
การจัดการคำถามของลูกค้า รวมถึงอีเมล เป็นส่วนที่จำเป็นในการดำเนินธุรกิจหลายอย่าง แต่ก็อาจสร้างความหนักใจได้อย่างรวดเร็ว โมเดลปัญญาประดิษฐ์ (AI) เช่น Gemma สามารถช่วยให้การทำงานนี้ง่ายขึ้นได้
ธุรกิจแต่ละแห่งจัดการคำถาม เช่น อีเมล แตกต่างกันเล็กน้อย ดังนั้นการปรับเทคโนโลยีอย่าง Generative AI ให้เข้ากับความต้องการของธุรกิจจึงเป็นสิ่งสำคัญ โปรเจ็กต์นี้แก้ปัญหาเฉพาะเจาะจงในการดึงข้อมูลคำสั่งซื้อ จากอีเมลที่ส่งถึงร้านเบเกอรี่ไปเป็น Structured Data เพื่อให้เพิ่มลงในระบบจัดการคำสั่งซื้อได้อย่างรวดเร็ว การใช้ตัวอย่างคำถาม 10-20 รายการและเอาต์พุตที่ต้องการจะช่วยปรับแต่งโมเดล Gemma เพื่อประมวลผลอีเมลจากลูกค้า ช่วยให้คุณตอบกลับได้อย่างรวดเร็ว และผสานรวมกับระบบธุรกิจที่มีอยู่ โปรเจ็กต์นี้สร้างขึ้นเป็นรูปแบบแอปพลิเคชัน AI ที่คุณสามารถขยายและปรับให้เหมาะกับ รับคุณค่าจากโมเดล Gemma สำหรับธุรกิจของคุณ
หากต้องการดูภาพรวมวิดีโอของโปรเจ็กต์และวิธีขยายโปรเจ็กต์ รวมถึงข้อมูลเชิงลึก จากผู้ที่สร้างโปรเจ็กต์นี้ โปรดดู ผู้ช่วย AI สำหรับอีเมลธุรกิจ วิดีโอ "สร้างด้วย Google AI" นอกจากนี้ คุณยังตรวจสอบโค้ดของโปรเจ็กต์นี้ได้ในที่เก็บโค้ดของ Gemma Cookbook หรือจะเริ่มขยายโปรเจ็กต์โดยใช้ วิธีการต่อไปนี้ก็ได้
ภาพรวม
บทแนะนำนี้จะแนะนำวิธีตั้งค่า เรียกใช้ และขยายแอปพลิเคชันผู้ช่วยอีเมลธุรกิจที่สร้างด้วย Gemma, Python และ Flask โปรเจ็กต์ มีอินเทอร์เฟซผู้ใช้บนเว็บพื้นฐานที่คุณสามารถแก้ไขให้เหมาะกับความต้องการได้ แอปพลิเคชันนี้สร้างขึ้นเพื่อดึงข้อมูลจากอีเมลของลูกค้าไปยังโครงสร้าง สำหรับร้านเบเกอรี่สมมติ คุณสามารถใช้รูปแบบแอปพลิเคชันนี้กับงานทางธุรกิจใดก็ได้ ที่ใช้การป้อนข้อความและเอาต์พุตข้อความ
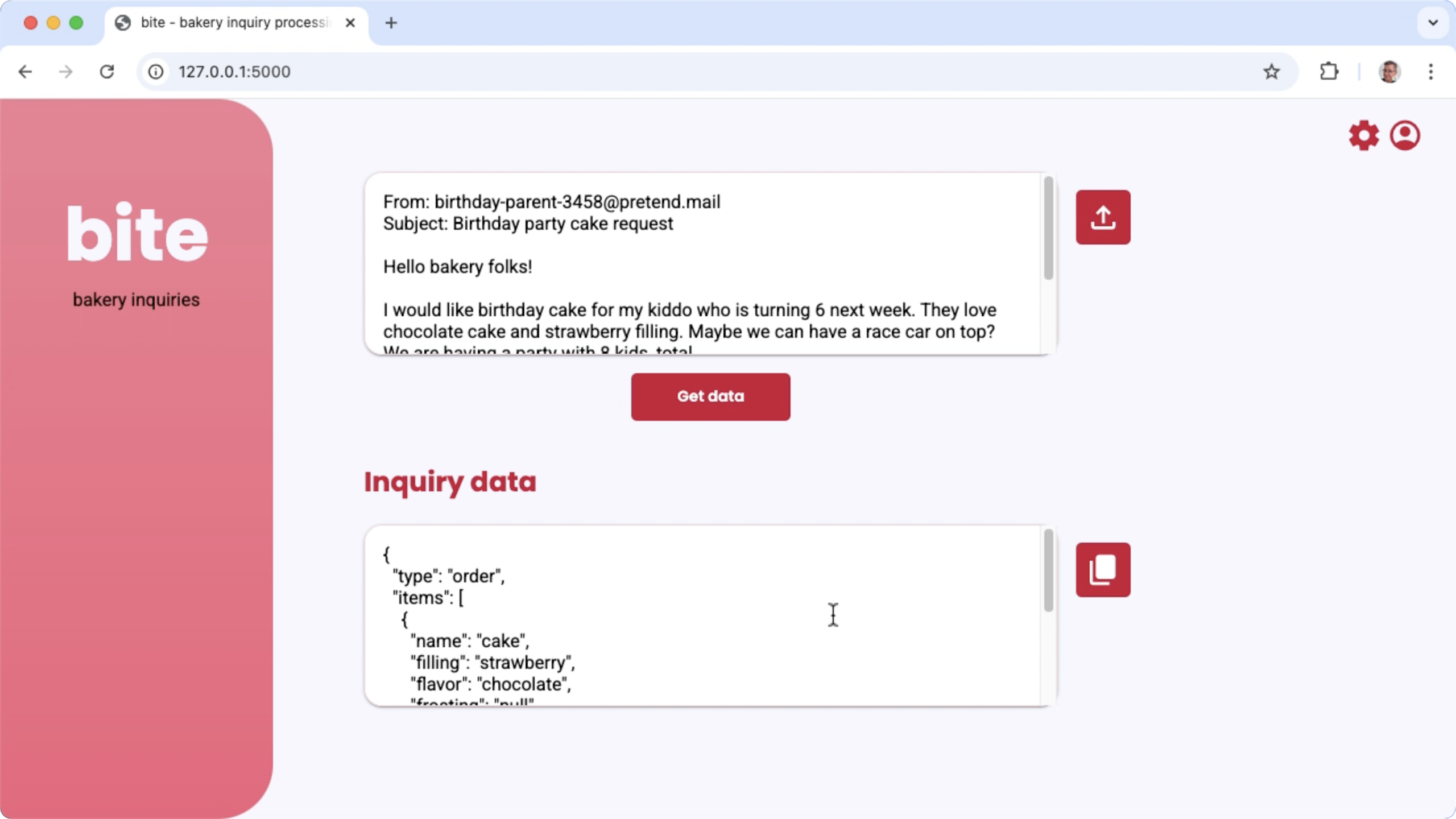
รูปที่ 1 อินเทอร์เฟซผู้ใช้ของโปรเจ็กต์สำหรับการประมวลผลคำถามทางอีเมลของเบเกอรี่
ข้อกำหนดเกี่ยวกับฮาร์ดแวร์
เรียกใช้กระบวนการปรับแต่งนี้ในคอมพิวเตอร์ที่มีหน่วยประมวลผลกราฟิก (GPU) หรือ หน่วยประมวลผล Tensor (TPU) และมีหน่วยความจำ GPU หรือ TPU เพียงพอที่จะเก็บ โมเดลที่มีอยู่ รวมถึงข้อมูลการปรับแต่ง หากต้องการเรียกใช้การกำหนดค่าการปรับแต่งในโปรเจ็กต์นี้ คุณจะต้องมีหน่วยความจำ GPU ประมาณ 16 GB, RAM ปกติประมาณเท่ากัน และพื้นที่ดิสก์อย่างน้อย 50 GB
คุณสามารถเรียกใช้ส่วนการปรับแต่งโมเดล Gemma ของบทแนะนำนี้ได้โดยใช้สภาพแวดล้อม Colab ที่มีรันไทม์ T4 GPU หากคุณสร้างโปรเจ็กต์นี้ในอินสแตนซ์ VM ของ Google Cloud ให้กำหนดค่าอินสแตนซ์ตามข้อกำหนดต่อไปนี้
- ฮาร์ดแวร์ GPU: ต้องใช้ NVIDIA T4 เพื่อเรียกใช้โปรเจ็กต์นี้ (แนะนำให้ใช้ NVIDIA L4 ขึ้นไป)
- ระบบปฏิบัติการ: เลือกตัวเลือกการเรียนรู้เชิงลึกใน Linux โดยเฉพาะ VM สำหรับการเรียนรู้เชิงลึกที่มี CUDA 12.3 M124 พร้อมด้วย โปรแกรมควบคุมซอฟต์แวร์ GPU ที่ติดตั้งไว้ล่วงหน้า
- ขนาดดิสก์บูท: จัดสรรพื้นที่ดิสก์อย่างน้อย 50 GB สำหรับ ข้อมูล โมเดล และซอฟต์แวร์สนับสนุน
การตั้งค่าโปรเจ็กต์
วิธีการเหล่านี้จะแนะนำขั้นตอนการเตรียมโปรเจ็กต์นี้ให้พร้อมสำหรับการพัฒนา และการทดสอบ ขั้นตอนการตั้งค่าทั่วไป ได้แก่ การติดตั้งซอฟต์แวร์ที่จำเป็น การโคลนโปรเจ็กต์จากที่เก็บโค้ด การตั้งค่าตัวแปรสภาพแวดล้อม บางรายการ การติดตั้งไลบรารี Python และการทดสอบเว็บแอปพลิเคชัน
ติดตั้งและกำหนดค่า
โปรเจ็กต์นี้ใช้ Python 3 และสภาพแวดล้อมเสมือน (venv) เพื่อจัดการแพ็กเกจและเรียกใช้แอปพลิเคชัน วิธีการติดตั้งต่อไปนี้มีไว้สำหรับเครื่องโฮสต์ Linux
วิธีติดตั้งซอฟต์แวร์ที่จำเป็น
ติดตั้ง Python 3 และ
venvแพ็กเกจสภาพแวดล้อมเสมือนสำหรับ Python:sudo apt update sudo apt install git pip python3-venv
โคลนโปรเจ็กต์
ดาวน์โหลดโค้ดโปรเจ็กต์ลงในคอมพิวเตอร์ที่ใช้พัฒนา คุณต้องมีซอฟต์แวร์ควบคุมแหล่งที่มา git เพื่อดึงข้อมูล ซอร์สโค้ดของโปรเจ็กต์
วิธีดาวน์โหลดโค้ดโปรเจ็กต์
โคลนที่เก็บ Git โดยใช้คำสั่งต่อไปนี้
git clone https://github.com/google-gemini/gemma-cookbook.gitคุณจะกำหนดค่าที่เก็บ Git ในเครื่องให้ใช้การชำระเงินแบบ Sparse หรือไม่ก็ได้ เพื่อให้มีเฉพาะไฟล์สำหรับโปรเจ็กต์
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
ติดตั้งไลบรารี Python
ติดตั้งไลบรารี Python โดยเปิดใช้งานvenvสภาพแวดล้อมเสมือนของ Python
เพื่อจัดการแพ็กเกจและการอ้างอิงของ Python โปรดเปิดใช้งานสภาพแวดล้อมเสมือนของ Python ก่อนติดตั้งไลบรารี Python ด้วยโปรแกรมติดตั้ง pip
ดูข้อมูลเพิ่มเติมเกี่ยวกับการใช้สภาพแวดล้อมเสมือนของ Python ได้ที่เอกสารประกอบของ Python venv
วิธีติดตั้งไลบรารี Python
ในหน้าต่างเทอร์มินัล ให้ไปที่ไดเรกทอรี
business-email-assistantcd Demos/business-email-assistant/กำหนดค่าและเปิดใช้งานสภาพแวดล้อมเสมือนของ Python (venv) สำหรับโปรเจ็กต์นี้
python3 -m venv venv source venv/bin/activateติดตั้งไลบรารี Python ที่จำเป็นสำหรับโปรเจ็กต์นี้โดยใช้สคริปต์
setup_python./setup_python.sh
ตั้งค่าตัวแปรสภาพแวดล้อม
โปรเจ็กต์นี้ต้องใช้ตัวแปรสภาพแวดล้อม 2-3 ตัวเพื่อเรียกใช้
ซึ่งรวมถึงชื่อผู้ใช้ Kaggle และโทเค็น API ของ Kaggle คุณต้องมีบัญชี Kaggle
และขอสิทธิ์เข้าถึงโมเดล Gemma จึงจะดาวน์โหลดได้ สำหรับโปรเจ็กต์นี้ คุณจะเพิ่มชื่อผู้ใช้ Kaggle และโทเค็น API ของ Kaggle ลงในไฟล์ 2 ไฟล์.env
ซึ่งอ่านโดยเว็บแอปพลิเคชันและโปรแกรมการปรับแต่งตามลำดับ
วิธีตั้งค่าตัวแปรสภาพแวดล้อม
- รับชื่อผู้ใช้ Kaggle และคีย์โทเค็นโดยทำตามวิธีการ ในเอกสารประกอบของ Kaggle
- รับสิทธิ์เข้าถึงโมเดล Gemma โดยทำตามวิธีการรับสิทธิ์เข้าถึง Gemma ในหน้าการตั้งค่า Gemma
- สร้างไฟล์ตัวแปรสภาพแวดล้อมสำหรับโปรเจ็กต์โดยสร้าง
.envไฟล์ข้อความที่แต่ละตำแหน่งต่อไปนี้ในสำเนาของโปรเจ็กต์email-processing-webapp/.env model-tuning/.env
หลังจากสร้าง
.envไฟล์ข้อความแล้ว ให้เพิ่มการตั้งค่าต่อไปนี้ลงในไฟล์ทั้ง 2 ไฟล์KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
เรียกใช้และทดสอบแอปพลิเคชัน
เมื่อติดตั้งและกำหนดค่าโปรเจ็กต์เสร็จแล้ว ให้เรียกใช้ เว็บแอปพลิเคชันเพื่อยืนยันว่าคุณได้กำหนดค่าอย่างถูกต้อง คุณควร ดำเนินการนี้เป็นการตรวจสอบพื้นฐานก่อนแก้ไขโปรเจ็กต์เพื่อใช้งานเอง
วิธีเรียกใช้และทดสอบโปรเจ็กต์
ในหน้าต่างเทอร์มินัล ให้ไปที่ไดเรกทอรี
email-processing-webappcd business-email-assistant/email-processing-webapp/เรียกใช้แอปพลิเคชันโดยใช้สคริปต์
run_app./run_app.shหลังจากเริ่มเว็บแอปพลิเคชันแล้ว โค้ดโปรแกรมจะแสดง URL ที่คุณสามารถเรียกดูและทดสอบได้ โดยปกติแล้วที่อยู่นี้คือ
http://127.0.0.1:5000/ในอินเทอร์เฟซเว็บ ให้กดปุ่มรับข้อมูลใต้ช่องป้อนข้อมูลแรก เพื่อสร้างคำตอบจากโมเดล
คำตอบแรกจากโมเดลหลังจากที่คุณเรียกใช้แอปพลิเคชันจะใช้เวลานานกว่า เนื่องจากต้องทำขั้นตอนการเริ่มต้นให้เสร็จสมบูรณ์ในการเรียกใช้รุ่นแรก คำขอพรอมต์และการสร้างในเว็บแอปพลิเคชันที่ทำงานอยู่แล้วจะใช้เวลาน้อยลง
ขยายแอปพลิเคชัน
เมื่อแอปพลิเคชันทำงานแล้ว คุณสามารถขยายแอปพลิเคชันได้โดยการแก้ไขอินเทอร์เฟซผู้ใช้และตรรกะทางธุรกิจเพื่อให้ทำงานกับงานที่เกี่ยวข้องกับคุณหรือธุรกิจของคุณ นอกจากนี้ คุณยังแก้ไขลักษณะการทำงานของโมเดล Gemma ได้โดยใช้โค้ดแอปพลิเคชันด้วยการเปลี่ยนคอมโพเนนต์ของพรอมต์ที่แอปส่งไปยังโมเดล Generative AI
แอปพลิเคชันจะให้คำสั่งแก่โมเดลพร้อมกับข้อมูลอินพุต จากผู้ใช้ ซึ่งเป็นพรอมต์ที่สมบูรณ์ของโมเดล คุณสามารถแก้ไขคำสั่งเหล่านี้ เพื่อเปลี่ยนลักษณะการทำงานของโมเดล เช่น การระบุชื่อพารามิเตอร์ และโครงสร้างของ JSON ที่จะสร้าง วิธีที่ง่ายกว่าในการเปลี่ยนลักษณะการทำงานของโมเดลคือการให้คำสั่งหรือคำแนะนำเพิ่มเติมสำหรับการตอบกลับของโมเดล เช่น การระบุว่าคำตอบที่สร้างขึ้นไม่ควรมีการจัดรูปแบบมาร์กดาวน์
วิธีแก้ไขคำสั่งพรอมต์
- ในโปรเจ็กต์การพัฒนา ให้เปิดไฟล์โค้ด
business-email-assistant/email-processing-webapp/app.py ในโค้ด
app.pyให้เพิ่มวิธีการเพิ่มเติมลงในฟังก์ชันget_prompt():ดังนี้def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
ตัวอย่างนี้จะเพิ่มวลี "โดยไม่มีการจัดรูปแบบมาร์กดาวน์เพิ่มเติม" ลงใน คำสั่ง
การให้คำสั่งพรอมต์เพิ่มเติมสามารถส่งผลต่อเอาต์พุตที่สร้างขึ้นอย่างมาก และใช้ความพยายามในการใช้งานน้อยกว่าอย่างเห็นได้ชัด คุณควรลองใช้วิธีนี้ก่อนเพื่อดูว่าโมเดลแสดงพฤติกรรมที่คุณต้องการหรือไม่ อย่างไรก็ตาม การใช้คำสั่งพรอมต์เพื่อแก้ไขลักษณะการทำงานของโมเดล Gemma มีข้อจำกัด โดยเฉพาะอย่างยิ่ง ขีดจํากัดโทเค็นอินพุตโดยรวมของโมเดล ซึ่งมีโทเค็น 8,192 รายการสําหรับ Gemma 2 กําหนดให้คุณต้องปรับสมดุลคําสั่งพรอมต์แบบละเอียดกับขนาดของข้อมูลใหม่ที่คุณระบุเพื่อให้มีขนาดไม่เกินขีดจํากัดดังกล่าว
ปรับแต่งโมเดล
การปรับแต่งโมเดล Gemma เป็นวิธีที่แนะนําเพื่อให้โมเดลตอบสนองต่องานที่เฉพาะเจาะจงได้อย่างน่าเชื่อถือมากขึ้น โดยเฉพาะอย่างยิ่ง หากต้องการให้โมเดล สร้าง JSON ที่มีโครงสร้างเฉพาะ รวมถึงพารามิเตอร์ที่มีชื่อเฉพาะ คุณควรพิจารณาปรับแต่งโมเดลเพื่อให้มีลักษณะการทำงานดังกล่าว คุณสามารถสร้างฟังก์ชันพื้นฐานได้ด้วยตัวอย่าง 10-20 รายการ ทั้งนี้ขึ้นอยู่กับงานที่คุณต้องการให้โมเดลทำ ส่วนนี้ของบทแนะนำ จะอธิบายวิธีตั้งค่าและเรียกใช้การปรับแต่งโมเดล Gemma สำหรับงานที่เฉพาะเจาะจง
วิธีการต่อไปนี้จะอธิบายวิธีดำเนินการปรับแต่งในสภาพแวดล้อม VM แต่คุณยังดำเนินการปรับแต่งนี้ได้โดยใช้สมุดบันทึก Colab ที่เชื่อมโยง สำหรับโปรเจ็กต์นี้ด้วย
ข้อกำหนดเกี่ยวกับฮาร์ดแวร์
ข้อกำหนดด้านการประมวลผลสำหรับการปรับแต่งนั้นเหมือนกับข้อกำหนดด้านฮาร์ดแวร์สำหรับส่วนที่เหลือของโปรเจ็กต์ คุณสามารถ เรียกใช้การดำเนินการปรับแต่งในสภาพแวดล้อม Colab ด้วยรันไทม์ T4 GPU หาก จำกัดโทเค็นอินพุตไว้ที่ 256 และขนาดกลุ่มไว้ที่ 1
เตรียมข้อมูล
ก่อนเริ่มปรับแต่งโมเดล Gemma คุณต้องเตรียมข้อมูลสำหรับการปรับแต่ง เมื่อปรับแต่งโมเดลสำหรับงานที่เฉพาะเจาะจง คุณจะต้องมีชุดตัวอย่างคำขอและคำตอบ ตัวอย่างเหล่านี้ควรแสดงข้อความคำขอโดยไม่มีวิธีการและข้อความคำตอบที่คาดไว้ ก่อนอื่น คุณควรเตรียมชุดข้อมูลที่มีตัวอย่างประมาณ 10 รายการ ตัวอย่างเหล่านี้ควรแสดงถึงคำขอที่หลากหลาย และคำตอบที่เหมาะสม ตรวจสอบว่าคำขอและคำตอบไม่ซ้ำกัน เนื่องจากอาจทำให้คำตอบของโมเดลซ้ำกันและไม่ปรับให้เข้ากับการเปลี่ยนแปลงในคำขออย่างเหมาะสม หากคุณปรับแต่งโมเดลเพื่อสร้างรูปแบบ Structured Data โปรดตรวจสอบว่าคำตอบทั้งหมดที่ระบุเป็นไปตามรูปแบบเอาต์พุตข้อมูลที่คุณต้องการอย่างเคร่งครัด ตารางต่อไปนี้ แสดงตัวอย่างเรคคอร์ดบางส่วนจากชุดข้อมูลของตัวอย่างโค้ดนี้
| ส่งคำขอ | การตอบกลับ |
|---|---|
| สวัสดี Indian Bakery Central\nคุณมีเพนดา 10 ชิ้นและ บุนดีลาดู 30 ชิ้นไหม นอกจากนี้ คุณยังขายฟรอสติ้งวานิลลาและ เค้กรสช็อกโกแลตด้วยใช่ไหม ฉันกำลังมองหาขนาด 6 นิ้ว | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| ฉันเห็นธุรกิจของคุณใน Google Maps คุณขายเจลาบีและกุหลาบ จามุนไหม | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
ตารางที่ 1 รายการชุดข้อมูลการปรับแต่งบางส่วนสำหรับโปรแกรมแยกข้อมูลอีเมลของเบเกอรี่
รูปแบบข้อมูลและการโหลด
คุณสามารถจัดเก็บข้อมูลการปรับแต่งในรูปแบบใดก็ได้ที่สะดวก รวมถึง
บันทึกฐานข้อมูล, ไฟล์ JSON, CSV หรือไฟล์ข้อความธรรมดา ตราบใดที่คุณมี
วิธีดึงข้อมูลบันทึกด้วยโค้ด Python โปรเจ็กต์นี้อ่านไฟล์ JSON
จากไดเรกทอรี data ลงในอาร์เรย์ของออบเจ็กต์พจนานุกรม
ในโปรแกรมการปรับแต่งตัวอย่างนี้ ระบบจะโหลดชุดข้อมูลการปรับแต่งใน
model-tuning/main.py โมดูลโดยใช้ฟังก์ชัน prepare_tuning_dataset() ดังนี้
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
ดังที่ได้กล่าวไว้ก่อนหน้านี้ คุณสามารถจัดเก็บชุดข้อมูลในรูปแบบที่ สะดวกได้ ตราบใดที่คุณสามารถดึงคำขอพร้อมคำตอบที่เกี่ยวข้อง และประกอบเป็นสตริงข้อความซึ่งใช้เป็นบันทึกการปรับแต่งได้
รวบรวมบันทึกการปรับ
สําหรับกระบวนการปรับแต่งจริง โปรแกรมจะรวบรวมคําขอและการตอบกลับแต่ละรายการ
เป็นสตริงเดียวพร้อมคําสั่งพรอมต์และเนื้อหาของการตอบกลับ
จากนั้นโปรแกรมการปรับแต่งจะแปลงสตริงเป็นโทเค็นเพื่อให้โมเดลนำไปใช้ได้ คุณดูโค้ดสำหรับการรวบรวมบันทึกการปรับแต่งได้ในฟังก์ชันmodel-tuning/main.pyโมดูลprepare_tuning_dataset() ดังนี้
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
ฟังก์ชันนี้จะใช้ข้อมูลเป็นอินพุตและจัดรูปแบบโดยการเพิ่มการขึ้นบรรทัดใหม่ ระหว่างคำสั่งและการตอบกลับ
สร้างน้ำหนักของโมเดล
เมื่อมีข้อมูลการปรับแต่งและโหลดแล้ว คุณจะเรียกใช้โปรแกรมการปรับแต่งได้ กระบวนการปรับแต่งสำหรับแอปพลิเคชันตัวอย่างนี้ใช้ไลบรารี Keras NLP เพื่อปรับแต่งโมเดลด้วยเทคนิค Low Rank Adaptation หรือ LoRA เพื่อสร้างน้ำหนักโมเดลใหม่ การใช้ LoRA จะประหยัดหน่วยความจำมากกว่าการปรับแต่งความแม่นยำแบบเต็มอย่างมาก เนื่องจากเป็นการประมาณการเปลี่ยนแปลงน้ำหนักของโมเดล จากนั้นคุณสามารถซ้อนทับน้ำหนักโดยประมาณเหล่านี้กับน้ำหนักของโมเดลที่มีอยู่เพื่อเปลี่ยนลักษณะการทำงานของโมเดลได้
วิธีเรียกใช้การปรับแต่งและคำนวณน้ำหนักใหม่
ในหน้าต่างเทอร์มินัล ให้ไปที่ไดเรกทอรี
model-tuning/cd business-email-assistant/model-tuning/เรียกใช้กระบวนการปรับแต่งโดยใช้สคริปต์
tune_model./tune_model.sh
กระบวนการปรับแต่งจะใช้เวลาหลายนาที ขึ้นอยู่กับทรัพยากรการคำนวณที่คุณมี
เมื่อเสร็จสมบูรณ์ โปรแกรมการปรับแต่งจะเขียน*.h5
ไฟล์น้ำหนักใหม่ในไดเรกทอรี model-tuning/weights โดยมีรูปแบบดังนี้
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
การแก้ปัญหา
หากการปรับไม่เสร็จสมบูรณ์ สาเหตุที่เป็นไปได้มี 2 ประการดังนี้
- หน่วยความจำไม่พอหรือทรัพยากรหมด: ข้อผิดพลาดเหล่านี้เกิดขึ้นเมื่อกระบวนการปรับแต่งขอหน่วยความจำที่เกินหน่วยความจำ GPU หรือหน่วยความจำ CPU ที่พร้อมใช้งาน
ตรวจสอบว่าคุณไม่ได้เรียกใช้เว็บแอปพลิเคชันขณะที่กระบวนการปรับแต่ง
ทำงานอยู่ หากคุณกำลังปรับแต่งในอุปกรณ์ที่มีหน่วยความจำ GPU 16 GB
โปรดตรวจสอบว่าคุณได้ตั้งค่า
token_limitเป็น 256 และตั้งค่าbatch_sizeเป็น 1 - ไม่ได้ติดตั้งไดรเวอร์ GPU หรือเข้ากันไม่ได้กับ JAX: กระบวนการปรับแต่ง กำหนดให้อุปกรณ์ประมวลผลต้องติดตั้งไดรเวอร์ฮาร์ดแวร์ที่ เข้ากันได้กับเวอร์ชันของ ไลบรารี JAX ดูรายละเอียดเพิ่มเติมได้ในเอกสารประกอบเกี่ยวกับ การติดตั้ง JAX
ทำให้โมเดลที่ปรับแต่งแล้วใช้งานได้
กระบวนการปรับแต่งจะสร้างน้ำหนักหลายรายการตามข้อมูลการปรับแต่งและ จำนวน Epoch ทั้งหมดที่ตั้งค่าไว้ในแอปพลิเคชันการปรับแต่ง โดยค่าเริ่มต้น โปรแกรมการปรับแต่ง จะสร้างไฟล์น้ำหนักของโมเดล 3 ไฟล์ ไฟล์ละ 1 ยุคการปรับแต่ง แต่ละ Epoch การปรับแต่งที่ต่อเนื่องจะสร้างน้ำหนักที่จำลองผลลัพธ์ของข้อมูลการปรับแต่งได้อย่างแม่นยำยิ่งขึ้น คุณดูอัตราความแม่นยำของแต่ละ Epoch ได้ใน เอาต์พุตของเทอร์มินัลของกระบวนการปรับแต่ง ดังนี้
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
แม้ว่าคุณต้องการให้อัตราความแม่นยำค่อนข้างสูงประมาณ 0.80 แต่คุณไม่ ต้องการให้อัตราสูงเกินไปหรือใกล้เคียง 1.00 มากเกินไป เนื่องจากนั่นหมายความว่า น้ำหนักใกล้เคียงกับการปรับให้เข้ากับข้อมูลการปรับมากเกินไป เมื่อเกิดกรณีดังกล่าว โมเดลจะทำงานได้ไม่ดีกับคำขอที่แตกต่างจาก ตัวอย่างการปรับแต่งอย่างมาก โดยค่าเริ่มต้น สคริปต์การติดตั้งใช้งานจะเลือกน้ำหนักของ Epoch 3 ซึ่งโดยทั่วไปจะมีอัตราความแม่นยำประมาณ 0.80
วิธีติดตั้งใช้งานน้ำหนักที่สร้างขึ้นกับเว็บแอปพลิเคชัน
ในหน้าต่างเทอร์มินัล ให้ไปที่ไดเรกทอรี
model-tuningcd business-email-assistant/model-tuning/เรียกใช้กระบวนการปรับแต่งโดยใช้สคริปต์
deploy_weights./deploy_weights.sh
หลังจากเรียกใช้สคริปต์นี้แล้ว คุณควรเห็นไฟล์ *.h5 ใหม่ในไดเรกทอรี email-processing-webapp/weights/
ทดสอบโมเดลใหม่
เมื่อติดตั้งใช้งานน้ำหนักใหม่กับแอปพลิเคชันแล้ว ก็ถึงเวลาลองใช้โมเดลที่ปรับแต่งใหม่ คุณทำได้โดยเรียกใช้เว็บแอปพลิเคชันอีกครั้งและ สร้างการตอบกลับ
วิธีเรียกใช้และทดสอบโปรเจ็กต์
ในหน้าต่างเทอร์มินัล ให้ไปที่ไดเรกทอรี
email-processing-webappcd business-email-assistant/email-processing-webapp/เรียกใช้แอปพลิเคชันโดยใช้สคริปต์
run_app./run_app.shหลังจากเริ่มแอปพลิเคชันบนเว็บแล้ว โค้ดโปรแกรมจะแสดง URL ที่คุณสามารถเรียกดูและทดสอบได้ โดยปกติแล้วที่อยู่จะเป็นดังนี้
http://127.0.0.1:5000/ในอินเทอร์เฟซเว็บ ให้กดปุ่มรับข้อมูลใต้ช่องป้อนข้อมูลแรก เพื่อสร้างคำตอบจากโมเดล
ตอนนี้คุณได้ปรับแต่งและติดตั้งใช้งานโมเดล Gemma ในแอปพลิเคชันแล้ว ทดลองใช้แอปพลิเคชันและพยายามกำหนดขีดจำกัดของความสามารถในการสร้างของโมเดลที่ปรับแต่งแล้วสำหรับงานของคุณ หากพบสถานการณ์ที่โมเดลทำงานได้ไม่ดี ให้ลองเพิ่มคำขอบางส่วนเหล่านั้นลงในรายการข้อมูลตัวอย่างการปรับแต่งโดยเพิ่มคำขอและระบุคำตอบที่เหมาะสม จากนั้นให้เรียกใช้กระบวนการปรับแต่งอีกครั้ง ปรับใช้เวทใหม่ และทดสอบเอาต์พุต
แหล่งข้อมูลเพิ่มเติม
ดูข้อมูลเพิ่มเติมเกี่ยวกับโปรเจ็กต์นี้ได้ที่ที่เก็บโค้ด Gemma Cookbook หากต้องการความช่วยเหลือในการสร้างแอปพลิเคชันหรือกำลังมองหาการทำงานร่วมกับ นักพัฒนาแอปคนอื่นๆ โปรดดูเซิร์ฟเวอร์ Discord ของชุมชนนักพัฒนาแอป Google ดูโปรเจ็กต์ "สร้างด้วย Google AI" เพิ่มเติมได้ในเพลย์ลิสต์วิดีโอ