
處理客戶詢問 (包括電子郵件) 是許多企業的必要工作,但這項工作很快就會讓人感到壓力。只要稍加努力,Gemma 等人工智慧 (AI) 模型就能協助您輕鬆完成這項工作。
每間企業處理電子郵件等查詢的方式略有不同,因此請務必根據貴公司的需求調整生成式 AI 等技術。這個專案要解決的具體問題是:從傳送給麵包店的電子郵件中擷取訂單資訊,並轉換為結構化資料,以便快速新增至訂單處理系統。提供 10 到 20 個查詢範例和所需輸出內容,即可調整 Gemma 模型來處理客戶的電子郵件、協助您快速回覆,以及與現有業務系統整合。這個專案是 AI 應用程式模式,您可以擴充及調整,為貴商家運用 Gemma 模型創造價值。
如要觀看專案的影片總覽,以及瞭解如何擴充專案 (包括建構專案人員的洞察資料),請參閱「使用 Google AI 建構:商務電子郵件 AI 助理」影片。您也可以在 Gemma Cookbook 程式碼存放區中查看這個專案的程式碼。如要延長專案期限,請按照下列指示操作。
總覽
本教學課程將逐步說明如何設定、執行及擴充以 Gemma、Python 和 Flask 建構的商務電子郵件助理應用程式。這個專案提供基本網頁使用者介面,您可以視需要修改。這項應用程式的用途是從客戶電子郵件中擷取資料,並以虛構麵包店的結構呈現。您可以使用這個應用程式模式,處理任何需要文字輸入和文字輸出的業務工作。
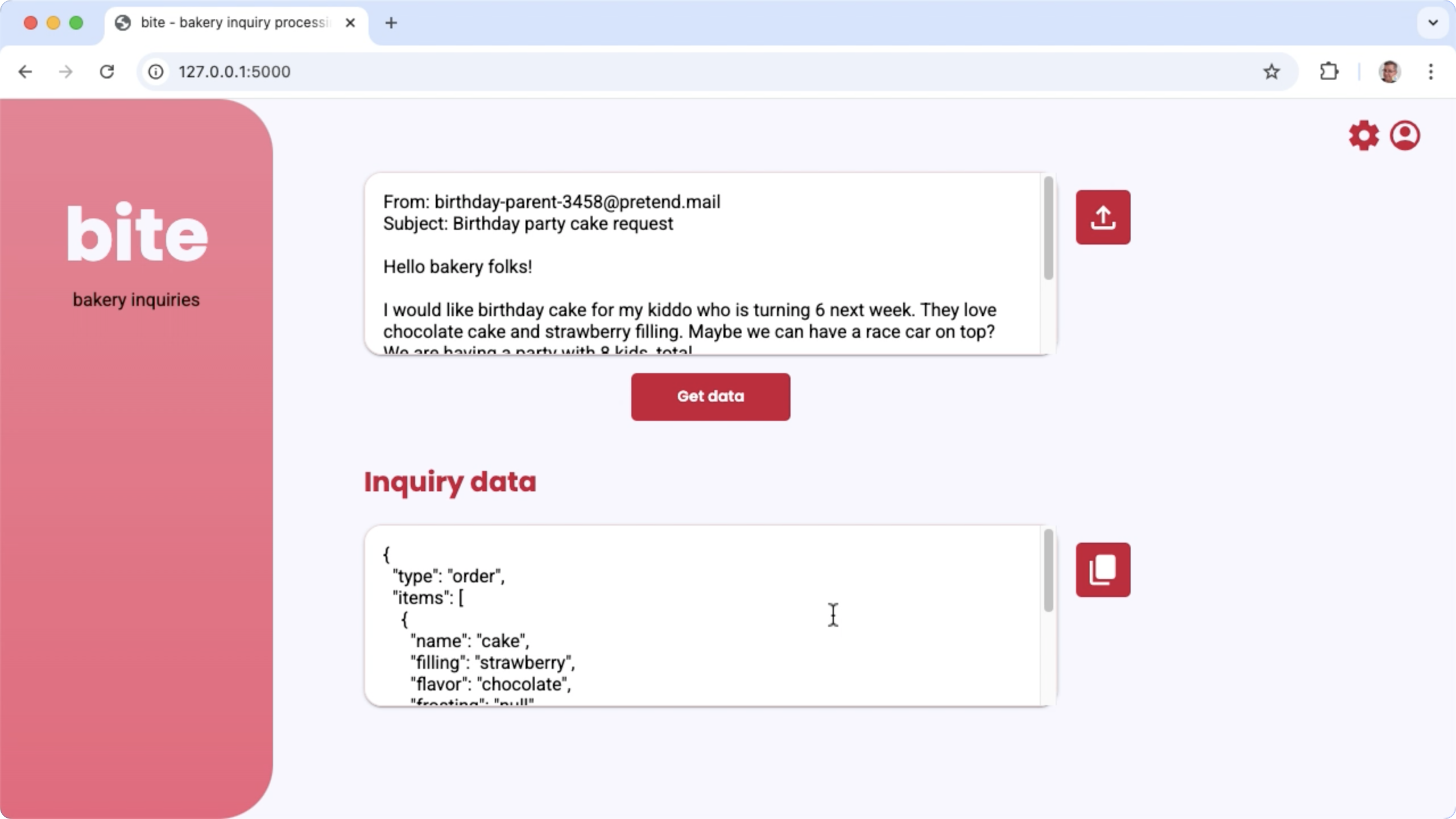
圖 1. 專案使用者介面,用於處理麵包店的電子郵件查詢
硬體需求
請在具備圖形處理單元 (GPU) 或 Tensor 處理單元 (TPU) 的電腦上執行這項調整程序,並確保 GPU 或 TPU 記憶體充足,可容納現有模型和調整資料。如要在這個專案中執行微調設定,您需要約 16 GB 的 GPU 記憶體、約略等量的一般 RAM,以及至少 50 GB 的磁碟空間。
您可以使用 Colab 環境搭配 T4 GPU 執行階段,完成本教學課程的 Gemma 模型微調部分。如果您是在 Google Cloud VM 執行個體上建構這個專案,請按照下列規定設定執行個體:
- GPU 硬體:執行這個專案需要 NVIDIA T4 (建議使用 NVIDIA L4 以上版本)
- 作業系統:選擇「Linux 上的深度學習」選項,具體來說,就是預先安裝 GPU 軟體驅動程式的「Deep Learning VM with CUDA 12.3 M124」。
- 開機磁碟大小:至少佈建 50 GB 的磁碟空間,用於存放資料、模型和支援軟體。
專案設定
這些操作說明會引導您準備好這個專案,以利開發和測試。一般設定步驟包括安裝必要軟體、從程式碼存放區複製專案、設定幾個環境變數、安裝 Python 程式庫,以及測試網頁應用程式。
安裝及設定
這個專案使用 Python 3 和虛擬環境 (venv) 管理套件及執行應用程式。以下安裝說明適用於 Linux 主機。
如要安裝必要軟體,請按照下列步驟操作:
安裝 Python 3 和 Python 適用的
venv虛擬環境套件:sudo apt update sudo apt install git pip python3-venv
複製專案
將專案程式碼下載到開發電腦。您需要 git 原始碼控管軟體,才能擷取專案原始碼。
如要下載專案程式碼,請按照下列步驟操作:
使用下列指令複製 git 存放區:
git clone https://github.com/google-gemini/gemma-cookbook.git(選用) 設定本機 Git 存放區,使用稀疏簽出,這樣您就只會有專案的檔案:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
安裝 Python 程式庫
啟用 venvPython 虛擬環境
,安裝 Python 程式庫,以便管理 Python 套件和依附元件。請務必先啟用 Python 虛擬環境,再使用 pip 安裝程式安裝 Python 程式庫。如要進一步瞭解如何使用 Python 虛擬環境,請參閱 Python venv 說明文件。
如要安裝 Python 程式庫,請按照下列步驟操作:
在終端機視窗中,前往
business-email-assistant目錄:cd Demos/business-email-assistant/為這個專案設定並啟用 Python 虛擬環境 (venv):
python3 -m venv venv source venv/bin/activate使用
setup_python指令碼,為這個專案安裝必要的 Python 程式庫:./setup_python.sh
設定環境變數
這個專案需要一些環境變數才能執行,包括 Kaggle 使用者名稱和 Kaggle API 權杖。您必須擁有 Kaggle 帳戶並要求存取 Gemma 模型,才能下載模型。在本專案中,您會將 Kaggle 使用者名稱和 Kaggle API 權杖新增至兩個 .env 檔案,分別由網頁應用程式和微調程式讀取。
如要設定環境變數,請執行下列操作:
- 按照 Kaggle 說明文件中的指示,取得 Kaggle 使用者名稱和權杖金鑰。
- 按照「Gemma 設定」頁面的「取得 Gemma 存取權」操作說明,取得 Gemma 模型存取權。
- 在專案的每個複製位置建立
.env文字檔案,為專案建立環境變數檔案:email-processing-webapp/.env model-tuning/.env
建立
.env文字檔後,請在兩個檔案中新增下列設定:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
執行及測試應用程式
完成專案的安裝和設定後,請執行網頁應用程式,確認設定正確無誤。建議您在編輯專案供自己使用前,先進行這項基準檢查。
如要執行及測試專案,請按照下列步驟操作:
在終端機視窗中,前往
email-processing-webapp目錄:cd business-email-assistant/email-processing-webapp/使用
run_app指令碼執行應用程式:./run_app.sh啟動網頁應用程式後,程式碼會列出可供瀏覽及測試的網址。這個地址通常是:
http://127.0.0.1:5000/在網頁介面中,按下第一個輸入欄位下方的「取得資料」按鈕,即可生成模型回覆。
執行應用程式後,模型需要完成初始化步驟,才能生成第一個回覆,因此所需時間較長。在已執行的網路應用程式上,後續的提示要求和生成作業完成時間會縮短。
擴展應用程式
應用程式執行後,您可以修改使用者介面和商業邏輯,擴充應用程式功能,讓應用程式處理與您或貴商家相關的工作。您也可以變更應用程式傳送至生成式 AI 模型的提示元件,藉此透過應用程式碼修改 Gemma 模型的行為。
應用程式會向模型提供指令,以及使用者輸入的資料,做為模型的完整提示。您可以修改這些指令來變更模型的行為,例如指定要產生的 JSON 參數名稱和結構。如要變更模型行為,更簡單的方法是為模型回覆提供額外指示或指引,例如指定生成的回覆不得包含任何 Markdown 格式。
如要修改提示詞指令,請按照下列步驟操作:
- 在開發專案中,開啟
business-email-assistant/email-processing-webapp/app.py程式碼檔案。 在
app.py程式碼中,將新增的指令加入get_prompt():函式:def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
這個範例會在指令中加入「with no additional markdown formatting」片語。
提供額外的提示指令可大幅影響生成的輸出內容,且實作起來輕鬆許多。建議您先嘗試這個方法,看看是否能從模型取得所需行為。不過,使用提示指令修改 Gemma 模型行為有其限制。具體來說,模型的整體輸入權杖限制 (Gemma 2 為 8,192 個權杖) 要求您在詳細提示指令與提供的新資料大小之間取得平衡,確保不超過該限制。
調整模型
建議您微調 Gemma 模型,讓模型更可靠地回應特定工作。具體來說,如果希望模型生成特定結構的 JSON (包括特定名稱的參數),請考慮調整模型以符合這類行為。視模型要完成的工作而定,您可以使用 10 到 20 個範例,達到基本功能。本教學課程的這一節說明如何設定及執行 Gemma 模型微調作業,以完成特定工作。
以下說明如何在 VM 環境中執行微調作業,但您也可以使用這個專案的相關 Colab 筆記本執行微調作業。
硬體需求
微調的運算需求與專案其餘部分的硬體需求相同。如果將輸入權杖限制為 256 個,批次大小限制為 1,您可以在 Colab 環境中,使用 T4 GPU 執行階段執行微調作業。
準備資料
開始調整 Gemma 模型之前,您必須先準備調整資料。如要針對特定工作調整模型,您需要一組要求和回應範例。這些範例應顯示要求文字,不含任何指令,以及預期的回覆文字。首先,請準備約 10 個範例的資料集。這些範例應代表各種要求和理想的回應。請確保要求和回覆內容不會重複,否則模型可能會重複回覆,且無法適當調整要求變化。如果調整模型,讓模型產生結構化資料格式,請確保所有提供的回覆都嚴格遵守您想要的資料輸出格式。下表顯示這個程式碼範例資料集中的幾筆範例記錄:
| 要求 | 回應 |
|---|---|
| Indian Bakery Central 你好,\n 請問你手邊有 10 個 pendas 和 30 個 bundi ladoos 嗎?另外,你們有販售香草糖霜和巧克力口味的蛋糕嗎?我想找 6 吋的 | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| 我在 Google 地圖上看到你的商家,你們有賣 Jalebi 和 Gulab Jamun 嗎? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
表 1. 麵包店電子郵件資料擷取器的調整用資料集部分清單。
資料格式和載入
您可以將微調資料儲存為任何方便的格式,包括資料庫記錄、JSON 檔案、CSV 或純文字檔案,只要您有辦法使用 Python 程式碼擷取記錄即可。這個專案會將 data 目錄中的 JSON 檔案讀取至字典物件陣列。在本範例微調程式中,微調資料集會使用 prepare_tuning_dataset() 函式載入 model-tuning/main.py 模組:
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
如先前所述,只要能擷取要求和相關聯的回應,並將其組合成文字字串做為微調記錄,您就能以方便的格式儲存資料集。
組合調整記錄
在實際微調過程中,程式會將每個要求和回應組合成單一字串,其中包含提示指令和回應內容。微調程式接著會將字串權杖化,供模型使用。您可以在 model-tuning/main.py 模組的 prepare_tuning_dataset() 函式中,查看組裝微調記錄的程式碼,如下所示:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
這個函式會將資料做為輸入內容,並在指令和回覆之間加入換行符,藉此設定資料格式。
產生模型權重
準備好並載入微調資料後,即可執行微調程式。這個範例應用程式的微調程序會使用 Keras NLP 程式庫,透過低秩適應 (LoRA) 技術微調模型,產生新的模型權重。相較於全精度微調,LoRA 會近似於模型權重的變化,因此記憶體效率顯著提升。然後,您可以將這些近似權重疊加到現有模型權重上,藉此變更模型的行為。
如要執行調整作業並計算新權重,請按照下列步驟操作:
在終端機視窗中,前往
model-tuning/目錄。cd business-email-assistant/model-tuning/使用
tune_model指令碼執行微調程序:./tune_model.sh
微調程序需要幾分鐘,實際時間取決於可用的運算資源。完成後,微調程式會在 model-tuning/weights 目錄中寫入新的 *.h5 權重檔案,格式如下:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
疑難排解
如果微調作業未順利完成,可能原因如下:
- 記憶體不足或資源耗盡:當微調程序要求的記憶體超出可用 GPU 記憶體或 CPU 記憶體時,就會發生這類錯誤。請確認微調程序執行時,您並未執行網頁應用程式。如果是在 GPU 記憶體為 16 GB 的裝置上進行微調,請務必將
token_limit設為 256,並將batch_size設為 1。 - 未安裝 GPU 驅動程式或與 JAX 不相容:微調程序需要計算裝置安裝與 JAX 程式庫版本相容的硬體驅動程式。詳情請參閱 JAX 安裝說明文件。
部署經過調整的模型
調整程序會根據調整資料和調整應用程式中設定的訓練週期總數,產生多個權重。根據預設,微調程式會產生 3 個模型權重檔案,每個微調訓練週期各一個。每次連續微調的訓練週期都會產生權重,更準確地重現微調資料的結果。您可以在微調程序的終端機輸出內容中,查看每個訓練週期的準確率,如下所示:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
雖然您希望準確率相對較高 (約 0.80),但也不希望準確率太高或非常接近 1.00,因為這表示權重已接近過度調整的狀態。如果發生這種情況,模型在處理與微調範例差異極大的要求時,效能就會不佳。根據預設,部署指令碼會挑選第 3 個訓練週期的權重,準確率通常約為 0.80。
如要將產生的權重部署至網頁應用程式,請按照下列步驟操作:
在終端機視窗中,前往
model-tuning目錄:cd business-email-assistant/model-tuning/使用
deploy_weights指令碼執行微調程序:./deploy_weights.sh
執行這個指令碼後,您應該會在 email-processing-webapp/weights/ 目錄中看到新的 *.h5 檔案。
測試新模型
將新權重部署至應用程式後,即可試用新調整的模型。方法是重新執行網頁應用程式並產生回覆。
如要執行及測試專案,請按照下列步驟操作:
在終端機視窗中,前往
email-processing-webapp目錄:cd business-email-assistant/email-processing-webapp/使用
run_app指令碼執行應用程式:./run_app.sh啟動網頁應用程式後,程式碼會列出可供瀏覽及測試的網址,通常是以下位址:
http://127.0.0.1:5000/在網頁介面中,按下第一個輸入欄位下方的「取得資料」按鈕,即可生成模型回覆。
您現在已在應用程式中微調及部署 Gemma 模型!試用應用程式,並嘗試判斷微調模型在執行工作時的生成能力極限。如果發現模型在某些情境中表現不佳,請考慮將部分要求新增至微調範例資料清單,方法是新增要求並提供理想的回應。接著重新執行微調程序、重新部署新權重,並測試輸出內容。
其他資源
如要進一步瞭解這個專案,請參閱 Gemma Cookbook 程式碼存放區。如需建構應用程式方面的協助,或想與其他開發人員合作,請前往 Google 開發人員社群 Discord 伺服器。如要查看更多「使用 Google AI 建構」專案,請參閱影片播放清單。