bộ nhớ hơn đáng kể vì nó xấp xỉ các thay đổi đối với trọng số mô hình. Sau đó, bạn có thể phủ các trọng số ước chừng này lên các trọng số mô hình hiện có để thay đổi hành vi của mô hình.
Để thực hiện lượt chạy điều chỉnh và tính toán trọng số mới:
Trong cửa sổ dòng lệnh, hãy chuyển đến thư mục
model-tuning/.cd business-email-assistant/model-tuning/Chạy quy trình điều chỉnh bằng tập lệnh
tune_model:./tune_model.sh
Quá trình điều chỉnh mất vài phút, tuỳ thuộc vào tài nguyên điện toán mà bạn có. Khi hoàn tất thành công, chương trình điều chỉnh sẽ ghi các tệp trọng số *.h5 mới vào thư mục model-tuning/weights theo định dạng sau:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
Khắc phục sự cố
Nếu quá trình điều chỉnh không hoàn tất thành công, thì có thể là do một trong hai lý do sau:
- Hết bộ nhớ hoặc hết tài nguyên: Những lỗi này xảy ra khi quá trình điều chỉnh yêu cầu bộ nhớ vượt quá bộ nhớ GPU hoặc bộ nhớ CPU hiện có. Đảm bảo bạn không chạy ứng dụng web trong khi quá trình điều chỉnh đang diễn ra. Nếu bạn đang điều chỉnh trên một thiết bị có bộ nhớ GPU 16 GB, hãy đảm bảo bạn đã đặt
token_limitthành 256 vàbatch_sizethành 1. - Chưa cài đặt trình điều khiển GPU hoặc trình điều khiển GPU không tương thích với JAX: Quá trình điều chỉnh yêu cầu thiết bị tính toán phải cài đặt trình điều khiển phần cứng tương thích với phiên bản thư viện JAX. Để biết thêm thông tin chi tiết, hãy xem tài liệu về cách cài đặt JAX.
Triển khai mô hình đã điều chỉnh
Quá trình điều chỉnh tạo ra nhiều trọng số dựa trên dữ liệu điều chỉnh và tổng số các giai đoạn được đặt trong ứng dụng điều chỉnh. Theo mặc định, chương trình điều chỉnh sẽ tạo 3 tệp trọng số mô hình, mỗi tệp cho một giai đoạn điều chỉnh. Mỗi giai đoạn tinh chỉnh liên tiếp tạo ra các trọng số tái tạo chính xác hơn kết quả của dữ liệu tinh chỉnh. Bạn có thể xem tỷ lệ chính xác cho từng giai đoạn trong đầu ra của quy trình điều chỉnh trên thiết bị đầu cuối, như sau:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
Mặc dù bạn muốn tỷ lệ chính xác tương đối cao, khoảng 0,80, nhưng bạn không muốn tỷ lệ này quá cao hoặc rất gần với 1,00, vì điều đó có nghĩa là các trọng số đã gần như khớp quá mức dữ liệu điều chỉnh. Khi đó, mô hình sẽ không hoạt động hiệu quả đối với những yêu cầu khác biệt đáng kể so với các ví dụ điều chỉnh. Theo mặc định, tập lệnh triển khai sẽ chọn các trọng số của kỷ nguyên 3, thường có tỷ lệ chính xác khoảng 0,80.
Cách triển khai các trọng số đã tạo cho ứng dụng web:
Trong cửa sổ dòng lệnh, hãy chuyển đến thư mục
model-tuning:cd business-email-assistant/model-tuning/Chạy quy trình điều chỉnh bằng tập lệnh
deploy_weights:./deploy_weights.sh
Sau khi chạy tập lệnh này, bạn sẽ thấy một tệp *.h5 mới trong thư mục email-processing-webapp/weights/.
Thử nghiệm mô hình mới
Sau khi triển khai các trọng số mới cho ứng dụng, đã đến lúc bạn dùng thử mô hình mới được điều chỉnh. Bạn có thể thực hiện việc này bằng cách chạy lại ứng dụng web và tạo một phản hồi.
Cách chạy và kiểm thử dự án:
Trong cửa sổ dòng lệnh, hãy chuyển đến thư mục
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Chạy ứng dụng bằng tập lệnh
run_app:./run_app.shSau khi khởi động ứng dụng web, mã chương trình sẽ liệt kê một URL mà bạn có thể duyệt xem và kiểm thử, thường thì địa chỉ này là:
http://127.0.0.1:5000/Trong giao diện web, hãy nhấn vào nút Nhận dữ liệu bên dưới trường nhập liệu đầu tiên để tạo phản hồi từ mô hình.
Giờ đây, bạn đã tinh chỉnh và triển khai một mô hình Gemma trong một ứng dụng! Thử nghiệm với ứng dụng và cố gắng xác định giới hạn khả năng tạo của mô hình đã tinh chỉnh cho nhiệm vụ của bạn. Nếu bạn thấy những trường hợp mà mô hình không hoạt động hiệu quả, hãy cân nhắc thêm một số yêu cầu đó vào danh sách dữ liệu ví dụ để điều chỉnh bằng cách thêm yêu cầu và cung cấp câu trả lời lý tưởng. Sau đó, hãy chạy lại quy trình điều chỉnh, triển khai lại các trọng số mới và kiểm thử đầu ra.
Tài nguyên khác
Để biết thêm thông tin về dự án này, hãy xem kho lưu trữ mã Gemma Cookbook. Nếu bạn cần trợ giúp xây dựng ứng dụng hoặc đang muốn cộng tác với các nhà phát triển khác, hãy truy cập vào máy chủ Discord của Cộng đồng nhà phát triển Google. Để xem thêm các dự án Build with Google AI, hãy xem danh sách phát video.